



最近在刷SQL经典50题,把代码和想法发到这里以飨读者。
创建四张表:(这张表的数据可能会有点小出入,执行代码结果不一定完全和我的一样,不用担心,理解代码就好。)
--学生表
CREATE TABLE `student`(
`Sid` VARCHAR(10),
`Sname` VARCHAR(10) NOT NULL DEFAULT '',
`Ssge` DATETIME NOT NULL DEFAULT '',
`Ssex` VARCHAR(10) NOT NULL DEFAULT '',
PRIMARY KEY(`Sid`)
);
--课程表
CREATE TABLE `course`(
`Cid` VARCHAR(10),
`Cname` VARCHAR(10) NOT NULL DEFAULT '',
`Tid` VARCHAR(10) NOT NULL,
PRIMARY KEY(`Cid`)
);
--教师表
CREATE TABLE `teacher`(
`Tid` VARCHAR(10),
`Tname` VARCHAR(10) NOT NULL DEFAULT '',
PRIMARY KEY(`Tid`)
);
--成绩表
CREATE TABLE `sc1`(
`Sid` VARCHAR(20),
`Cid` VARCHAR(20),
`score` INT(3),
PRIMARY KEY(`Sid`,`Cid`)
);
--插入学生表测试数据
insert into Student values('01' , '赵雷' , '1990-01-01' , '男');
insert into Student values('02' , '钱电' , '1990-12-21' , '男');
insert into Student values('03' , '孙风' , '1990-12-20' , '男');
insert into Student values('04' , '李云' , '1990-12-06' , '男');
insert into Student values('05' , '周梅' , '1991-12-01' , '女');
insert into Student values('06' , '吴兰' , '1992-01-01' , '女');
insert into Student values('07' , '郑竹' , '1989-01-01' , '女');
insert into Student values('08' , '张三' , '1990-12-20' , '女');
--课程表测试数据
insert into Course values('01' , '语文' , '02');
insert into Course values('02' , '数学' , '01');
insert into Course values('03' , '英语' , '03');
--教师表测试数据
insert into Teacher values('01' , '张三');
insert into Teacher values('02' , '李四');
insert into Teacher values('03' , '王五');
--成绩表测试数据
insert into Score values('01' , '01' , 80);
insert into Score values('01' , '02' , 90);
insert into Score values('01' , '03' , 99);
insert into Score values('02' , '01' , 70);
insert into Score values('02' , '02' , 60);
insert into Score values('02' , '03' , 80);
insert into Score values('03' , '01' , 80);
insert into Score values('03' , '02' , 80);
insert into Score values('03' , '03' , 80);
insert into Score values('04' , '01' , 50);
insert into Score values('04' , '02' , 30);
insert into Score values('04' , '03' , 20);
insert into Score values('05' , '01' , 76);
insert into Score values('05' , '02' , 87);
insert into Score values('06' , '01' , 31);
insert into Score values('06' , '03' , 34);
insert into Score values('07' , '02' , 89);
insert into Score values('07' , '03' , 98);
数据来源参考:MySQL练习:50道经典SQL练习题(1.4w字包全面)_mysql数据库sql练习题下载-优快云博客
1、查询课程编号为“01”的课程比“02”的课程成绩高的所有学生的学号(难)
2、查询平均成绩大于60分的学生的学号和平均成绩
3、查询所有学生的学号、姓名、选课数、总成绩
4、查询姓“李”的老师的个数
5、查询没学过“张三”老师课的学生的学号、姓名
6、查询学过“张三”老师所教的所有课的同学的学号、姓名
7、查询学过编号为“01”的课程并且也学过编号为“02”的课程的学生的学号、姓名
8、查询课程编号为“02”的总成绩
9、查询所有课程成绩小于60分的学生的学号、姓名
10、查询没有学全所有课的学生的学号、姓名
11、查询至少有一门课与学号为“01”的学生所学课程相同的学生的学号和姓名 (难)
12、查询和“01”号同学所学课程完全相同的其他同学的学号(难)
13、查询没学过"张三"老师讲授的任一门课程的学生姓名 和47题一样
14、查询学过编号为"01"但是没有学过编号为"02"的课程的同学的信息
15、查询两门及其以上不及格课程的同学的学号,姓名及其平均成绩
16、检索"01"课程分数小于60,按分数降序排列的学生信息
17、按平均成绩从高到低显示所有学生的所有课程的成绩以及平均成绩(难)
18、查询各科成绩最高分、最低分和平均分:以如下形式显示:课程ID,课程name,最高分,最低分,平均分,及格率,中等率,优良率,优秀率– 及格为>=60,中等为:70-80,优良为:80-90,优秀为:>=90
19、按各科成绩进行排序,并显示排名(难)
20、查询学生的总成绩并进行排名
21、查询不同老师所教不同课程平均分从高到低显示
22、查询所有课程的成绩第2名到第3名的学生信息及该课程成绩(重要 25类似)
23、统计各科成绩各分数段人数:课程编号,课程名称,[100-85],[85-70],[70-60],[0-60]及所占百分比
24、查询学生平均成绩及其名次
25、查询各科成绩前三名的记录(不考虑成绩并列情况)
26、查询每门课程被选修的学生数
27、查询出只有两门课程的全部学生的学号和姓名
28、查询男生、女生人数
29、查询名字中含有"风"字的学生信息
30、查询同名同性学生名单,并统计同名人数
31、查询1990年出生的学生名单
32、查询平均成绩大于等于85的所有学生的学号、姓名和平均成绩
33、查询每门课程的平均成绩,结果按平均成绩升序排序,平均成绩相同时,按课程号降序排列
34、查询课程名称为"数学",且分数低于60的学生姓名和分数
35、查询所有学生的课程及分数情况
36、查询任何一门课程成绩在70分以上的学生姓名、课程名称和分数
37、查询不及格的学生并按课程号从大到小排列
38、查询课程编号为03且课程成绩在80分以上的学生的学号和姓名
39、求每门课程的学生人数
40、查询选修“张三”老师所授课程的学生中成绩最高的学生姓名及其成绩
41、查询不同课程成绩相同的学生的学生编号、课程编号、学生成绩 (难)
42、查询每门课程成绩最好的前两名
43、统计每门课程的学生选修人数(超过5人的课程才统计)。要求输出课程号和选修人数,查询结果按人数降序排列,若人数相同,按课程号升序排列
44、检索至少选修两门课程的学生学号
45、查询选修了全部课程的学生信息
46、查询各学生的年龄
47、查询本周过生日的学生
48、查询下周过生日的学生
49、查询本月过生日的学生
50、查询下一个月过生日的学生1、查询课程编号为“01”的课程比“02”的课程成绩高的所有学生的学号(难)
这里我选用了2种不同的方式来展现,一个是多表连接(在数据量大的时候有优势),一个是子查询(在数据量小的时候有优势)。
-- 查询"01"课程比"02"课程成绩高的学生信息及课程分数--多表连接
select s1.sid, s1.sname, sc1.score '01成绩', sc2.score '02成绩'
from student s1, student s2, sc1, sc1 sc2
where s1.sid = s2.sid and s1.sid = sc1.sid and sc1.cid = '01'
and s2.sid = sc2.sid and sc2.cid='02' and sc1.score>sc2.score;
-- 将学号,01课程成绩,02课程成绩分别筛选出子表,然后再用排除条件--子查询
select distinct s.sid,st.sname,s1.score as "01成绩",s2.score as "02成绩"
from sc1 as s
inner join (select * from sc1 where cid = '01') as s1 on s.sid = s1.sid
inner join (select * from sc1 where cid = '02') as s2 on s.sid = s2.sid
inner join student as st on s.sid = st.sid
where s1.score > s2.score;运行结果一致:

2、查询平均成绩大于60分的学生的学号和平均成绩
我分别使用了join+on 和round以及using()和truncate操作,这两种结果略有差异,主要是因为round和truncate分别对结果进行了四舍五入和直接截断的操作。同时保留两位的情况下,round会把1.469保留为1.47,而truncate会将其保留为1.46。
-- 查询平均成绩大于等于60分的同学的学生编号和学生姓名和平均成绩
-- join+on round
select s1.sid, s1.sname, round(avg(score), 2) avg_score
from student s1 join sc1 on s1.sid=sc1.sid
group by sid, sname
having avg(score)>= 60;
-- using() truncate
select s1.sid, s1.sname, TRUNCATE(avg(score), 2) avg_score
from student s1 join sc1 using(sid)
group by sid, sname
having avg(score)>= 60;round结果:
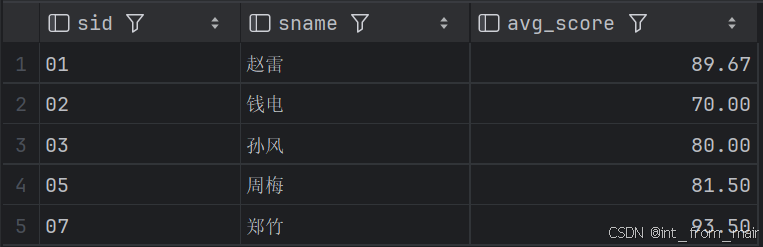
truncate结果:

3、查询所有学生的学号、姓名、选课数、总成绩
这里比较简单,主要是表连接和聚合函数的使用;这里我的想法是需要明确出来,是否所有的学生信息都需要,还是只需要一部分选了课的学生,可能会在工作中涉及到吧。
-- 查询所有学生的学号、姓名、选课数、总成绩
select distinct s1.sid, s1.sname, count(distinct cid) count_cid, sum(score) total_score
from student s1 left join sc1 using(sid)
group by s1.sid, s1.sname;
-- 排除未选课的学生
select distinct s1.sid, s1.sname, count(distinct cid) count_cid, sum(score) total_score
from student s1 join sc1 using(sid)
group by s1.sid, s1.sname;
-- 考察点:使用子查询作为计算字段,case when用法,聚集函数sum()
select a.sid,a.sname, count(b.cid) as "count_cid",
sum(case when b.score is null then 0 else b.score END) as "total_score"
from student as a
left join sc1 as b on a.sid = b.sid
group by a.sid, a.sname;全部学生信息:
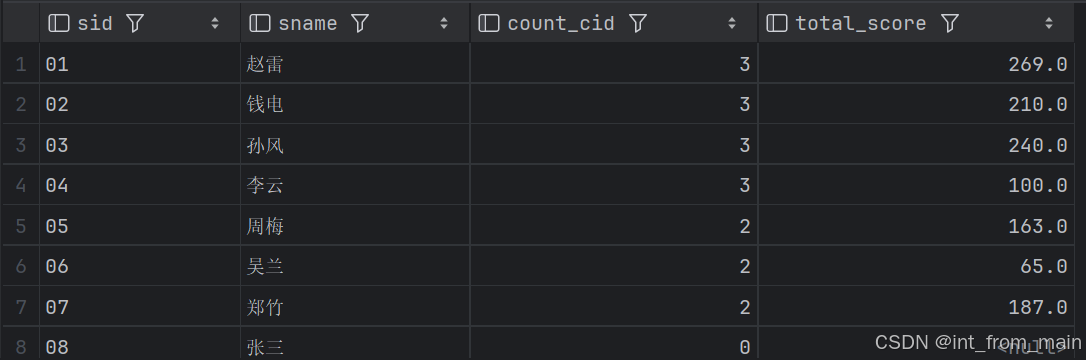
选课了的学生信息展示:

第三部分的代码我采用的是case when结合进去,实际和第一种的方法差异不大,就是total_score从NULL变成了0,所以不再展示。
4、查询姓“李”的老师的个数
这里我采用了3种解法,一个是使用通配符,一种是使用正则表达式,一类是使用字符串函数;
-- 查询姓“李”的老师的个数 -- 通配符
select count(*) number
from teacher t1
where t1.tname like '李%';
-- REGEXP 正则表达式,不一定所有sql都通用
select count(distinct tid) number
from teacher t1
where t1.tname regexp '^李';
-- 字符串函数
select count(distinct tname) number
from teacher t1
where left(t1.tname, 1) ='李';三者结果一致:

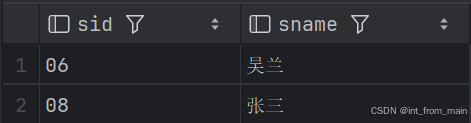
5、查询没学过“张三”老师课的学生的学号、姓名
我选择了使用not in和not exist两种方式来实现,对于not in理解起来较为容易些,而对于not exist来说,我所注意到的就是不需要像not in那样指定太多的条件,而是可以直接使用select 1,写起来方便一些。
-- 查询没学过“张三”老师课的学生的学号、姓名
select s2.sid, s2.sname
from student s2
where s2.sid not in (
select s1.sid
from student s1, teacher t1, course c1, sc1
where s1.sid = sc1.sid and t1.tid = c1.tid and sc1.cid = c1.cid and t1.tname = '张三'
);
-- 使用exist
SELECT s2.sid, s2.sname
FROM student s2
WHERE NOT EXISTS (
SELECT 1
FROM student s1, teacher t1, course c1, sc1
WHERE s1.sid = sc1.sid
AND t1.tid = c1.tid
AND sc1.cid = c1.cid
AND t1.tname = '张三'
AND s1.sid = s2.sid -- 建立关联
);
两者结果一样,这里面我学习到的是,exist来做子查询,就需要在子查询和父查询中间建立一个联系,不然很可能导致错误。
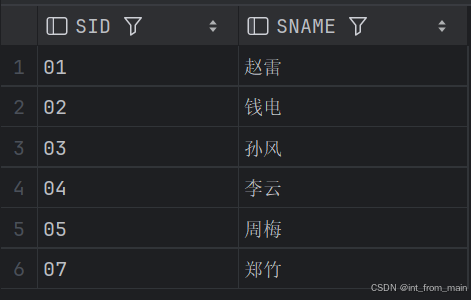
6、查询学过“张三”老师所教的所有课的同学的学号、姓名(难)
这里我选择了两种解法,一种是使用count,一种是使用not exist双层子查询,请各位注意,这里我解决的问题是,学了张三老师所教的所有课程的学生,也就是说假设张三老师教了三节课,某个学生只选了2节,那我们不会把他放进来。这里比较难理解,所以简单版可以看解法一,这里就是说张三老师教了三节课,然后学生某某学的张三老师教的课一共三节,我们会把他筛选出来;而解法二的话,我现在还不能比较清楚地说清楚啥意思,借用下ai表达吧:
整体逻辑概述:
通过 NOT EXISTS 子查询来实现筛选,核心思路是对于每个学生,检查 “张三” 老师所教的每一门课程,若该学生都有选修记录,则将该学生筛选出来。
执行流程总结:
-
外层查询遍历
STUDENT表中的每一个学生记录。 -
对于每个学生,第一层子查询找出 “张三” 老师所教的所有课程。
-
对于 “张三” 老师的每一门课程,第二层子查询检查该学生是否有选课记录。
-
如果存在某一门课程,该学生没有选课记录,那么第二层子查询没有返回结果,
NOT EXISTS条件为真,第一层子查询会返回该课程的CID,此时外层查询的NOT EXISTS条件为假,该学生不会被筛选出来。 -
只有当 “张三” 老师的所有课程,该学生都有选课记录时,第一层子查询不会返回任何结果,外层查询的
NOT EXISTS条件为真,该学生记录会被筛选出来。-- 使用count SELECT S1.SID, S1.SNAME FROM STUDENT S1, SC1, TEACHER T1, COURSE C1 WHERE S1.SID = SC1.SID AND T1.TID = C1.TID AND C1.CID = SC1.CID AND TNAME='张三' GROUP BY S1.SID, S1.SNAME HAVING COUNT(DISTINCT C1.CID) = (SELECT COUNT(*) FROM COURSE C2 JOIN TEACHER T2 USING(TID) WHERE TNAME='张三'); -- 使用双重子查询 SELECT S1.SID, S1.SNAME FROM STUDENT S1 WHERE NOT EXISTS( -- 这个老师教过的所有课程 SELECT C1.CID FROM COURSE C1 JOIN TEACHER T1 ON C1.TID = T1.TID WHERE T1.TNAME='张三' AND NOT EXISTS( SELECT SC1.CID FROM SC1 JOIN STUDENT S2 ON SC1.SID=S2.SID WHERE SC1.CID = C1.CID AND SC1.SID = S1.SID ) );
-
两者结果一样:
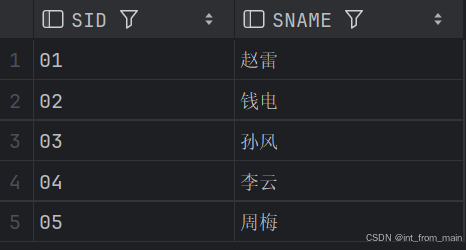
7、查询学过编号为“01”的课程并且也学过编号为“02”的课程的学生的学号、姓名
我使用了3种方法,一种是连接+连接,一种是子查询,一种是with临时表,本来还想用intersect的,我的系统是MYSQL所以没有使用。
-- 查询学过编号为“01”的课程并且也学过编号为“02”的课程的学生的学号、姓名
-- 使用连接和连接
SELECT S1.SID, S1.SNAME
FROM STUDENT S1 JOIN SC1 ON S1.SID = SC1.SID
JOIN SC1 SC2 ON S1.SID = SC2.SID
WHERE SC1.CID='01' AND SC2.CID='02';
-- 使用子查询
SELECT S1.SID, S1.SNAME
FROM STUDENT S1 JOIN SC1 ON S1.SID = SC1.SID
WHERE SC1.CID = '01' AND S1.SID IN (
SELECT S2.SID
FROM STUDENT S2 JOIN SC1 SC2 USING (SID)
WHERE SC2.CID = '02'
);
-- 临时表
WITH T1 AS(
SELECT S1.SID, S1.SNAME
FROM STUDENT S1 JOIN SC1 USING(SID)
WHERE SC1.CID = '01'
),T2 AS(
SELECT S2.SID, S2.SNAME
FROM STUDENT S2 JOIN SC1 SC2 ON S2.SID = SC2.SID
WHERE SC2.CID = '02'
)
SELECT T1.SID, T1.SNAME
FROM T1 JOIN T2 ON T1.SID = T2.SID;
结果一致:
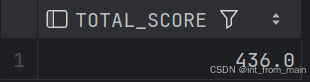
8、查询课程编号为“02”的总成绩
不难的一道题,可以使用或者不使用聚合函数
-- 查询课程编号为“02”的总成绩
SELECT SUM(SCORE) TOTAL_SCORE
FROM SC1
WHERE CID='02';
-- 聚合函数
SELECT SUM(SCORE) TOTAL_SCORE
FROM SC1
GROUP BY CID
HAVING CID='02';结果一致:
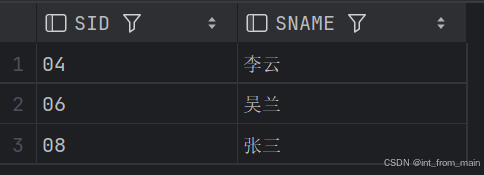
9、查询所有课程成绩小于60分的学生的学号、姓名
我是用了三种方法,一种是用子查询, not in不要有一门分数打过60分的学生的ID;一种是使用not exists;一种是使用聚合函数,只要这个同学最高分不超过60,那就满足题设条件了。
-- 查询所有课程成绩小于60分的学生的学号、姓名
SELECT S1.SID, S1.SNAME
FROM STUDENT S1
WHERE S1.SID NOT IN (
SELECT S2.SID
FROM STUDENT S2 JOIN SC1 USING(SID)
WHERE SC1.SCORE >= 60
);
SELECT S1.SID, S1.SNAME
FROM STUDENT S1
WHERE NOT EXISTS(
SELECT 1
FROM STUDENT S2 JOIN SC1 USING(SID)
WHERE SC1.SCORE >= 60 AND S2.SID=S1.SID
);
-- 聚合函数: 最大的一门课都小于60,也就是所有的都小于60了,另外,有的同学一门课都没有考过试,所以我后面多加了一个姓名不在成绩表里的选项
SELECT S1.SID, S1.SNAME
FROM STUDENT S1
WHERE (SELECT MAX(SC1.SCORE) FROM SC1 WHERE SID = S1.SID GROUP BY S1.SID ) < 60
or S1.SID NOT IN (SELECT DISTINCT SID FROM SC1);结果一致:
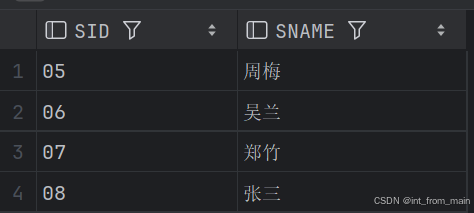
10、查询没有学全所有课的学生的学号、姓名
这道题就和刚才寻找学了张三老师所教的所有课的学生一样,只不过这在外面再套一层父查询
-- 查询没有学全所有课的学生的学号、姓名
SELECT S1.SID, S1.SNAME
FROM STUDENT S1
WHERE S1.SID NOT IN(
SELECT S2.SID
FROM STUDENT S2 JOIN SC1 USING(SID)
GROUP BY S2.SID
HAVING COUNT(DISTINCT SC1.CID) = (
SELECT COUNT(DISTINCT SC2.CID)
FROM SC1 SC2
)
);
-- NOT EXISTS 使用双重子查询
SELECT S1.SID, S1.SNAME
FROM STUDENT S1
WHERE S1.SID NOT IN (
SELECT S2.SID
FROM STUDENT S2
WHERE NOT EXISTS(
SELECT DISTINCT CID -- 所有课程
FROM SC1
WHERE NOT EXISTS(
SELECT 1
FROM SC1 SC2 JOIN STUDENT S3 USING(SID)
WHERE SC2.CID = SC1.CID AND SC2.SID = S2.SID
)
)
);结果一致:
11、查询至少有一门课与学号为“01”的学生所学课程相同的学生的学号和姓名
这个比较简单,就是使用子查询先找出来这个学生学的课程就好。
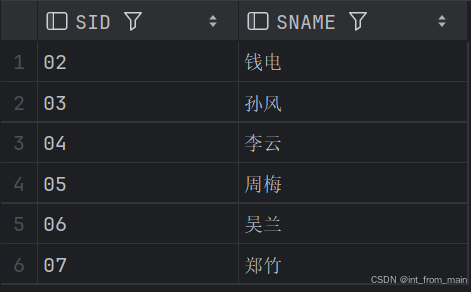
-- 查询至少有一门课与学号为“01”的学生所学课程相同的学生的学号和姓名 (难)
SELECT DISTINCT S1.SID, S1.SNAME
FROM STUDENT S1 JOIN SC1 USING (SID)
WHERE SC1.CID IN (
SELECT SC2.CID
FROM SC1 SC2
WHERE SC2.SID = '01'
) AND S1.SID <> '01';结果:
12、查询和“01”号同学所学课程完全相同的其他同学的学号(难)
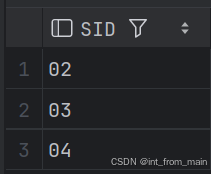
这里不适合用not exists,直接用count对比就好。
-- 查询和“01”号同学所学课程完全相同的其他同学的学号(难)
SELECT SC1.SID
FROM SC1
WHERE SC1.SID <> '01' AND SC1.CID IN (
SELECT SC2.CID
FROM SC1 SC2
WHERE SC2.SID = '01'
)
GROUP BY SC1.SID
HAVING COUNT(DISTINCT SC1.CID) = (
SELECT COUNT(DISTINCT SC3.CID)
FROM SC1 SC3
WHERE SC3.SID = '01'
);
结果:
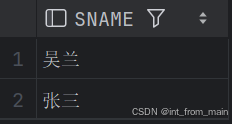
13、查询没学过"张三"老师讲授的任一门课程的学生姓名 和47题一样
我使用了两种解法,一个用not in,一个用not exists。
-- 查询没学过"张三"老师讲授的任一门课程的学生姓名
SELECT S1.SNAME
FROM STUDENT S1
WHERE S1.SID NOT IN(
SELECT S2.SID
FROM STUDENT S2, SC1, COURSE C1, TEACHER T1
WHERE T1.TID = C1.TID AND C1.CID = SC1.CID AND SC1.SID = S2.SID AND T1.TNAME='张三'
);
-- not exists
SELECT S1.SNAME
FROM STUDENT S1
WHERE NOT EXISTS(
SELECT 1
FROM SC1, COURSE C1, TEACHER T1
WHERE T1.TID = C1.TID AND C1.CID = SC1.CID AND SC1.SID = S1.SID AND T1.TNAME='张三'
);结果一致:
14、查询学过编号为"01"但是没有学过编号为"02"的课程的同学的信息
比较简单,使用两次子查询。
-- 查询学过编号为"01"但是没有学过编号为"02"的课程的同学的信息
SELECT *
FROM STUDENT S1
WHERE S1.SID IN (
SELECT SC1.SID
FROM SC1
WHERE SC1.CID = '01'
) AND S1.SID NOT IN (
SELECT SC2.SID
FROM SC1 SC2
WHERE SC2.CID = '02'
);结果:

15、查询两门及其以上不及格课程的同学的学号,姓名及其平均成绩
思路:找到有两门以上不及格课程的学生学号,然后再去聚合求平均值,易错点在于外层查询也用到了聚合函数,所以别忘了group by
-- 查询两门及其以上不及格课程的同学的学号,姓名及其平均成绩
SELECT DISTINCT S1.SID, S1.SNAME, ROUND(AVG(SC1.SCORE),2)
FROM STUDENT S1 JOIN SC1 USING (SID)
WHERE S1.SID IN (
SELECT SC2.SID
FROM SC1 SC2
WHERE SC2.SCORE < 60
GROUP BY SC2.SID
HAVING COUNT(SCORE) >= 2
)
GROUP BY S1.SID, S1.SNAME;结果:

16、检索"01"课程分数小于60,按分数降序排列的学生信息
这个基本上没啥难度,主要是考察降序排序,order by feature desc
-- 检索"01"课程分数小于60,按分数降序排列的学生信息
SELECT S1.*, SC1.SCORE
FROM STUDENT S1 JOIN SC1 USING(SID)
WHERE SC1.CID = '01' AND SC1.SCORE < 60
ORDER BY SC1.SCORE DESC结果:

17、按平均成绩从高到低显示所有学生的所有课程的成绩以及平均成绩(难)
这一题比较难的,如果要降低难度,就需要使用到子查询或者说with 临时表 as,我这里用了两种方法,方法1是使用到了窗口函数,就是和excel里面的聚合函数比较类似;方法2就是简单地使用临时表功能了;不过这里我的解法和别的同学有差异,在我的解法下面列出来别的同学的解法;
-- 按平均成绩从高到低显示所有学生的所有课程的成绩以及平均成绩(难)
SELECT SC1.SID, SC1.CID, SC1.SCORE, AVG(SC1.SCORE) OVER(PARTITION BY SC1.SID) AS AVG_SCORE
FROM SC1
ORDER BY AVG_SCORE DESC, SC1.SCORE DESC;
-- 临时表+聚合函数
WITH T1 AS(
SELECT SC1.SID, AVG(SC1.SCORE) AVG_SCORE -- , DENSE_RANK()OVER(ORDER BY AVG(SC1.SCORE)DESC) AS SCORE_RANK
FROM SC1
GROUP BY SC1.SID)
SELECT SC2.SID,SC2.CID, SC2.SCORE, AVG_SCORE -- T1.SCORE_RANK
FROM SC1 SC2 JOIN T1 USING(SID)
ORDER BY AVG_SCORE DESC, SC2.SCORE DESC;
-- 别人的解法:
SELECT SC1.SID,
SUM(CASE SC1.CID WHEN 01 THEN SC1.SCORE ELSE 0 END) AS 01_SCORE,
SUM(CASE SC1.CID WHEN 02 THEN SC1.SCORE ELSE 0 END) AS 02_SCORE,
SUM(CASE SC1.CID WHEN 03 THEN SC1.SCORE ELSE 0 END) AS 03_SCORE,
ROUND(AVG(SC1.SCORE),2) AVG_SCORE
FROM SC1
GROUP BY SC1.SID
ORDER BY AVG_SCORE DESC;结果一致,比较长我就只粘上一部分:
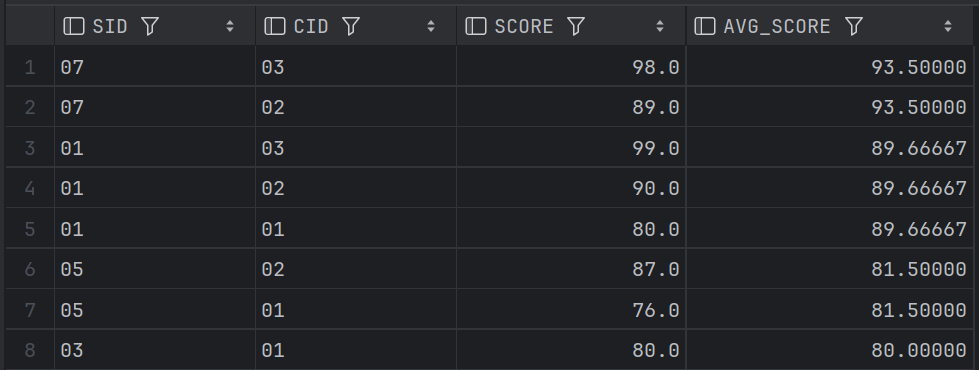
下面这个是别人的解法:
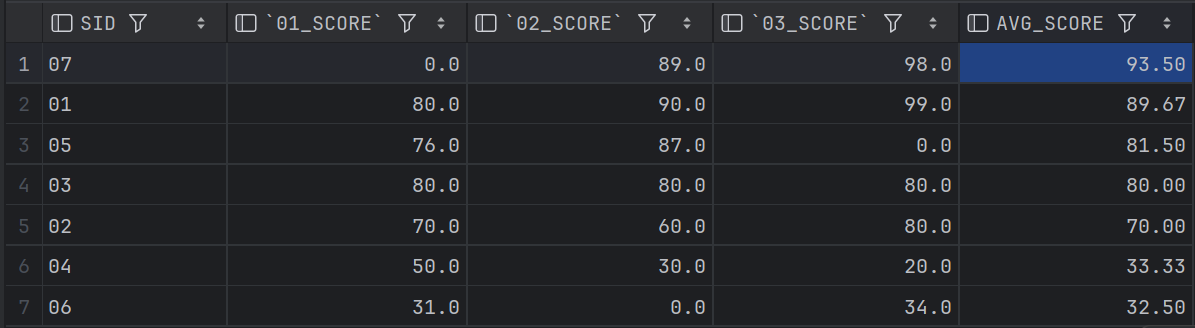
18、查询各科成绩最高分、最低分和平均分:
以如下形式显示:课程ID,课程name,最高分,最低分,平均分,及格率,中等率,优良率,优秀率– 及格为>=60,中等为:70-80,优良为:80-90,优秀为:>=90。
这里我采用了三种方式,一种是直接用一个select来嵌套进所有涉及到的函数,完成执行获取答案;一个是通过子查询的方式来获取计算的分子和分母,再在父查询中实现;一个是借鉴别的同学的方法,直接在select语句里面嵌套进select。
-- 查询各科成绩最高分、最低分和平均分
-- 以如下形式显示:课程ID,课程name,最高分,最低分,平均分,及格率,中等率,优良率,优秀率;
-- 及格为>=60,中等为:70-80,优良为:80-90,优秀为:>=90
SELECT SC1.CID '课程ID', C1.CNAME '课程NAME', MAX(SC1.SCORE) '最高分', MIN(SC1.SCORE) '最低分', ROUND(AVG(SC1.SCORE),2) '平均分',
CONCAT(ROUND(SUM(IF (SC1.SCORE>= 60, 1, 0))*100/COUNT(SC1.SCORE), 2), '%') '及格率',
CONCAT(ROUND(SUM(IF (SC1.SCORE>= 70 AND SC1.SCORE < 80, 1, 0))*100/COUNT(SC1.SCORE), 2), '%') '中等率',
CONCAT(ROUND(SUM(IF (SC1.SCORE>= 80 AND SC1.SCORE < 90, 1, 0))*100/COUNT(SC1.SCORE), 2), '%') '优良率',
CONCAT(ROUND(SUM(IF (SC1.SCORE>= 90, 1, 0))*100/COUNT(SC1.SCORE), 2), '%') '优秀率'
FROM SC1 JOIN COURSE C1 ON SC1.CID=C1.CID
GROUP BY SC1.CID, C1.CNAME;
WITH T1 AS(
SELECT SC1.CID, MAX(SC1.SCORE) MAX_S, MIN(SC1.SCORE) MIN_S, ROUND(AVG(SC1.SCORE), 2) AVG_S,
SUM(IF(SC1.SCORE >= 60, 1, 0)) PASS,
SUM(IF(SC1.SCORE >= 70 AND SC1.SCORE < 80, 1, 0)) MIDDLE,
SUM(IF(SC1.SCORE >= 80 AND SC1.SCORE < 90, 1, 0)) GOOD,
SUM(IF(SC1.SCORE >= 90, 1, 0)) GREAT,
COUNT(SC1.SCORE) SCORED
FROM SC1
GROUP BY SC1.CID
)
SELECT T1.CID, C1.CNAME, T1.MAX_S '最高分',T1.MIN_S '最低分', T1.AVG_S '平均分',
CONCAT(ROUND(T1.PASS*100/T1.SCORED,2), '%') '及格率',
CONCAT(ROUND(T1.MIDDLE*100/T1.SCORED,2), '%') '中等率',
CONCAT(ROUND(T1.GOOD*100/T1.SCORED,2), '%') '优良率',
CONCAT(ROUND(T1.GREAT*100/T1.SCORED,2), '%') '优秀率'
FROM T1 JOIN COURSE C1 ON T1.CID = C1.CID;
-- 子查询嵌入
select a.cid "课程ID", b.Cname "课程name",
avg(score) "平均分",
MAX(score) "最高分",
Min(score) "最低分",
concat(round((select count(*) from sc1 where cid = a.cid and score >= 60)*100/count(*),2),'%') "及格率",
concat(round((select count(*) from sc1 where cid = a.cid and score between 70 and 80)*100/count(*),2),'%') "中等率",
concat(round((select count(*) from sc1 where cid = a.cid and score between 80 and 90)*100/count(*),2),'%') "优良率",
concat(round((select count(*) from sc1 where cid = a.cid and score >= 90)*100/count(*),2),'%') "优秀率"
from sc1 as a, course as b
where a.cid = b.cid
group by a.cid, b.cname;三者答案一致:

19、按各科成绩进行排序,并显示排名(难)
首先是理解啥意思,当前一共三科,01,02,03,分别列出课程编号,课程名,排名,学生分数,学生编号,学生姓名,我是用了两种方法,一个是dense_rank,可以理解为1234都存在,但有人并列;另一个是row_number,理解为1234都存在,并列的也把他们改成非并列,按照别的要素进行排序。
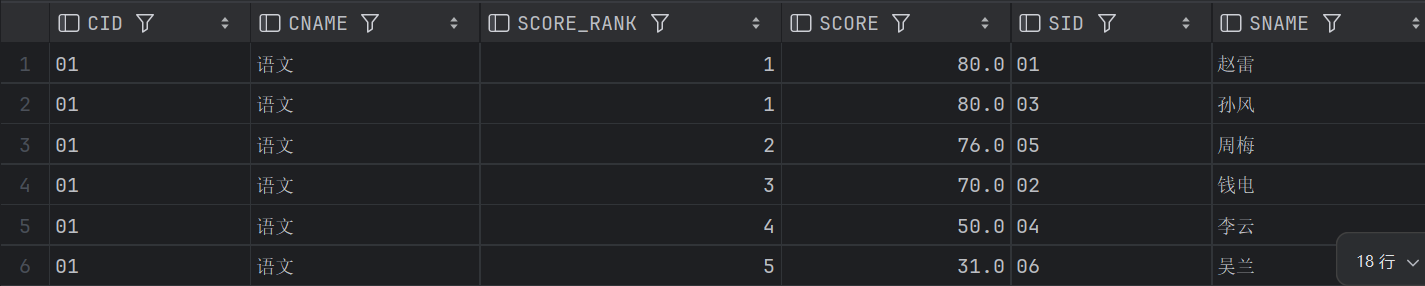
-- 按各科成绩进行排序,并显示排名 DENSE_RANK
SELECT C1.CID, C1.CNAME, DENSE_RANK()OVER(PARTITION BY SC1.CID ORDER BY SC1.SCORE DESC) SCORE_RANK,
SC1.SCORE, S1.SID, S1.SNAME
FROM STUDENT S1 JOIN SC1 USING(SID)
JOIN COURSE C1 USING(CID)
ORDER BY C1.CID, SCORE_RANK;
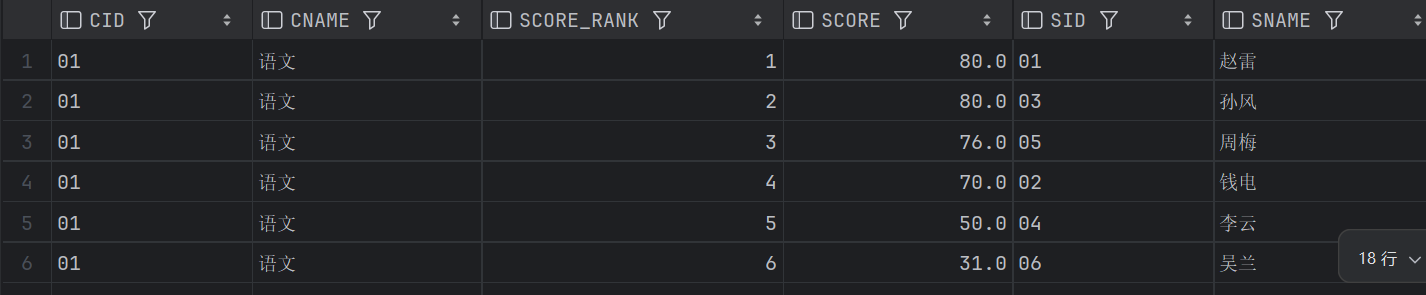
-- ROW_NUMBER
SELECT C1.CID, C1.CNAME, ROW_NUMBER()OVER(PARTITION BY SC1.CID ORDER BY SC1.SCORE DESC) SCORE_RANK,
SC1.SCORE, S1.SID, S1.SNAME
FROM STUDENT S1 JOIN SC1 USING(SID)
JOIN COURSE C1 USING(CID)
ORDER BY C1.CID, SCORE_RANK;结果略有差异,只保留分别的一部分:
DENSE_RANK:
ROW_NUMBER:
20、查询学生的总成绩并进行排名
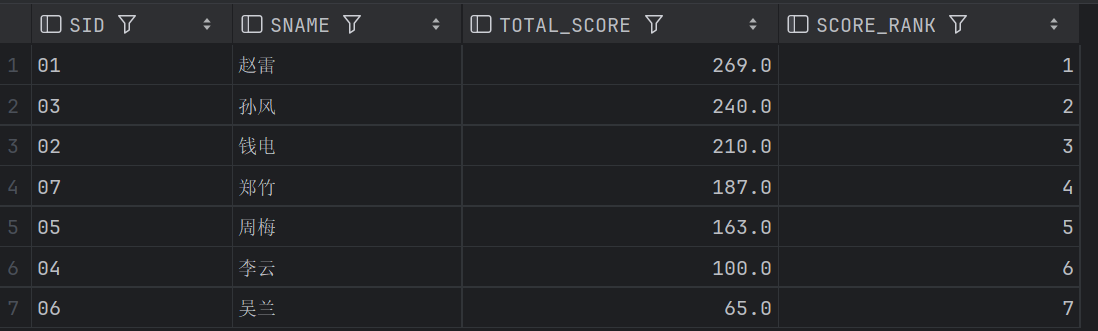
这个不是很难,主要是对窗口函数的使用,这里我是用rank(),需要注意的是,这时候不要轻易加partition by,加了partition by的话将会直接分组排序,排名都是1。
-- 查询学生的总成绩并进行排名
SELECT S1.SID, S1.SNAME,
SUM(SC1.SCORE) TOTAL_SCORE,
RANK() OVER(ORDER BY SUM(SC1.SCORE)DESC) SCORE_RANK
FROM STUDENT S1, SC1
WHERE S1.SID = SC1.SID
GROUP BY S1.SID, S1.SNAME;结果:
21、查询不同老师所教不同课程平均分从高到低显示
就还是窗口函数的使用
-- 查询不同老师所教不同课程平均分从高到低显示
SELECT T1.TID, T1.TNAME, C1.CID, C1.CNAME, ROUND(AVG(SC1.SCORE),2) AVG_SCORE,
RANK() OVER(ORDER BY AVG(SC1.SCORE) DESC)SCORE_RANK
FROM SC1 JOIN COURSE C1 ON SC1.CID = C1.CID, TEACHER T1
WHERE C1.TID = T1.TID
GROUP BY T1.TID, T1.TNAME, C1.CID, C1.CNAME
ORDER BY SCORE_RANK;结果:

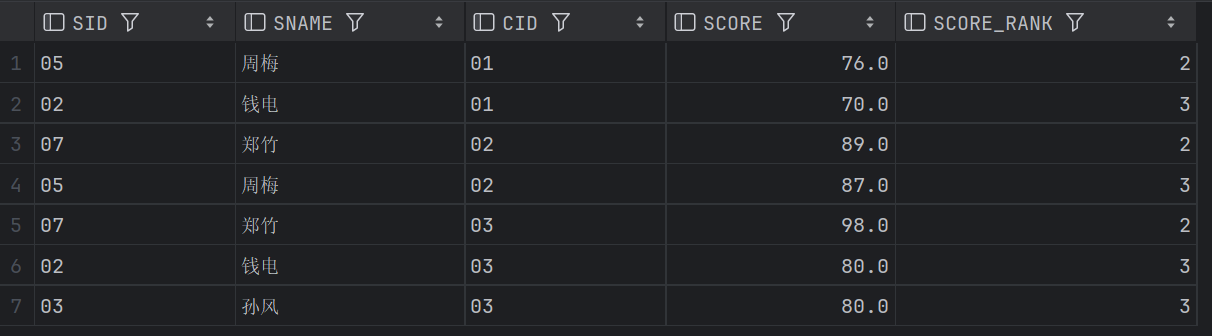
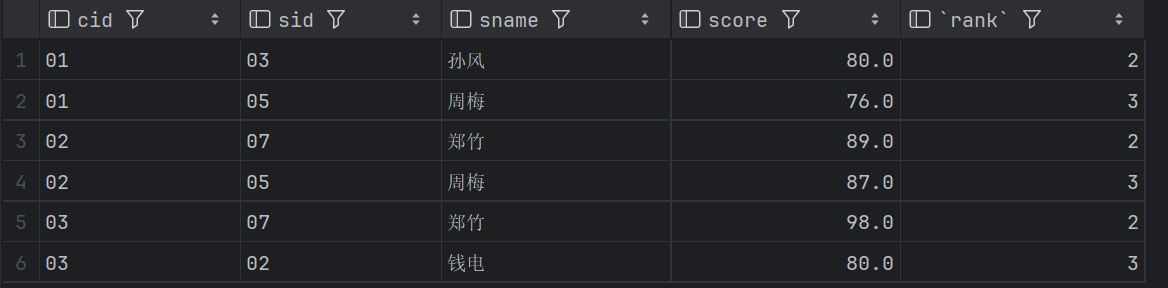
22、查询所有课程的成绩第2名到第3名的学生信息及该课程成绩(重要 25类似)
这里我采用了两种方法,一种是窗口函数,一种是union加上limit;窗口函数确实简单很多,而limit是单独解决单词查询比较好使的用法。
-- 查询所有课程的成绩第2名到第3名的学生信息及该课程成绩
WITH T1 AS (
SELECT SC1.CID, SC1.SID, SC1.SCORE, DENSE_RANK()OVER(PARTITION BY SC1.CID ORDER BY SC1.SCORE DESC) SCORE_RANK
FROM SC1
)
SELECT S1.SID, S1.SNAME, T1.CID, T1.SCORE, T1.SCORE_RANK
FROM T1 JOIN STUDENT S1 USING(SID)
WHERE SCORE_RANK IN (2,3)
ORDER BY CID, SCORE_RANK;
-- 粗暴union
(select cid,a.sid,sname,score,row_number() over (order by score desc) as 'rank'
from sc1 as a right join student as b
on b.sid = a.sid
where cid = '01'
order by cid,score desc
limit 1,2)
union all
(select cid,a.sid,sname,score,row_number() over (order by score desc) as 'rank'
from sc1 as a right join student as b
on b.sid = a.sid
where cid = '02'
order by cid,score desc
limit 1,2)
union all
(select cid,a.sid,sname,score,row_number() over (order by score desc) as 'rank'
from sc1 as a right join student as b
on b.sid = a.sid
where cid = '03'
order by cid,score desc
limit 1,2);
结果略有差异,是因为row_number和dense_Rank的差异。
方法一dense_rank:
方法二row_number:
23、统计各科成绩各分数段人数:课程编号,课程名称,[100-85],[85-70],[70-60],[0-60]及所占百分比
和第18题一样,要么直接一套直接下来,要么使用子查询。
-- 统计各科成绩各分数段人数:课程编号,课程名称,[100-85],[85-70],[70-60],[0-60]及所占百分比
-- 一套直接下来
SELECT SC1.CID, C1.CNAME,
SUM(IF(SC1.SCORE >85, 1, 0)) '[100-85]',
CONCAT(ROUND(SUM(IF(SC1.SCORE >85, 1, 0))*100/COUNT(SC1.SCORE), 2),'%') 'PERCENT1',
SUM(IF(SC1.SCORE >70 AND SC1.SCORE<=85, 1, 0)) '[85-70]',
CONCAT(ROUND(SUM(IF(SC1.SCORE >70 AND SC1.SCORE<=85, 1, 0))*100/COUNT(SC1.SCORE), 2),'%') 'PERCENT2',
SUM(IF(SC1.SCORE >60 AND SC1.SCORE<=70, 1, 0)) '[70-60]',
CONCAT(ROUND(SUM(IF(SC1.SCORE >60 AND SC1.SCORE<=70, 1, 0))*100/COUNT(SC1.SCORE), 2),'%') 'PERCENT3',
SUM(IF(SC1.SCORE <= 60, 1, 0)) '[<=60]',
CONCAT(ROUND(SUM(IF(SC1.SCORE <=60, 1, 0))*100/COUNT(SC1.SCORE), 2),'%') 'PERCENT4'
FROM SC1 JOIN COURSE C1 USING(CID)
GROUP BY SC1.CID, C1.CNAME;
-- 嵌套子查询
WITH T1 AS (
SELECT SC1.CID,
SUM(IF(SC1.SCORE >85, 1, 0)) AS `[100-85]`,
SUM(IF(SC1.SCORE >70 AND SC1.SCORE<=85, 1, 0)) AS `[85-70]`,
SUM(IF(SC1.SCORE >60 AND SC1.SCORE<=70, 1, 0)) AS `[70-60]`,
SUM(IF(SC1.SCORE <=60, 1, 0)) AS `[<=60]`,
COUNT(SC1.SCORE) AS TOTAL_NUM
FROM SC1
GROUP BY SC1.CID
)
SELECT T1.CID,
C1.CNAME,
T1.`[100-85]`,CONCAT(ROUND(T1.`[100-85]`*100/T1.TOTAL_NUM, 2),'%') AS PERCENT1,
T1.`[85-70]`, CONCAT(ROUND(T1.`[85-70]`*100/T1.TOTAL_NUM, 2),'%') AS PERCENT2,
T1.`[70-60]`, CONCAT(ROUND(T1.`[70-60]`*100/T1.TOTAL_NUM, 2),'%') AS PERCENT3,
T1.`[<=60]`, CONCAT(ROUND(T1.`[<=60]`*100/T1.TOTAL_NUM, 2),'%') AS PERCENT4
FROM T1 JOIN COURSE C1 ON T1.CID = C1.CID
GROUP BY T1.CID, C1.CNAME;结果一致,因为太长,只展示一部分:

24、查询学生平均成绩及其名次
这个比较简单,就是应用窗口函数。
-- 查询学生平均成绩及其名次
SELECT SC1.SID, S1.SNAME, ROUND(AVG(DISTINCT SC1.SCORE),2),
ROW_NUMBER()OVER(ORDER BY(AVG(DISTINCT SC1.SCORE))DESC) AVG_RANK
FROM SC1 JOIN STUDENT S1 USING(SID)
GROUP BY SC1.SID, S1.SNAME;结果: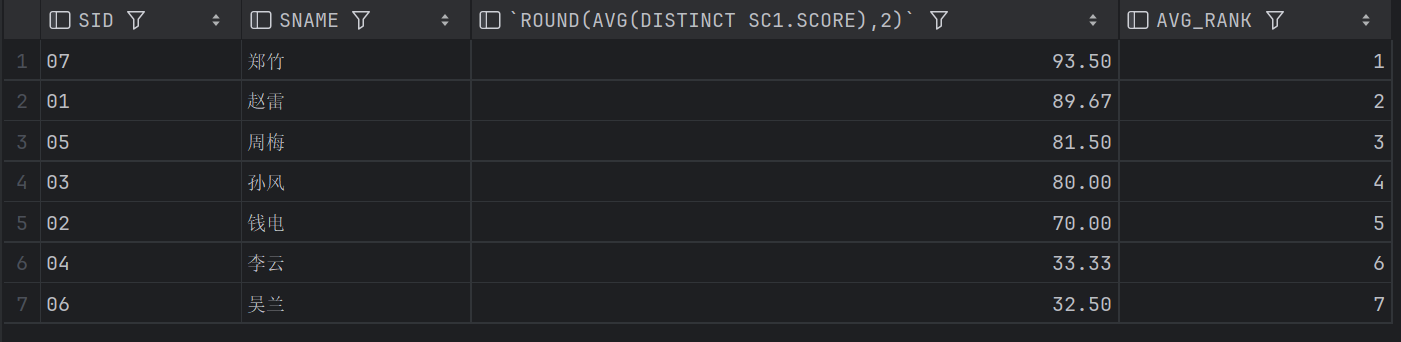
25、 查询各科成绩前 三名的记录(不考虑成绩并列情况)
这里主要是有个子查询给分数进行排名,而后再进行筛选;因为不考虑成绩并列,我们需要使用row_number做排序而非dense_rank或者rank;借鉴了别的同学的一种方式,就是通过count和<的结合完成了筛选的环节,可以看下第二种解法。
-- 查询各科成绩前三名的记录
WITH T1 AS(
SELECT SC1.CID, SC1.SID, SC1.SCORE, ROW_NUMBER()OVER(PARTITION BY SC1.CID ORDER BY SC1.SCORE DESC) SCORE_RANK
FROM SC1
)
SELECT T1.CID, S1.SID, S1.SNAME, T1.SCORE, T1.SCORE_RANK
FROM T1 JOIN STUDENT S1 USING(SID)
WHERE T1.SCORE_RANK <=3
ORDER BY T1.CID, T1.SCORE_RANK;
WITH T1 AS(
SELECT SC1.*
FROM SC1
WHERE (
SELECT COUNT(*)
FROM SC1 SC2
WHERE SC1.CID = SC2.CID AND SC1.SCORE < SC2.SCORE
)<3
)
SELECT T1.CID, S1.SID, S1.SNAME, T1.SCORE
FROM T1 JOIN STUDENT S1 USING(SID)
ORDER BY T1.CID, T1.SCORE DESC;结果些微差异,主要是因为count+<不能剔除重复值。
窗口函数版:
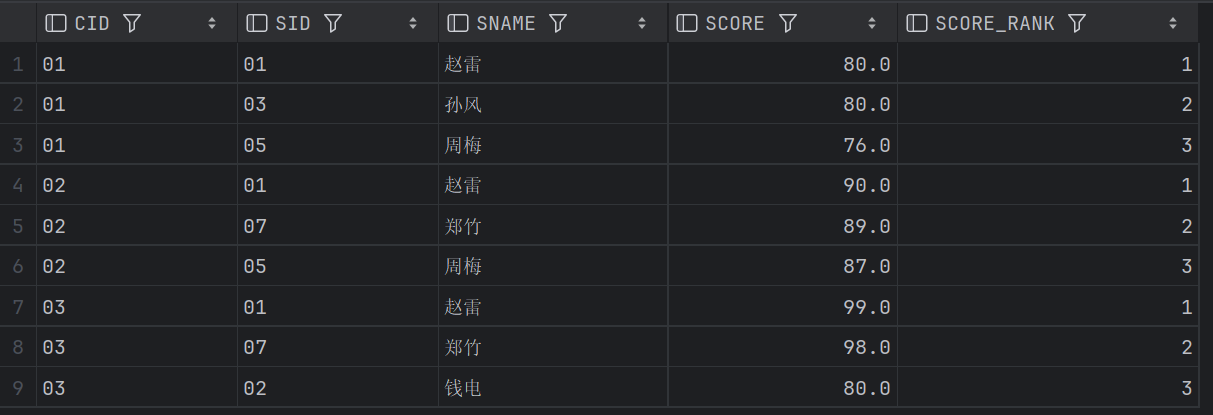
count+<版:
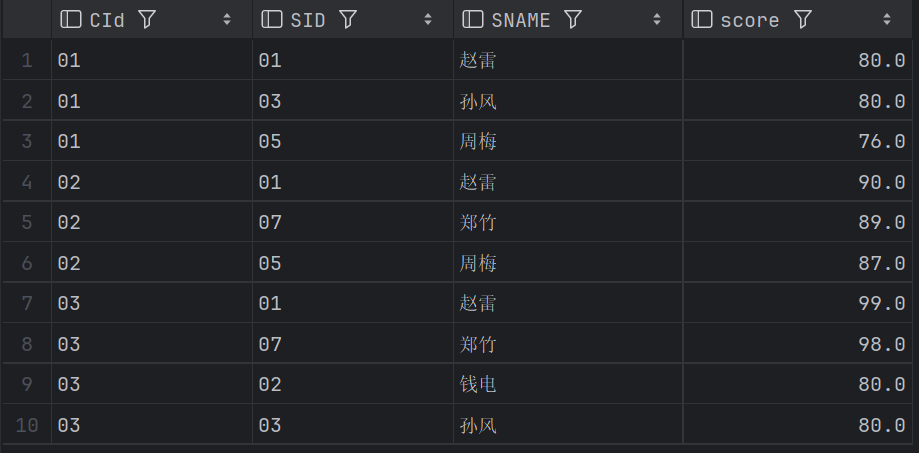
26、查询每门课程被选修的学生数
这个不难,如果需要课程名,直接再连接course表就好。
-- 查询每门课程被选修的学生数
SELECT SC1.CID, COUNT(DISTINCT SC1.SID) CNT_STU
FROM SC1
GROUP BY SC1.CID;结果:
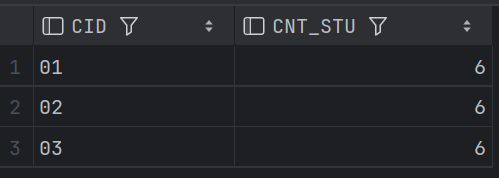
27、查询出只有两门课程的全部学生的学号和姓名
-- 查询出只有两门课程的全部学生的学号和姓名
SELECT SC1.SID, S1.SNAME
FROM SC1 JOIN STUDENT S1 USING(SID)
GROUP BY SC1.SID, S1.SNAME
HAVING COUNT(DISTINCT SC1.CID) = 2;结果:
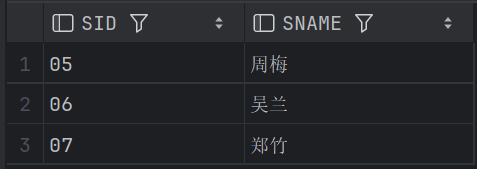
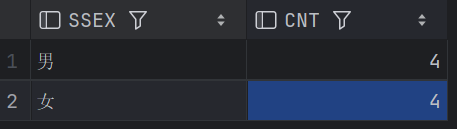
28、查询男生、女生人数
两种解法,结果有差异;
-- 查询男生、女生人数
SELECT SUM(CASE SSEX WHEN '男' THEN 1 ELSE 0 END) MALE_CNT,
SUM(CASE SSEX WHEN '女' THEN 1 ELSE 0 END) FEMALE_CNT
FROM STUDENT;
SELECT SSEX, COUNT(*) AS CNT
FROM STUDENT
GROUP BY SSEX;解法一:

解法二:
29、查询名字中含有"风"字的学生信息
和第4题类似,运用通配符或者正则表达式。
-- 查询名字中含有"风"字的学生信息
SELECT *
FROM STUDENT
WHERE SNAME LIKE '%风%';
-- REGEXP 正则表达式,不一定所有sql都通用
SELECT *
FROM STUDENT
WHERE SNAME REGEXP '.*风.*';
-- 字符串函数
SELECT *
FROM STUDENT
WHERE LOCATE('风', SNAME) > 0;结果一致:

30、查询同名同性学生名单,并统计同名人数
-- 查询同名同性学生名单,并统计同名人数
SELECT SNAME, COUNT(*)
FROM STUDENT
GROUP BY SNAME,SSEX
HAVING COUNT(*)>1;这次是0值,empty。
31、查询1990年出生的学生名单
主要是用到year函数。
-- 查询1990年出生的学生名单
FROM STUDENT
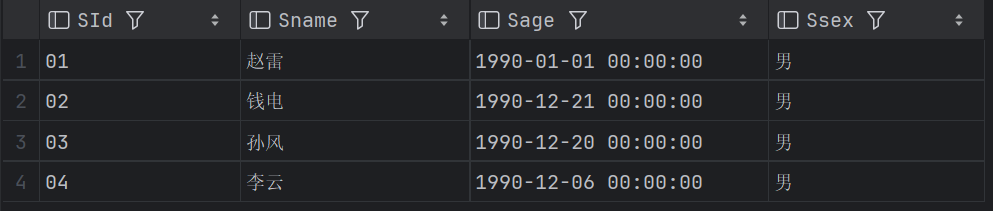
WHERE YEAR(SAGE)='1990';结果:
32、查询平均成绩大于等于85的所有学生的学号、姓名和平均成绩
主要是groupby和having的筛选。
-- 查询平均成绩大于等于85的所有学生的学号、姓名和平均成绩
SELECT SC1.SID, S1.SNAME, ROUND(AVG(SC1.SCORE),2) AVG_SCORE
FROM STUDENT S1 JOIN SC1 USING(SID)
GROUP BY SC1.SID, S1.SNAME
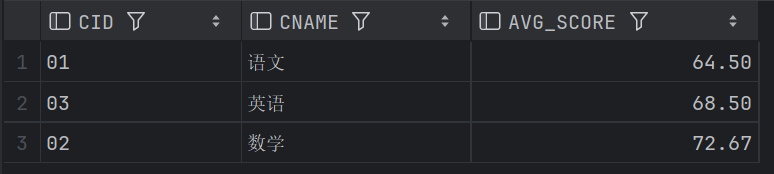
HAVING AVG_SCORE >= 85;结果:

33、查询每门课程的平均成绩,结果按平均成绩升序排序,平均成绩相同时,按课程号降序排列
聚合函数groupby 加上排序函数order by。
-- 查询每门课程的平均成绩,结果按平均成绩升序排序,平均成绩相同时,按课程号降序排列
SELECT SC1.CID, C1.CNAME, ROUND(AVG(SCORE), 2) AVG_SCORE
FROM SC1 JOIN COURSE C1 USING(CID)
GROUP BY SC1.CID, C1.CNAME
ORDER BY AVG_SCORE, CID DESC;结果:
34、查询课程名称为"数学",且分数低于60的学生姓名和分数
主要就是表连接和筛选。
-- 查询课程名称为"数学",且分数低于60的学生姓名和分数
SELECT S1.SID, S1.SNAME, SC1.SCORE
FROM SC1 JOIN STUDENT S1 USING(SID)
JOIN COURSE C1 USING(CID)
WHERE C1.CNAME = '数学' AND SC1.SCORE < 60;结果:

35、查询所有学生的课程及分数情况
主要是case when 和聚合函数的用法
-- 查询所有学生的课程及分数情况
SELECT S1.SID, S1.SNAME,
SUM(CASE C1.CNAME WHEN '语文' THEN SC1.SCORE END) '语文',
SUM(CASE C1.CNAME WHEN '数学' THEN SC1.SCORE END) '数学',
SUM(CASE C1.CNAME WHEN '英语' THEN SC1.SCORE END) '英语'
FROM SC1 JOIN STUDENT S1 USING(SID)
JOIN COURSE C1 USING(CID)
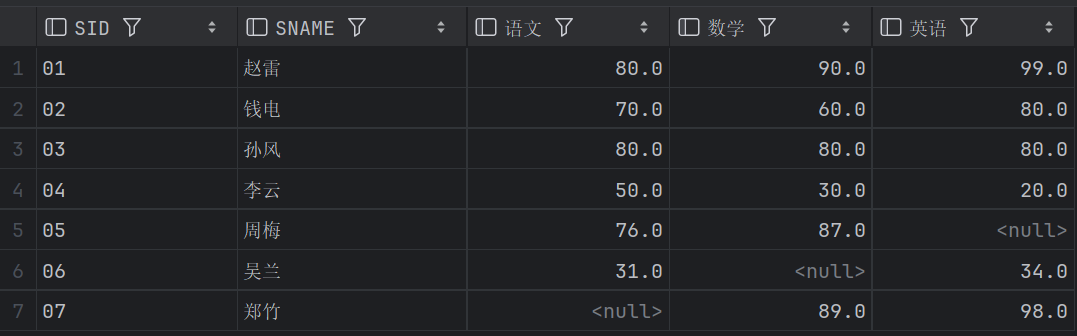
GROUP BY S1.SID, S1.SNAME;结果:
36、查询任何一门课程成绩在70分以上的姓名、课程名称和分数
三种解法,not exists 和 not in搭配筛选,in搭配min(score)>70
-- 查询任何一门课程成绩在70分以上的学生姓名、课程名称和分数
SELECT S1.SNAME, C1.CNAME, SC1.SCORE
FROM SC1 JOIN STUDENT S1 USING(SID)
JOIN COURSE C1 USING(CID)
WHERE NOT EXISTS(
SELECT 1
FROM SC1 SC2
WHERE SC2.SCORE<70 AND SC1.SID=SC2.SID
);
-- 使用in
SELECT S1.SNAME, C1.CNAME, SC1.SCORE
FROM SC1 JOIN STUDENT S1 USING(SID)
JOIN COURSE C1 USING(CID)
WHERE SC1.SID NOT IN(
SELECT SC2.SID
FROM SC1 SC2
WHERE SC2.SCORE<70
);
-- 聚合函数
SELECT S1.SNAME, C1.CNAME, SC1.SCORE
FROM SC1 JOIN STUDENT S1 USING(SID)
JOIN COURSE C1 USING(CID)
WHERE SC1.SID IN(
SELECT SC2.SID
FROM SC1 SC2
GROUP BY SC2.SID
HAVING MIN(SC2.SCORE)>=70
);
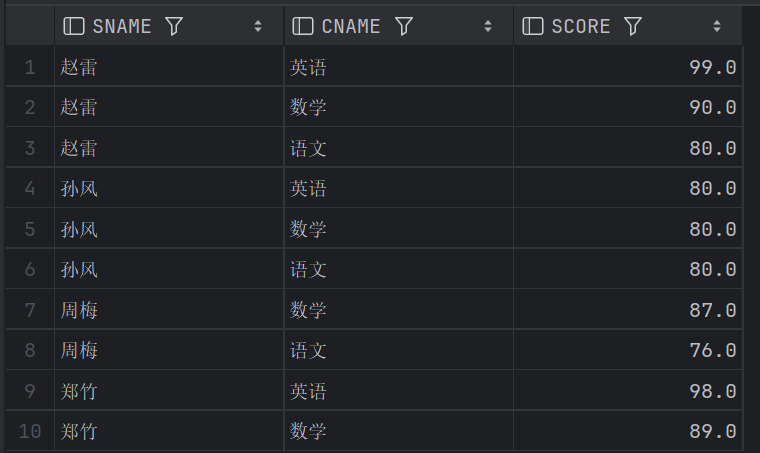
结果一样:
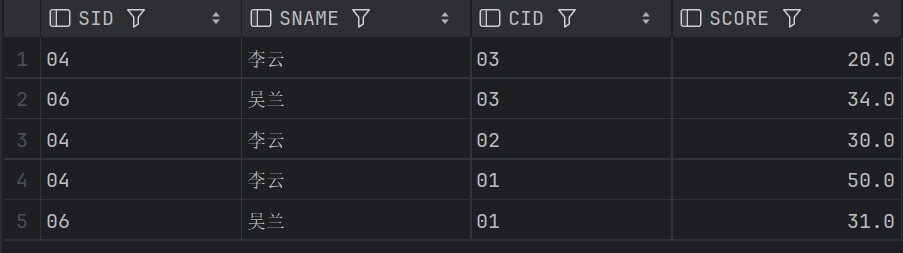
37、查询不及格的学生并按课程号从大到小排列
表连接
-- 查询不及格的学生并按课程号从大到小排列
SELECT S1.SID,S1.SNAME, SC1.CID, SC1.SCORE
FROM SC1 JOIN STUDENT S1 USING(SID)
WHERE SC1.SCORE < 60
ORDER BY SC1.CID DESC;结果:
38、查询课程编号为03且课程成绩在80分以上的学生的学号和姓名
表连接和查询
-- 查询课程编号为03且课程成绩在80分以上的学生的学号和姓名
SELECT S1.SID, S1.SNAME, SC1.CID, SC1.SCORE
FROM STUDENT S1 JOIN SC1 USING (SID)
WHERE SC1.CID = '03' AND SC1.SCORE > 80;结果:

39、求每门课程的学生人数 与26题重复
40、查询选修“张三”老师所授课程的学生中成绩最高的学生姓名及其成绩
我设想采用两种方法,一种是limit 配合desc锁定1个同学;一个是子查询not exists 筛掉不是最高分的那个;另外应该还有一个使用max(score)的用法,我懒得写了。
-- 查询选修“张三”老师所授课程的学生中成绩最高的学生姓名及其成绩
SELECT S1.SNAME, SC1.SCORE
FROM SC1 JOIN STUDENT S1 USING (SID)
JOIN COURSE C1 USING (CID), TEACHER T1
WHERE C1.TID = T1.TID AND T1.TNAME = '张三'
ORDER BY SC1.SCORE DESC
LIMIT 1;
SELECT S1.SNAME, SC1.SCORE
FROM SC1 JOIN STUDENT S1 USING (SID)
JOIN COURSE C1 USING (CID), TEACHER T1
WHERE C1.TID = T1.TID AND T1.TNAME = '张三' AND NOT EXISTS(
SELECT 1
FROM COURSE C2 JOIN SC1 SC2 USING(CID)
JOIN TEACHER T2 USING(TID)
WHERE T2.TNAME = '张三' AND SC2.SCORE > SC1.SCORE
);结果一致:

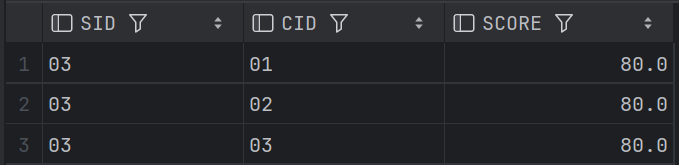
41、查询不同课程成绩相同的学生的学生编号、课程编号、学生成绩
groupby + having count
-- 查询不同课程成绩相同的学生的学生编号、课程编号、学生成绩
SELECT SC1.SID, SC1.CID, SC1.SCORE
FROM SC1
WHERE SC1.SID IN(
SELECT SC2.SID
FROM SC1 SC2
GROUP BY SC2.SID, SC2.SCORE
HAVING COUNT(SC2.CID)>=2
);结果:
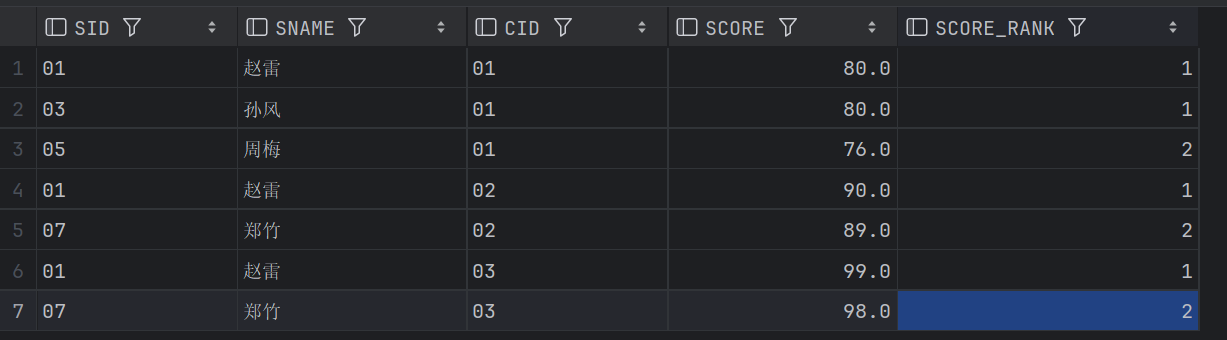
42、查询每门课程成绩最好的前两名
和第22题很接近了
-- 查询所有课程的成绩第2名到第3名的学生信息及该课程成绩
WITH T1 AS (
SELECT SC1.CID, SC1.SID, SC1.SCORE, DENSE_RANK()OVER(PARTITION BY SC1.CID ORDER BY SC1.SCORE DESC) SCORE_RANK
FROM SC1
)
SELECT S1.SID, S1.SNAME, T1.CID, T1.SCORE, T1.SCORE_RANK
FROM T1 JOIN STUDENT S1 USING(SID)
WHERE SCORE_RANK IN (1,2)
ORDER BY CID, SCORE_RANK;
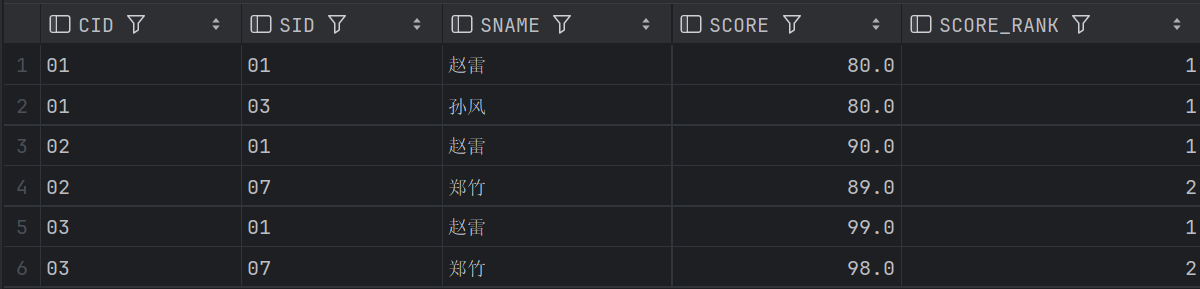
-- 粗暴union
(SELECT SC1.CID, S1.SID, S1.SNAME, SC1.SCORE, DENSE_RANK()OVER(ORDER BY SC1.SCORE DESC) SCORE_RANK
FROM SC1 JOIN STUDENT S1 USING(SID)
WHERE SC1.CID = '01'
ORDER BY SCORE DESC
LIMIT 2)
UNION ALL
(SELECT SC1.CID, S1.SID, S1.SNAME, SC1.SCORE, DENSE_RANK()OVER(ORDER BY SC1.SCORE DESC) SCORE_RANK
FROM SC1 JOIN STUDENT S1 USING(SID)
WHERE SC1.CID = '02'
ORDER BY SCORE DESC
LIMIT 2)
UNION ALL
(SELECT SC1.CID, S1.SID, S1.SNAME, SC1.SCORE, DENSE_RANK()OVER(ORDER BY SC1.SCORE DESC) SCORE_RANK
FROM SC1 JOIN STUDENT S1 USING(SID)
WHERE SC1.CID = '03'
ORDER BY SCORE DESC
LIMIT 2);
结果略有差异,主要在于limit 和筛选导致的差异。
结果1:
结果2:
43、统计每门课程的学生选修人数(超过5人的课程才统计)。要求输出课程号和选修人数,查询结果按人数降序排列,若人数相同,按课程号升序排列
第26题进阶版,不难
-- 统计每门课程的学生选修人数(超过5人的课程才统计)
-- 要求输出课程号和选修人数,查询结果按人数降序排列,若人数相同,按课程号升序排列
SELECT SC1.CID, COUNT(DISTINCT SC1.SID) CNT_STU
FROM SC1
GROUP BY SC1.CID
HAVING CNT_STU >= 5
ORDER BY CNT_STU DESC, SC1.CID;结果:
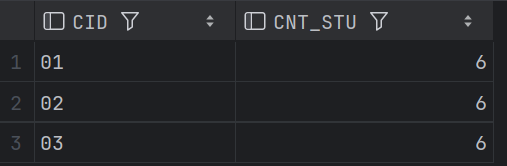
44、检索至少选修两门课程的学生学号
和27题类似
-- 检索至少选修两门课程的学生学号
SELECT SC1.SID, S1.SNAME
FROM SC1 JOIN STUDENT S1 USING(SID)
GROUP BY SC1.SID, S1.SNAME
HAVING COUNT(DISTINCT SC1.CID) >= 2;结果:
45、查询选修了全部课程的学生信息
和第10题反过来了,我采用了两种解法,一种是子查询,一种是直接的把select嵌套进where语句里。
-- 查询选修了全部课程的学生信息
SELECT S1.*
FROM STUDENT S1
WHERE S1.SID IN (
SELECT SC1.SID
FROM SC1
GROUP BY SC1.SID
HAVING COUNT(DISTINCT SC1.CID) = (
SELECT COUNT(DISTINCT SC2.CID)
FROM SC1 SC2
)
);
SELECT S1.*
FROM STUDENT S1
WHERE (SELECT COUNT(DISTINCT CID) FROM SC1) = (SELECT COUNT(DISTINCT CID) FROM SC1 SC2 WHERE S1.SID =SC2.SID);结果一致:
46、查询各学生的年龄
-- 查询各学生的年龄
SELECT SID, SNAME, SAGE,
IF(MONTH(CURRENT_DATE())<MONTH(SAGE) OR (MONTH(CURRENT_DATE())=MONTH (SAGE) AND DAY(CURRENT_DATE()<DAY(SAGE))),
YEAR(CURRENT_DATE())-YEAR(SAGE)-1, YEAR(CURRENT_DATE())-YEAR(SAGE)) AGE
FROM STUDENT;结果不再呈现。
47、查询本周过生日的学生
-- 查询本周过生日的学生
SELECT S1.*
FROM STUDENT S1
WHERE
DATEDIFF(
STR_TO_DATE(CONCAT(YEAR(CURDATE()), '-', DATE_FORMAT(SAGE, '%m-%d')), '%Y-%m-%d'),
CURDATE()
) BETWEEN 0 AND 6;总感觉不对,但暂时也写不出来更对的,先这样把。
48、查询下周过生日的学生
-- 查询本周过生日的学生
SELECT S1.*
FROM STUDENT S1
WHERE
DATEDIFF(
STR_TO_DATE(CONCAT(YEAR(CURDATE()), '-', DATE_FORMAT(SAGE, '%m-%d')), '%Y-%m-%d'),
CURDATE()
) BETWEEN 7 AND 13;同上,无结果
49、查询本月过生日的学生
单纯是date函数和year函数
-- 查询本月过生日的学生
SELECT S1.*
FROM STUDENT S1
WHERE MONTH(S1.SAGE) = MONTH(CURRENT_DATE());50、查询下一个月过生日的学生
和上一题差异不大
-- 查询下月过生日的学生
SELECT S1.*
FROM STUDENT S1
WHERE MONTH(S1.SAGE) = MOD(MONTH(CURRENT_DATE())+1,12);

















 963
963




 到【灌水乐园】发言
到【灌水乐园】发言







