




 本文探讨如何增强Transformer在获取相对位置信息的能力,通过分析Self-Attention with Relative Position Representations, Transformer-XL和TENER等工作的改进,指出相对位置编码在Transformer结构中的重要性,并提出在Attention bias计算中加入相对位置信息可以提升模型性能。"
112677057,10296926,成本最小化与利润最大化策略解析,"['经济学', '成本分析', '利润分析']
本文探讨如何增强Transformer在获取相对位置信息的能力,通过分析Self-Attention with Relative Position Representations, Transformer-XL和TENER等工作的改进,指出相对位置编码在Transformer结构中的重要性,并提出在Attention bias计算中加入相对位置信息可以提升模型性能。"
112677057,10296926,成本最小化与利润最大化策略解析,"['经济学', '成本分析', '利润分析']
“原来你还关注了这个专栏”
“这个博主还能敲键盘呀”
没错,时隔半年,终于终于要更新了 🙊
(主要是我太咸鱼了
这次主要讨论一下如何增强 Transformer 结构对获取相对位置信息的能力(即 Relative Position Embedding in Transformer Architecture)。
Background
事实上,Transformer 是一种建立在 RNN 之上的结构,其主要目的是在提升并行能力的基础上保留获取长程依赖的能力。
MultiHeadAtt 获取多种 token 与 token 之间的关联度,FFN 通过一个超高纬的空间来保存 memory。
通过各种 Mask(Regressive 之类的) Transformer 可以做到不泄露信息情况下的并行。
在实际实验中,速度可能会比 LSTM 还快。
为了补救,Transformer 在输入的 Word Embedding 之上,直接叠加了位置编码(可以是 trainable 的,但实验结果显示 train 不 train 效果差不多,在 Vanilla Transformer 中位置编码是 fixed 的)。
但事实上这种 Position Encoder 或者叫做 Position Embedding 在 word embedding 上直接叠加能带来的只有位置的绝对信息
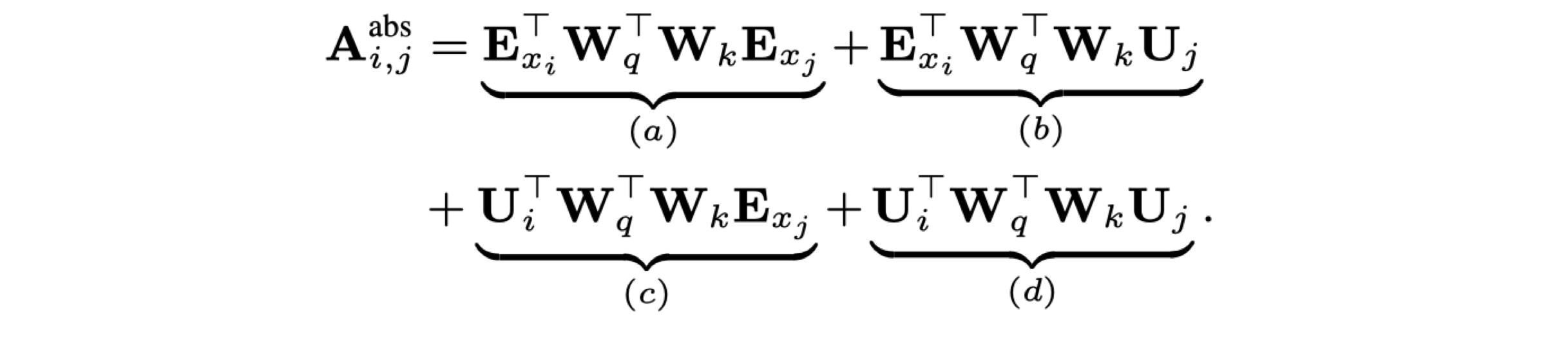
(a) 与位置无关,(b),© 只有绝对位置信息, 而(d)项实际上也不含有相对位置信息。
回顾 PE 的定义,由一组 sin,cos 组成,为了构造一个 d 维的位置编码(与 word embed 相同维度,分母的次方逐渐增大)
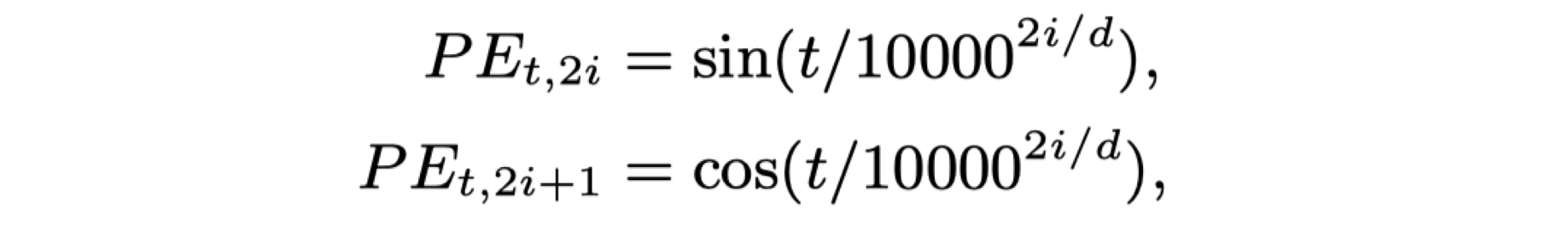
于是可证 P E t + k T P E t PE^T_{t+k}PE_t PEt+kTPEt只与相对距离 t 有关。
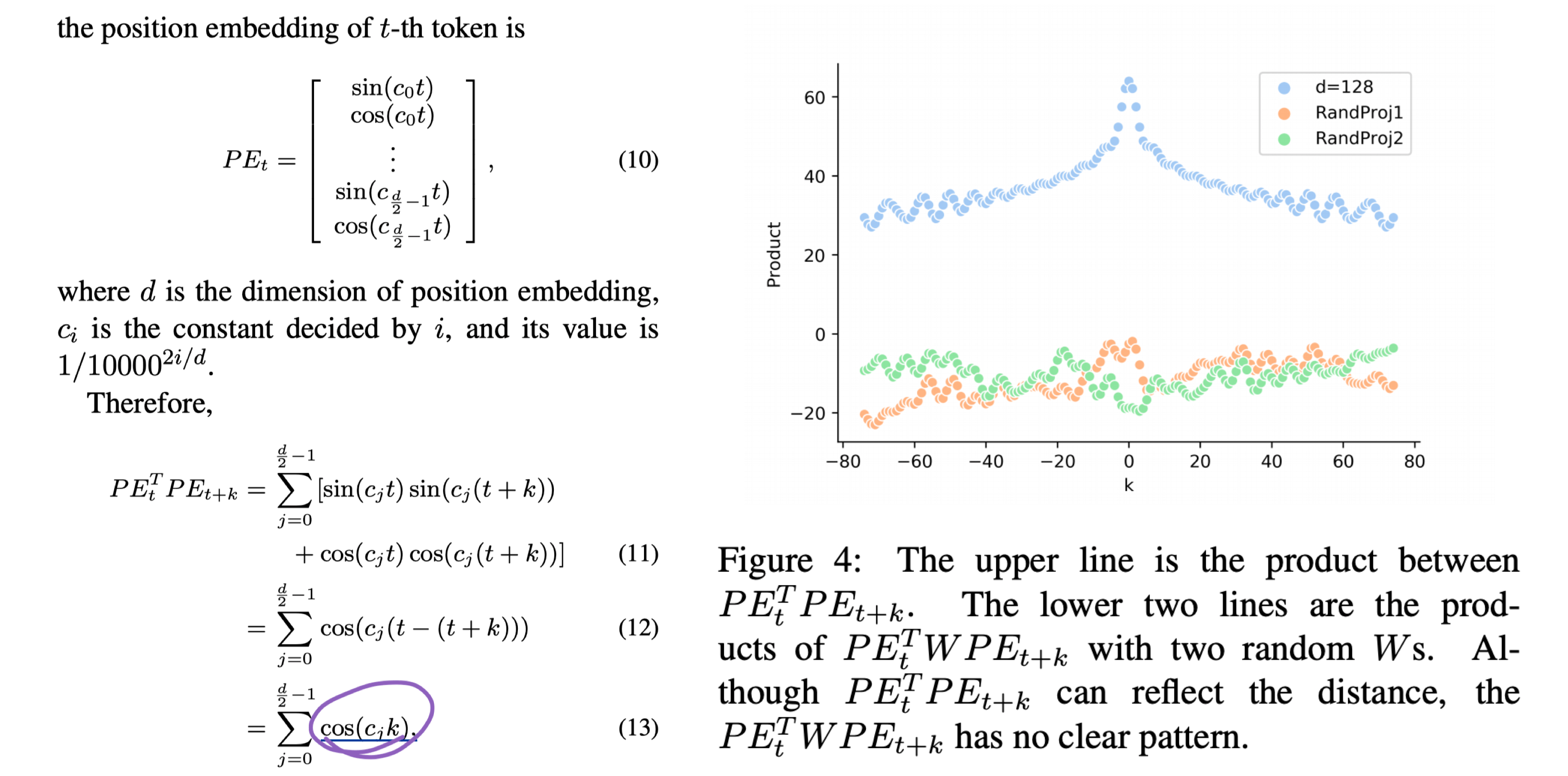
但实际上在 P E t + k T PE^T_{t+k} PEt+kT与 P E t PE_t PEt之间还有两个线性 W 系数的乘积(可等效于一个线性系数)。
由随机初始化 W 之后的 d 项与相对距离 k 之间的关系图可知,W 项的扰动使得原有的 Attention 失去了相对位置之间的信息。
这就使得 Transformer 结构在一些特别依赖句内 token 间相对位置关系的任务效果提升没有那么大。
本文就这个问题,介绍四篇工作。
- NAACL 2018. Self-Attention with Relative Position Representations.
- ACL 2019. Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context.
- -. TENER: Adapting Transformer Encoder for Named Entity Recognition.
- ICLR 2020. Encoding word order in complex embeddings.
改变 Attention 计算项
既然是在 Attention bias 计算中丢失了相对位置信息,一个很 Naive 的想法就是在 Attention bias 计算时加回去。
Self-Attention with Relative Position Representations.
18 年的 NAACL(那就是 17 年底的工作),文章是一篇短文,Peter Shaw, Jakob Uszkoreit, Ashish Vaswani 看名字是发 Transformer 的那批人(想来其他人也不能在那么短时间有那么深的思考 🤔).
他们分别在 QK 乘积计算 Attention bias 的时候和 SoftMax 之后在 Value 后面两处地方加上了一个相对编码(两处参数不共享)。
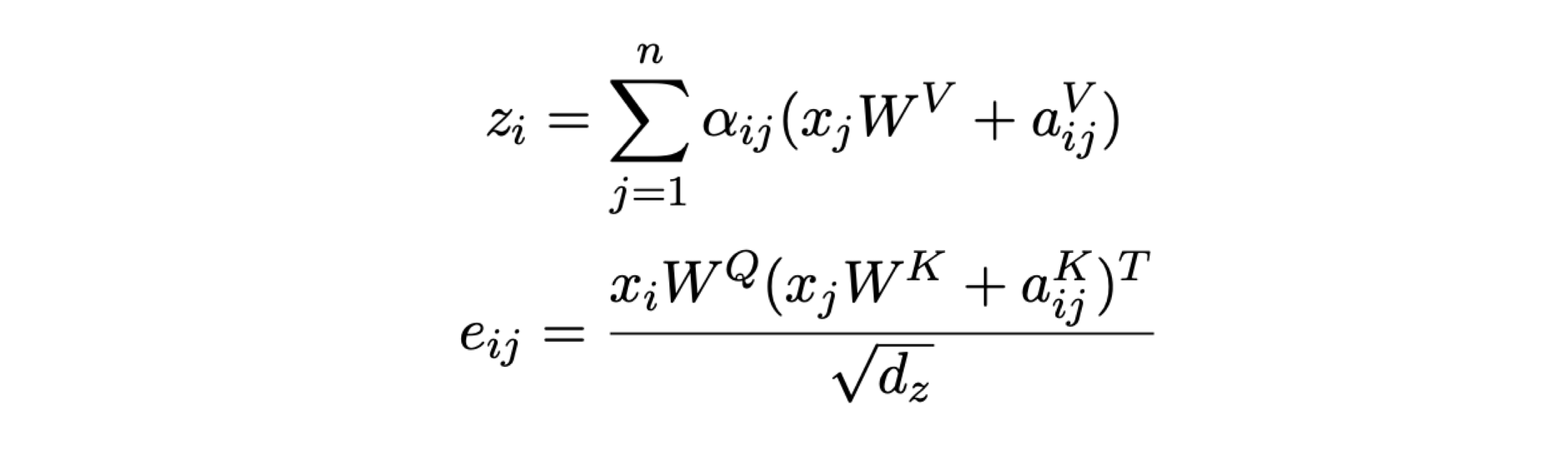
为了降低复杂度,在不同 head 之间共享了参数。
实验显示,在 WMT14 英德数据集上 base mo
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 841
841

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









