






一. Mask rcnn简述
Mask rcnn是何凯明基于以往的faster rcnn架构提出的新的卷积网络,一举完成了object instance segmentation. 该方法在有效地目标的同时完成了高质量的语义分割。 文章的主要思路就是把原有的Faster-RCNN进行扩展,添加一个分支使用现有的检测对目标进行并行预测。同时,这个网络结构比较容易实现和训练,速度5fps也算比较快点,可以很方便的应用到其他的领域,像目标检测,分割,和人物关键点检测等。并且比着现有的算法效果都要好,在后面的实验结果部分有展示出来。
场景理解

Mask R-CNN: overview

从上面可以知道,mask rcnn主要的贡献在于如下:
1. 强化的基础网络
通过 ResNeXt-101+FPN 用作特征提取网络,达到 state-of-the-art 的效果。作者替换了在faster rcnn中使用的vgg网络,转而使用特征表达能力更强的残差网络,另外为了挖掘多尺度信息,作者还使用了FPN网络。
2. ROIAlign解决Misalignment 的问题
说到这里,自然要与roi pooling对比。
我们先看看roi pooling的原理,这里我们可以看下面的动图,一目了然。
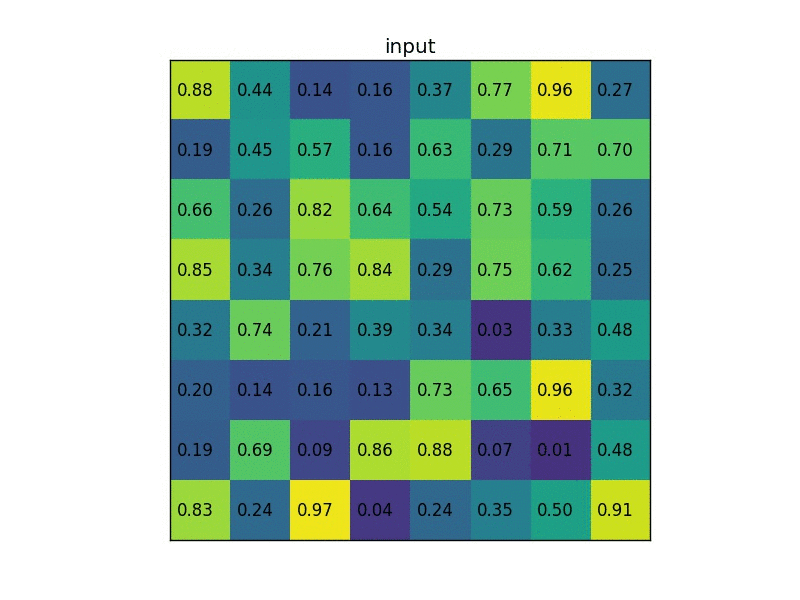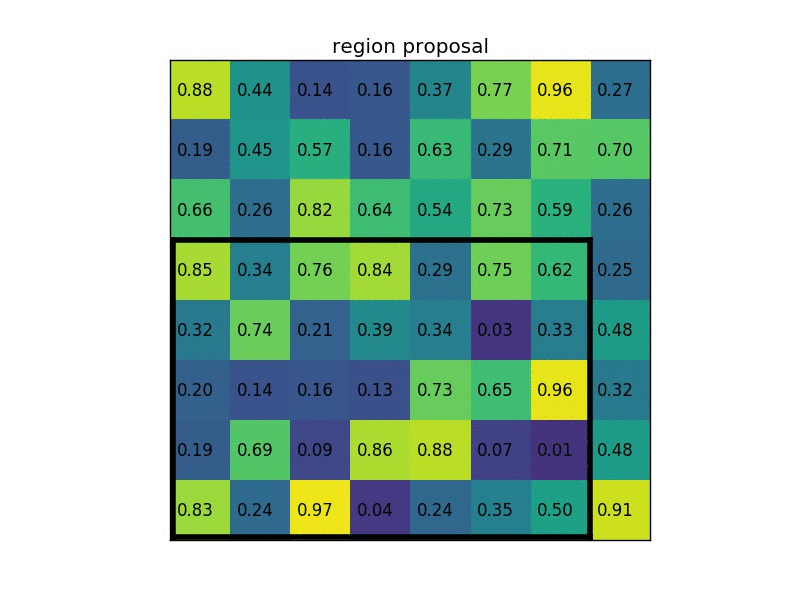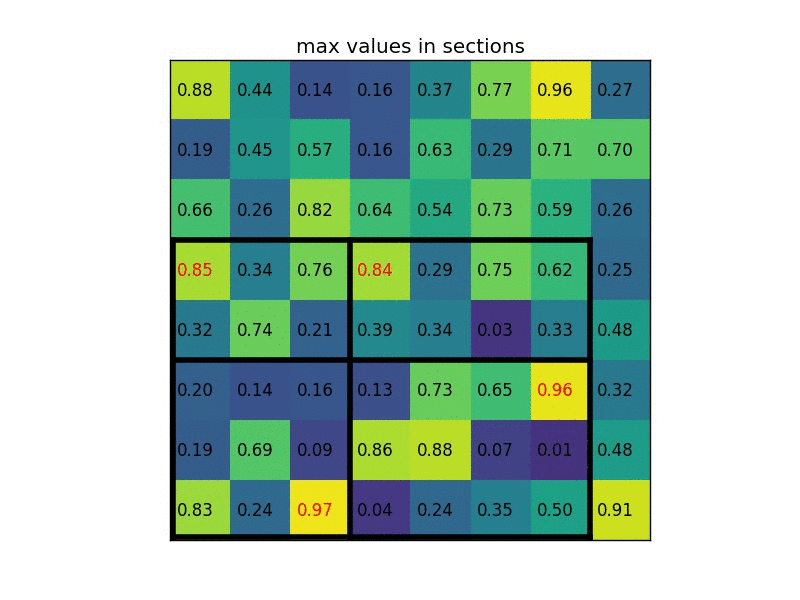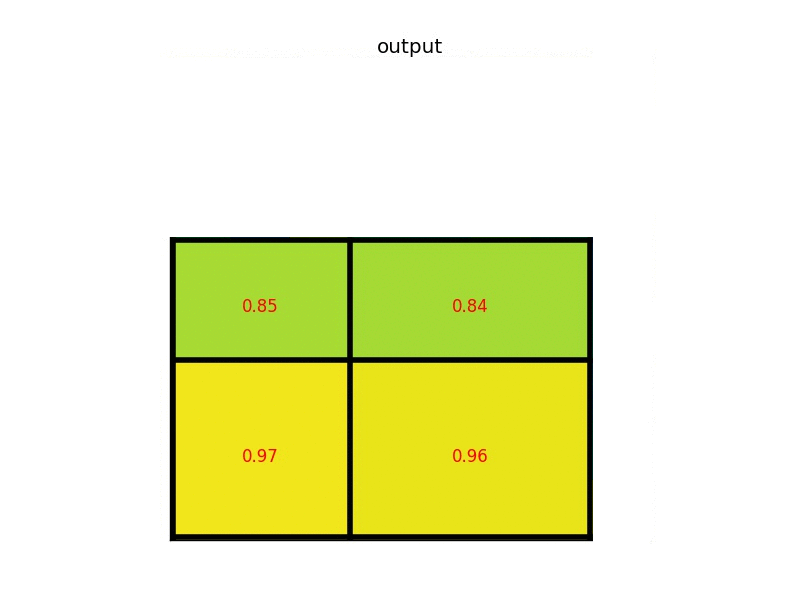
对于roi pooling,经历了两个量化的过程:
第一个:从roi proposal到feature map的映射过程。方法是[x/16],这里x是原始roi的坐标值,而方框代表四舍五入。
第二个:从feature map划分成7*7的bin,每个bin使用max pooling。
如上,roi映射到feature map后,不再进行四舍五入。然后将候选区域分割成k x k个单元, 在每个单元中计算固定四个坐标位置,用双线性内插的方法计算出这四个位置的值,然后进行最大池化操作。
这里对上述步骤的第三点作一些说明:这个固定位置是指在每一个矩形单元(bin)中按照比例确定的相对位置。比如,如果采样点数是1,那么就是这个单元的中心点。如果采样点数是4,那么就是把这个单元平均分割成四个小方块以后它们分别的中心点。显然这些采样点的坐标通常是浮点数,所以需要使用插值的方法得到它的像素值。在相关实验中,作者发现将采样点设为4会获得最佳性能,甚至直接设为1在性能上也相差无几。事实上,ROI Align 在遍历取样点的数量上没有ROIPooling那么多,但却可以获得更好的性能,这主要归功于解决了misalignment的问题。值得一提的是,在做实验的时候发现,ROI Align在VOC2007数据集上的提升效果并不如在COCO上明显。经过分析为造成这种区别的原因是COCO上小目标的数量更多,而小目标misalignment问题的影响更为明显(比如,同样是0.5个像素点的偏差,对于较大的目标而言显得微不足道,但是对于小目标,误差的影响就要高很多)
二. 实验结果







三. 将图片进行推流,并在安卓端显示
from flask import Flask, render_template, Response
from camera import VideoCamera
app = Flask(__name__)
@app.route('/')
def index():
return render_template('index.html')
def gen(camera):
while True:
frame = camera.get_frame()
yield (b'--frame\r\n'
b'Content-Type: image/jpeg\r\n\r\n' + frame + b'\r\n\r\n')
@app.route('/video_feed')
def video_feed():
return Response(gen(VideoCamera()),
mimetype='multipart/x-mixed-replace; boundary=frame')
if __name__ == '__main__':
app.run(host='0.0.0.0', port=8080, debug=True)
其实完成第一步就几乎完成了很大部分的工作了,用手机浏览器输入ip地址就可以查看。但是编写手机客户端有利于摄像头的管
我在这里主要说说图片获取之后的处理和显示的方法。
http获取图片数据流
private void doGet() {
//get http img
String url = "http://192.168.0.105:8080/?action=snapshot";
// Log.d(TAG, url);
myHttpThreadGet = new HttpThreadGet(url, HttpThreadGet.GETIMG, handler);
myHttpThreadGet.start();
}
消息传递获取,这里只用了获取图片
/************************** msg接收 *************************/
handler = new Handler() {
@Override
public void handleMessage(Message msg) {
switch (msg.what) {
case HttpThreadPost.POST:
result = (String) msg.obj;
break;
case HttpThreadGet.GET:
result = (String) msg.obj;
break;
case HttpThreadGet.GETIMG:
buffer = (byte[])msg.obj;
try {
image = BitmapFactory.decodeByteArray(buffer, 0, buffer.length, BitmapFactoryinfo);
faceDetect(image);
} catch (Exception e) {
Log.e(TAG, e.toString());
}
doGet(); //再请求
break;
default:
break;
}
}
};
由于图片是JPEG格式的数据流,需要通过BitmapFactory重新编码,如果要实现人脸识别FaceDetector的话需要将图片格式化Bitmap.Config.RGB_565。
/************************** face detect *************************/
private void faceDetect(Bitmap fBitmap) {
// myBitmap = BitmapFactory.decodeResource(getResources(), R.drawable.baby, BitmapFactoryOptionsbfo);
int imageWidth = fBitmap.getWidth();
int imageHeight = fBitmap.getHeight();
myFace = new FaceDetector.Face[numberOfFace]; //分配人脸数组空间
myFaceDetect = new FaceDetector(imageWidth, imageHeight, numberOfFace);
numberOfFaceDetected = myFaceDetect.findFaces(fBitmap, myFace); //FaceDetector 构造实例并解析人脸
countertext.setText("numberOfFaceDetected is " + numberOfFaceDetected);
Log.i(TAG,"numberOfFaceDetected is " + numberOfFaceDetected);
Bitmap bitmapTemp = Bitmap.createBitmap(fBitmap.getWidth(), fBitmap.getHeight(), Bitmap.Config.RGB_565);
Canvas canvas = new Canvas(bitmapTemp);
canvas.drawColor(Color.TRANSPARENT);
Paint myPaint = new Paint();
myPaint.setColor(Color.GREEN);
myPaint.setStyle(Paint.Style.STROKE);
myPaint.setStrokeWidth(3); //设置位图上paint操作的参数
canvas.drawBitmap(fBitmap, 0, 0, myPaint);
for(int i=0; i < numberOfFaceDetected; i++){
Face face = myFace[i];
PointF myMidPoint = new PointF();
face.getMidPoint(myMidPoint);
myEyesDistance = face.eyesDistance(); //得到人脸中心点和眼间距离参数,并对每个人脸进行画框
canvas.drawRect( //矩形框的位置参数
(int)(myMidPoint.x - myEyesDistance),
(int)(myMidPoint.y - myEyesDistance),
(int)(myMidPoint.x + myEyesDistance),
(int)(myMidPoint.y + myEyesDistance),
myPaint);
}
imageview.setImageBitmap(bitmapTemp);
}





















 到【灌水乐园】发言
到【灌水乐园】发言







