



一:redis为什么这么快
- 纯内存操作
- 单线程 采用单线程,避免了不必要的上下文切换和竞争条件,也不存在多进程或者多线程导致的切换而消耗 CPU,不用去考虑各种锁的问题,不存在加锁释放锁操作,没有因为可能出现死锁而导致的性能消耗;
- 问:单线程是否没有充分利用 CPU 资源呢 答:因为 Redis 是基于内存的操作,CPU 不是 Redis 的瓶颈,Redis 的瓶颈最有可能是机器内存的大小或者网络带宽。
- IO多路复用
- 问:那么现在我们在再来看一下Redis单线程是如何处理那么多并发客户端连接?为什么单线?为什么那么快? 答案:Redis 是跑在单线程中的,所有的操作都是按照顺序线性执行的,但是由于读写操作等待用户输入或输出都是阻塞的,所以 I/O 操作在一般情况下往往不能直接返回,这会导致某一文件的 I/O 阻塞导致整个进程无法对其它客户提供服务,而 I/O 多路复用就是为了解决这个问题而出现。
- 特殊设计的数据结构
二:redis 数据类型和底层实现
- 字符串 embstr和sds以及long
- hash ziplist(压缩链表)和hashmap
- 列表 ziplist(压缩链表)和双向链表
- 集合 数字集合,hashmap
- 有序集合 压缩链表和跳跃表 当数据列表元素小于128个,并且所有元素成员的长度都小于64字节时,使用压缩列表存储
字符串底层实现细节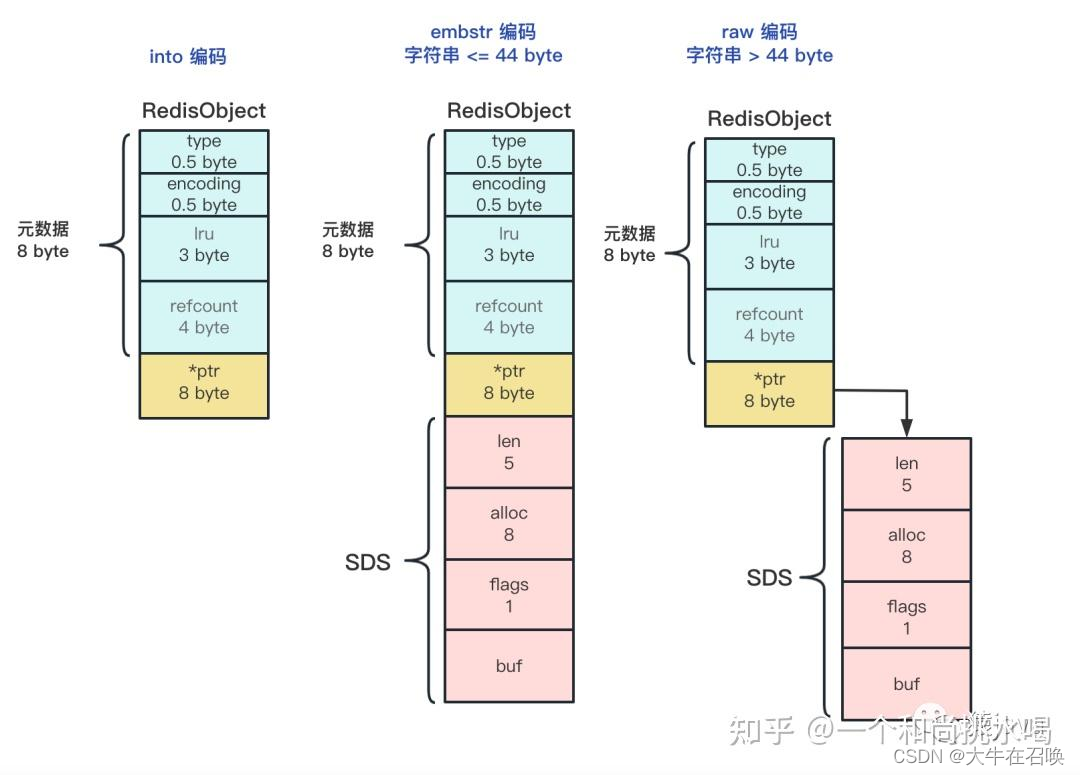
- OBJ_ENCODING_INT:当保存数值型字符串时,会将它转换为 Long 类型整数,redisObject 中的指针直接赋值为整数数据,这样就不用额外的指针指向整数。这种方式称为 int 编码方式。
- OBJ_ENCODING_EMBSTR:当保存字符串数据,且字符串 <=44 字节时,redisObject 中的元数据、指针和 SDS 是一块连续的内存区域,这样可以避免内存碎片,同时内存申请和释放都只需要调用一次内存操作函数。这种方式称为 embstr 编码方式。
- OBJ_ENCODING_RAW:当保存字符串数据,且字符串大于 44 字节时,Redis 不再把 SDS 和 redisObject 放在一起,而是给 SDS 分配独立的空间,并用指针指向 SDS 结构。这种方式称为 raw 编码模式。
-
空间预分配:当空间不足时,如果目标空间 <1MB,则扩容为目标空间的 2 倍
惰性空间释放:当 SDS 字符串缩短时, 空余出来的空间并不会直接释放,而是会被保留,只修改 ‘\0’字符的位置和 len 字段值
hashmap底层实现细节
- 数据结构
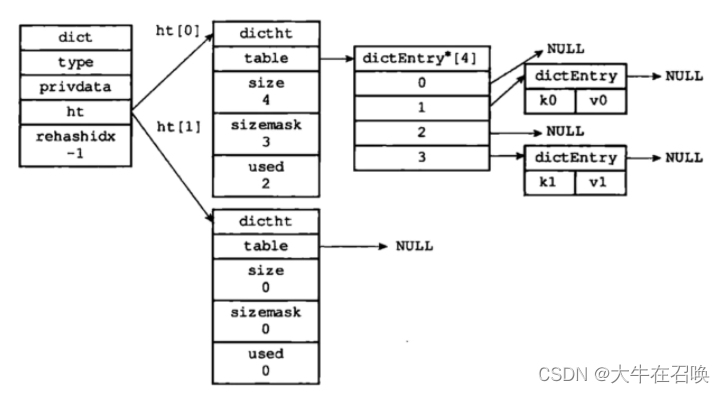
- Redis 的散列表 dict 由数组 + 链表构成,数组的每个元素占用的槽位叫做哈希桶,当出现散列冲突的时候就会在这个桶下挂一个链表,用“拉链法”解决散列冲突的问题。简单地说就是将一个 key 经过散列计算均匀的映射到散列表上
- dict
ht[2],两个hash表,ht[0] 为主,ht[1] 在渐进式 hash 的过程中才会用到。rehashidx,这是一个辅助变量,用于记录rehash过程的进度,以及是否正在进行rehash等信息,当rehashidx=-1时,表示该dict此时没有进行rehash过程 - dictht 数组 table 指向一个数组; size 数组的大小;used 已经使用的;
- dictEntry 链表结构
*next指向下一个节点指针,当散列表数据增加,可能会出现不同的 key 得到的哈希值相等,也就是说多个 key 对应在一个哈希桶里面,这就是哈希冲突。Redis 使用拉链法,也就是用链表将数据串起来-
*key指针指向键值对中的键,实际上指向一个 SDS 实例。 -
v是一个 union 联合体,表示键值对中的值
- 负载因子
- 负载因子 = 散列表存储 dictEntry 节点数量 / 散列表桶个数
- 扩容过程
- 哈希表的默认长度为4,每次扩容,扩大一倍。
- 当负载因子超过一定阈值时,Redis会自动对哈希表进行扩容操作,以保证哈希表的性能。
- 当Redis没有进行
BGSAVE相关操作,且负载因子>=1时,Redis会自动对哈希表进行扩容操作 - 如果正在执行
BGSAVE和BGREWRITEAOF指令的情况下,负载因子>=5时强行扩容。
- 缩容过程
- 当负载因子<0.1的时候,进行缩容
- ,Redis会新建一个小于等于原哈希表大小的哈希表,然后将原哈希表中的所有键值对rehash到新哈希表中,
- 字典会同时使用ht[0]和ht[1]两个哈希表,所以在缩容操作进行期间,字典的删除(delete)、查找(find)、更新(update)等操作会在两个哈希表上进行
- rehash的过程
- Redis采用了渐进式
rehash的平滑扩容机制,它通过两个哈希表+渐进式rehash的方式来实现扩容机制,从而实现平滑扩容,又不阻塞读写。 - 为ht[1]哈希表分配足够的内存空间,其大小取决于当前哈希表当前的负载因子和已保存节点数(即:
ht[0].used) - 维护
rehashidx变量:这是一个索引计数器,表示当前要迁移的桶的位置。初始值为0,每次迁移一个桶后+1,直到等于原哈希表大小时,表示rehash完成。 - 在ht[0]中取出一个键值对进行
rehash,并将其插入到ht[1]中,完成后rehashix的值需要+1。 - 重复步骤2,直到ht[0]中所有键值对都被rehash到ht[1]中。
- 完成
rehash后,即当rehashidx等于原哈希表大小时,将rehashidx属性设为-1,释放ht[0]的内存空间,将ht[1]设置为ht[0],并在ht[1]中创建一个空白的哈希表,为下一次rehash做准备。 - 删除、修改和查找可能会在两个散列表进行,第一个散列表没找到就到第二个散列表进行查找。但是增加操作只会在新的散列表上进行
- 批迁移数据:在每次执行读写操作时,只迁移一个桶(链表)的数据,而不是一次性迁移所有数据。这样可以避免长时间占用CPU资源,造成阻塞。同时,迁移的速度也会随着读写操作的频率而增加,保持与负载因子的平衡。
- Redis采用了渐进式
ziplist的底层实现细节
- 数据结构
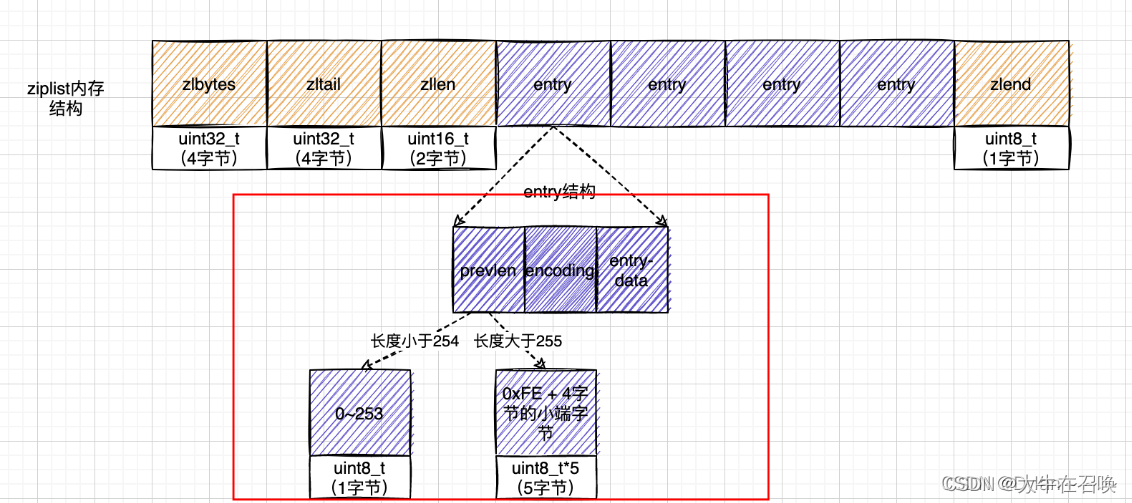
- ziplist
-
zlbytes:uint32_t,记录整个压缩列表占用对内存字节数,包括zlbtes占用的4字节;
-
zltail:uint32_t,记录压缩列表「尾部」节点距离起始地址由多少字节,也就是列表尾的偏移量,用于支持链表从尾部弹出或反向(从尾到头)遍历链表。
-
zllen:uint16_t,记录压缩列表包含的节点数量
-
zlend:标记压缩列表的结束点,固定值 0xFF(十进制255)
-
- entry
- prevlen:存储上一个节点的长度,用以由后往前回到上一个节点
- encoding:节点的content属性所保存数据的类型以及长度
- entry-data:节点数据;可以是字符串或整数
- ziplist
- 这样设计的优点
- 压缩链表ziplist是一个经过特殊编码的双向链表,它的设计目标就是为了提高存储效率
- 申请一块内存一起存储,节省内容
- 第一个和最后一个节点的时间复杂读是o(1)。其他是o(n)
- 缺点是:如果保存的元素数量增加了,或是元素变大了,会导致内存重新分配,最糟糕的是会有连锁更新的问题数量; 数据过多,导致链表过长,可能影响查询性能
- 连锁更新问题
- ZipList的每个Entry都包含previous_entry_length来记录上节点的大小,长度是1个或5个字节:
- 如果前一节点的长度小于254字节,则采用1个字节来保存这个长度值
如果前一节点的长度大于等于254字节,则采用5个字节来保存这个长度值 - 如果前一个节点的长度超过254,导致后面的节点的前节点的长度previous_entry_length字符连锁变更长度。
- 种在特殊情况下产生的连续多次空间扩展操作就叫做【连锁更新】
跳跃表底层实现细节
- 数据结构
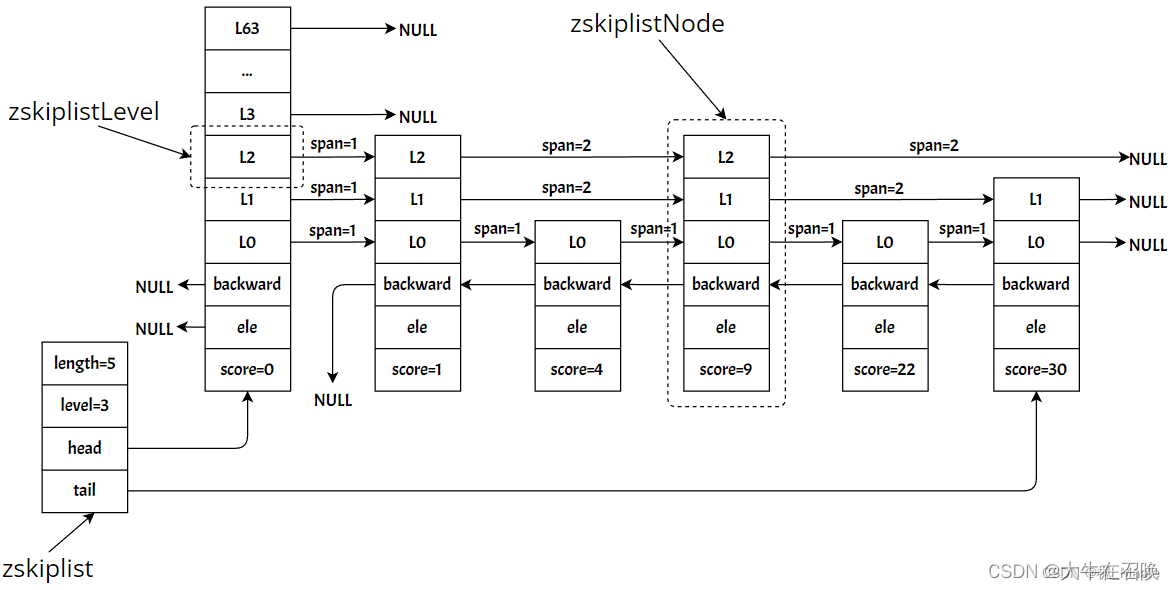
- zskiplist
-
header:指向跳表的头节点
-
tail:指向跳表的尾节点
-
length:跳表的节点的个数(不包含头节点)
-
level:跳表的节点的最大高度(不包括头节点)
-
- zskiplistNode
-
ele:该节点所存储的字符串
-
score:该节点排序的分值
-
backward:当前节点最底层的前一个节点,头节点和第一个节点的backward指向NULL
-
level:每个zskiplistNode节点都有多层,一层为一个zskiplistLevel,一个zskiplistNode的所有 zskiplistLevel用一个level数组存储
-
-
zskiplistLevel
- forward:指向同一层的下一个节点,为节点的forward指向NULL
- span:forward指向的节点与本节点之间的节点的个数,span越大说明跳过的节点的个数越多
- zskiplist
- 如何实现查询
- 如何查找
- 如何插入
- 如何删除
- 如何建立索引
- 时间复杂度 时间复杂度可以达到O(lgN)-同二分查找,跳表是一个典型的用空间换时间的优化案例
三:持久化方式
- RDB (快照) RDB持久性以指定的时间间隔执行数据集的时间点快照。
- 步骤
- 是 Redis 持久化到磁盘上的数据文件的格式,重点内容默认的文件名是 dump.rdb。
- Redis 会在指定的时间间隔内将内存中的数据集快照写入磁盘,它恢复时是将快照文件直接读到内存里
- Redis会单独创建(fork)一个子进程来进行持久化,会先将数据写入到一个临时文件中,待持久化过程都结束了,再用这个临时文件替换上次持久化好的文件。
- 整个过程中,主进程是不进行任何IO操作的,这就确保了极高的性能。
- 触发方式
- 配置Redis,当满足“N秒内数据集至少有M个改动”的条件时,自动保存一次数据集
- 还可以手动执行命令来生成RDB快照,执行save或bgsave命令
- 优缺点
- RDB的缺点是最后一次持久化后的数据可能丢失。
- 恢复数据,RDB方式要比AOF方式更加的高效
- 适合大规模的数据恢复
- 二进制文件,比较紧凑,节省磁盘空间
- 在一定间隔时间做一次备份,所以如果redis意外down掉的话,就会丢失最后一次快照后的所有修改。
- fork的时候,内存中的数据被克隆了一份,大致2倍的膨胀性需要慎重考虑。
- AOF (追加写文件):AOF持久性记录服务器接收到的每个写入操作
- 步骤
- AOF文件是一个只进行追加的日志文件;
- Redis 可以在AOF文件体积变得过大时,自动地在后台对AOF进行重写;
- 对于相同的数据集来说,AOF文件的体积通常要大于RDB文件的体积;
- 根据所使用的 fsync 策略,AOF的速度可能会慢于 RDB。
- 方式(每秒触发一次,每次更新触发一次,不触发)
-
appendfsync always:每次有新命令追加到 AOF 文件时就执行一次 fsync ,非常慢,也非常安全。
-
appendfsync everysec:每秒 fsync 一次,足够快,并且在故障时只会丢失 1 秒钟的数据。
-
appendfsync no:从不 fsync ,将数据交给操作系统来处理。更快,也更不安全的选择。
-
- 优缺点
- 数据的一致性高。
- 备份机制更稳健,丢失数据概率更低。
- 可读的日志文本,通过操作AOF稳健,可以处理误操作。
- 相同数据量的 aof 文件相比于 rdb 文件占用的磁盘空间较大。
- redis 运行 aof 文件的速度比 rdb 文件慢,恢复备份速度要慢。
- 每次读写都同步的话,有一定的性能压力。
四:过期的key回收实现方式
- 定时检查
- 频率 Redis 默认会每秒进行十次过期扫描,过期扫描不会遍历过期字典中所有的 key
- 从过期字典中随机 20 个 key;
- 删除这 20 个 key 中已经过期的 key;
- 如果过期的 key 比率超过 1/4,那就重复步骤 1;
- 惰性检查
- 在客户端访问key时再进行检查如果过期了就立即删除
- 超过最大内存(最少使用,随机等)
配置maxmemory来限制内存超出期望大小- 尝试淘汰设置了过期时间的 key,最少使用的 key 优先被淘汰。
- 尝试淘汰设置了过期时间的 key,ttl 越小越优先被淘汰
- 尝试淘汰设置了过期时间的 key,随机删除
- 全部的key,ttl 越小越优先被淘汰
- 全部的key,随机删除
五:redis高可用方案
redis如何实现复制
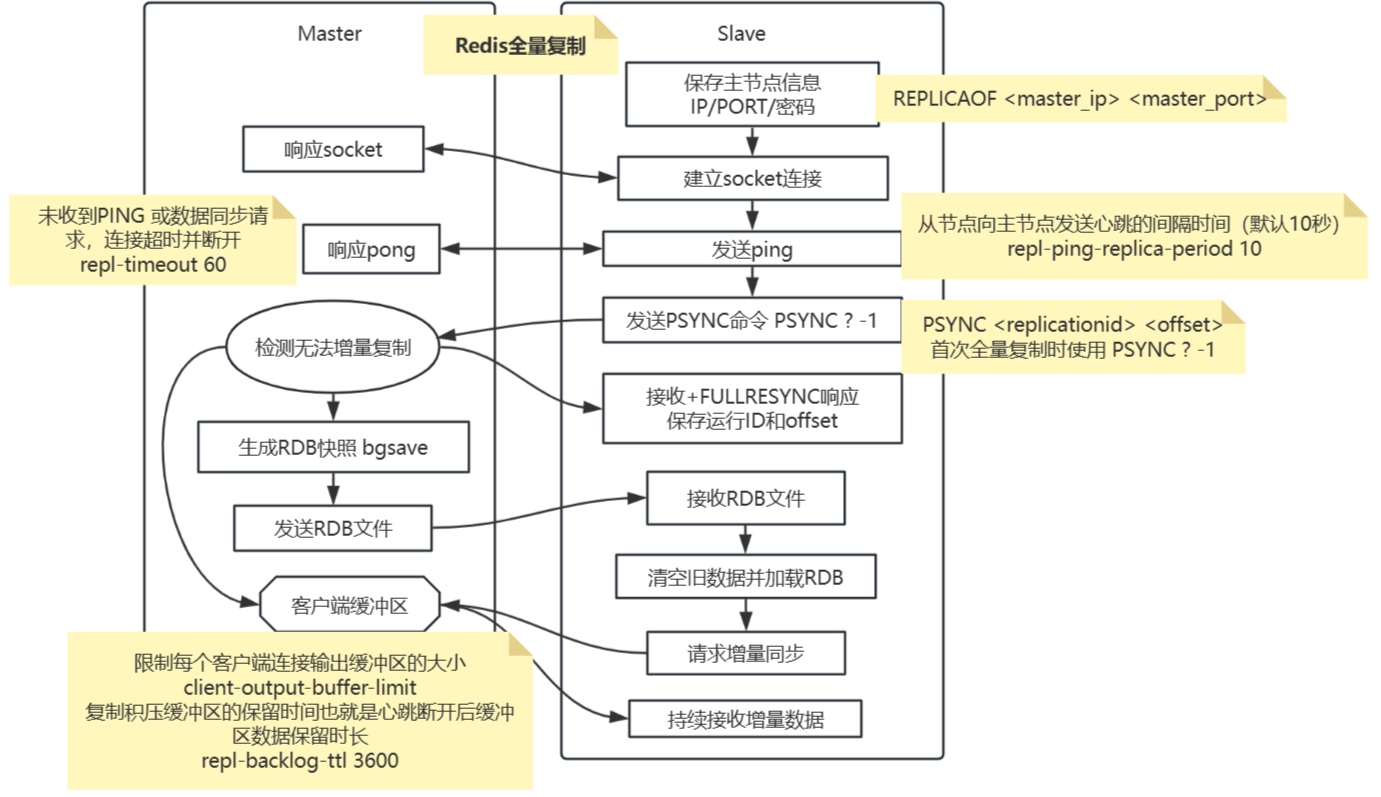
- 全量复制的步骤
- 什么场景会触发全量复制
- 首次建立主从关系:从节点首次执行REPLICAOF命令连接主节点。
- 数据差异过大:从节点落后主节点太多(超出复制积压缓冲区范围)。
- 复制ID不匹配:主节点重启导致复制ID变更,从节点无法增量同步。
- 流程
如果为 master 配置了一个 slave,不管这个 slave 是否是第一次连上 master,它都会发送一个
PSYNC命令给 master请求复制数据。master 收到
PSYNC命令后,会在后台进行数据持久化通过 bgsave 生成最新的 rdb 快照文件;持久化期间,master 会继续接收客户端的请求,master 会把可能修改数据集的请求缓存在内存中。
当持久化进行完毕以后,master 会把这份 rdb 文件数据集发送给 slave,slave 会把接收到的数据进行持久化生成 rdb,然后加载到内存。然后,master 在将之前缓存在内存中的命令发送给 slave。
当 master 与 slave 之间的连接由于某些原因而断开时,slave 能够自动重连 master,如果 master 收到了多个 slave 的并发连接请求,master 只会进行一次持久化,而不是一个连接创建一次快照,然后再把这一份持久化的数据发送给多个并发连接的 slave。
- 什么场景会触发全量复制
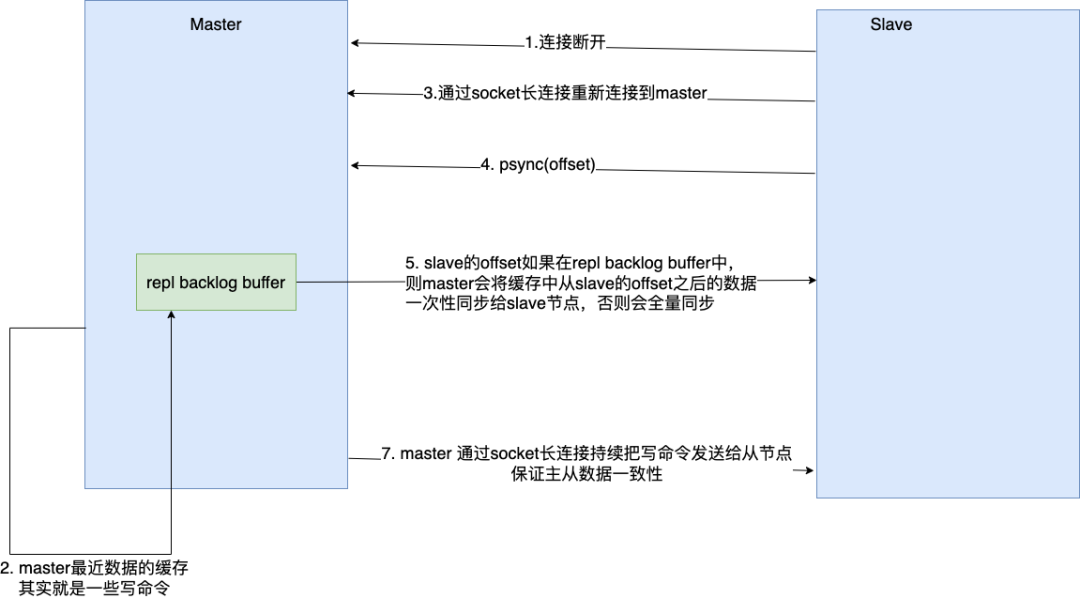
- 部分复制的步骤
- 流程
- 当 master 和 slave 断开重连后,一般都会对整份数据进行复制。但从 Redis2.8 版本开始,Redis 改用可以支持部分数据复制的命令
PSYNC去 master 同步数据,slave 与 master 能够在网络端口重连后只进行部分数据复制。-
master 会在其内存创建一个复制数据用的缓存队列,缓存最近一段时间的数据,master 和它所有的 slave 都维护了复制的数据下标 offset 和 master 的进程 id,因此,当网络连接断开后,slave 会继续请求 master 继续进行未完成的复制,从所记录的数据下标开始。
如果 master 进程 id 变化了,或者从节点数据下标 offset 太旧,已经不在 master 的缓存队列里了,那么将会进行一次全量数据的复制。
缓冲区大小修改配置:
repl-backlog-size 1mb
-
- 当 master 和 slave 断开重连后,一般都会对整份数据进行复制。但从 Redis2.8 版本开始,Redis 改用可以支持部分数据复制的命令
- 流程
高可用架构
主从复制存在的问题。
1.一旦主节点故障,需要手动将从晋升为主,修改应用方的主节点地址,需要人工干预
2.主节点的写能力受到单机的限制
3.主节点的存储能力受到单机的限制
其中问题1就是Redis的高可用问题,使用Sentinel;问题2、3是分布式问题,使用Redis cluster
- 哨兵 Sentinel
- 当主节点出现故障时,Redis Sentinel能自动完成故障发现和故障转移,并通知应用方,从而实现高可用。
- 如何识别故障: ping方式进行心跳测试
- 主挂了怎么选举: 共识算法 raft、拜占庭算法
- sentinel 选举过程
- 集群 Cluster
- 当遇到单机内存、并发、流量等瓶颈时,可以采用Cluster架构方案达到负载均衡的目的。其是无中心节点的p2p架构,通过流言协议(Gossip)交换集群的信息,比如节点负责哪些数据,是否出现故障等转态信息。
-
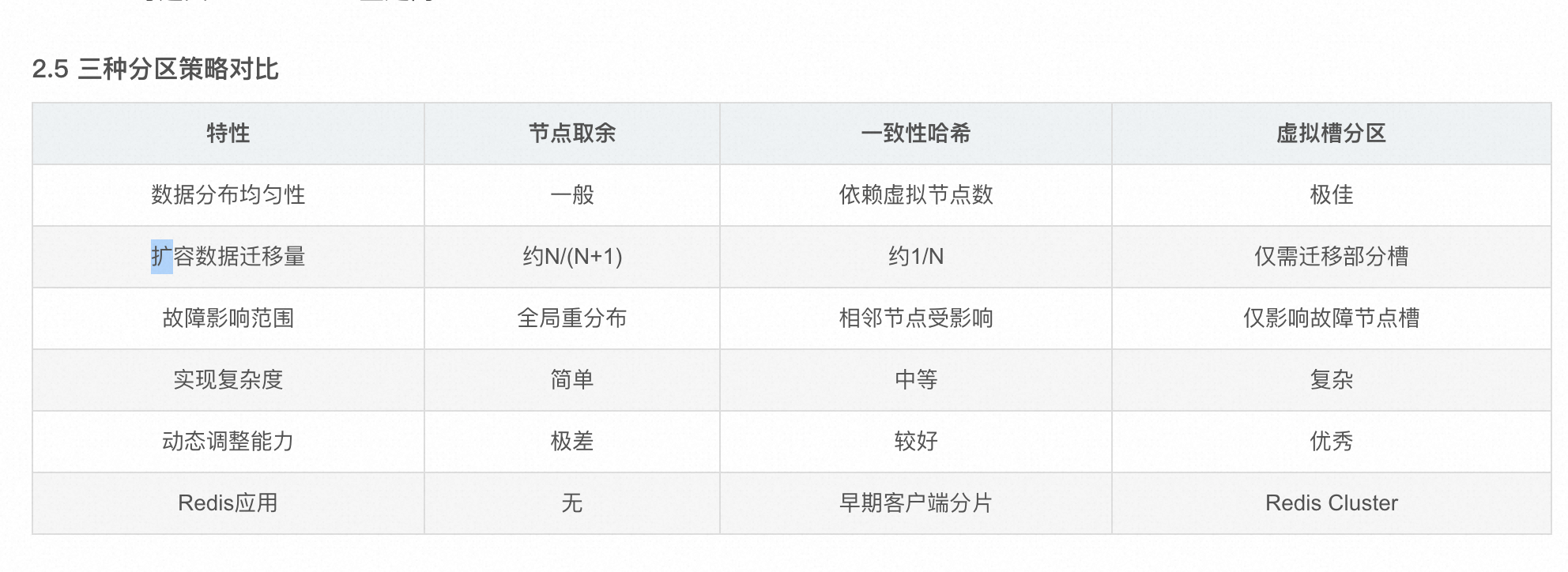
数据分区(虚拟槽分区)
- Redis Cluster采用虚拟槽分区,将16384个槽划分给节点,每一个节点负责维护一部分槽以及槽映射的键值数据。所有的键根据哈希函数映射到0-16383整数槽内。 计算公式:slot=CRC16(key) & 16383。
- 节点取余分区的问题,即当增加或减少节点时,原来节点中的80%的数据会进行迁移操作,对所有数据重新进行分布
- 一致性hash的问题是受临近节点的影响,通过引入虚拟节点解决数据倾斜问题
-
-
集群伸缩
redis集群提供了灵活的节点扩容和收缩方案。在不影响集群对外服务的情况下,可以为集群添加节点也可以下线部分节点进行缩容。扩容和收缩就是槽和对应数据在不同节点之间的灵活移动的过程。 - 故障监测流程
- 节点A标记节点B为"主观下线" (PFail) →
- 通过Gossip传播 →
- 多数主节点确认 →
- 标记为"客观下线" (Fail) →
- 触发故障转移
-
故障转移机制
- 资格检查:
- 选举准备
- 投票选举:(超过半数的节点)
- 角色切换:(从节点提升为主节点,其它从节点复制数据)
六:redis事务
七:redis的使用
分布式锁
- redis单实例中实现分布式锁
- SETNX 或者结合 lua 实现 ;
- 由于主从同步是异步的,有可能会丢数据,进程刚刚拿到锁,由于丢了数据,导致其它进程也拿到了锁
- 多节点redis实现的分布式锁算法(RedLock):有效防止单点故障
-
RedLock(Redis Distributed Lock) 是 Redis 官方提出的一种 分布式锁算法,
-
实现步骤
- 获取当前时间:以毫秒为单位记录当前时间。
- 尝试获取锁:依次向多个Redis实例发送SET命令,尝试获取相同的锁。每个SET命令都带有过期时间,以防止死锁。
- 计算获取锁的时间:使用当前时间减去开始获取锁的时间,得到获取锁所消耗的总时间。
- 判断锁是否获取成功:如果在大多数Redis实例上成功获取了锁,并且获取锁的时间小于锁的过期时间,则认为锁获取成功。
- 释放锁:如果因为某些原因未能成功获取锁,或者锁已经过期,需要在所有Redis实例上释放锁。
-
优缺点
-
多实例冗余
-
高容错性:
-
复杂性
-
网络延迟与时钟偏差:Redlock 算法依赖于多个 Redis 实例之间的网络通信,这可能受到网络延迟的影响,尤其是在跨数据中心部署时,可能会导致一些锁的获取不稳定。RedLock 依赖 系统时钟 判断锁的过期时间
-
-
bitmap
bitmap,也叫位图,是一种实现对位的操作的‘数据结构’,用一个bit位来表示一个东西的状态,我们都知道bit位是二进制,所以只有两种状态,0和1。bitmap是属于redis的string数据类型,Redis中一个字符串类型的值最多能存储512MB 的内容,每个字符串由多个字节组成,每个字节又由8个Bit 位组成,所以它存储上限为 2的32次方
redis 已经原生支持了位图 setbit getbit等
用法:
- 布隆过滤器。
- 数据统计(如:用户活跃数统计)。
- 数据标记(如:用户签到、消息标记已读
布隆过滤器
布隆过滤器(Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都比一般的算法要好得多,缺点是有一定的误识别率和删除困难。
布隆过滤器添加元素
- 将要添加的元素给k个哈希函数
- 得到对应于位数组上的k个位置
- 将这k个位置设为1
布隆过滤器查询元素
- 将要查询的元素给k个哈希函数
- 得到对应于位数组上的k个位置
- 如果k个位置有一个为0,则肯定不在集合中
- 如果k个位置全部为1,则可能在集合中
配合lua实现库存的数据一致性
lua脚本在Redis中是原子执行的,这意味着在执行过程中,不会有其他命令插入。特别是在需要原子性执行多个命令时
高并发下的缓存挑战 穿透,击穿,雪崩
- 穿透
- 在缓存穿透中,数据对缓存和数据库都不存在,高并发或攻击会导致数据库崩溃。
- 防御:缓存空值、使用布隆过滤器进行前置校验,不在白名单的直接返回空值、业务前置校验
- 击穿
- 某个热点key失效,。这时,所有请求都会被转发至数据库,使得数据库承受巨大的压力,甚至可能因此崩溃
- 防御:使用互斥锁(如Mutex Key)来确保只有一个线程构建缓存、对于热点数据,可以选择不设置过期时间、多级缓存
- 雪崩
- 当缓存中大量热点数据拥有相同的失效时间时,便有可能导致这些数据在同一时刻集体失效。这时,所有请求都会被转发至数据库,使得数据库承受巨大的压力,甚至可能因此崩溃
- 防御:在预发击穿的基础上,再让过期时间尽量随机分布。
八:redis的内容优化
- redis的k,v的占用内存的计算 https://blog.51cto.com/u_16099276/6668022
- redis中会有一个全局的哈希表存储键值对,哈希表中每一项存储的是一个dictEntry结构(占用24字节);key是SDS结构占用12字节;val是rredisObj+SDS占用(16或者n+9+12)字节
- 每个robj占用((4b(type)+4b(encoding)+24b(lru))/8)+4(refcount)+8(ptr) = 16字节
- SDS的长度是4(len)+4(free)+3(“aaa”)+1(‘\0’) = 12或者0(数字的话存在prt里面)
-
对字符串的robj的内存占用公式可以总结为”N+9+16”,N为字符串长度 或者是 16(纯数字)
- 一个dictEntry的大小是8(key)+8(v)+8(next) = 24字节,
- 在执行”set aaa bbb”命令后,redis会用24(dictEntry)+12(sds(“aaa”))+28(robj(“bbb”)) = 64字节来存储
- 在执行”set aaa 10000”命令后,redis会用24(dictEntry)+12(sds(“aaa”))+16(robj(“10000”)) = 52字节来存储(redis对整数10000之内robj创建了shared object,也就是说如果这里不是10000而是123的话,不会为123新创建robj而是直接增加shared object中已有123的robj的计数,这样空间占用更小)
- 内存压缩实战:
- 使用hash结构(压缩链表)替代k,v结构;目标:节约redisObject的数量。从而节约内存;ziplist会比hashtable与ziplist节省跟多的内存;连续内存可以更快的载入;数据量小的时候读写效率差异不大。
-
Hash结构使用ziplist作为底层存储的两个条件是:
-
所有的键与值的字符串长度都小于64字节的时候
-
键与值对数据小于512个
-
-
计算过程,程序中计算hash的key,找到hash后,根据原始key直接找到值。
-
bucket_count = 10亿 / 512 = 195W;
-
bucket_id = CRC32(人群包ID + "_" + 设备ID) % 200W
-
九:redis大key和热key问题是什么?怎么解决
拆分,就是拆分。
十:redis异地多活怎么解决数据同步的延迟问题
十一:场景问题
- Q:为什么是16384个槽?
-
A权衡考虑:
足够分散数据(16K足够)
心跳包携带完整槽信息(16K槽需要2KB空间)
集群规模限制(理论上最大1000节点)
-
-
Q网络分区如何处理?
-
A:通过cluster-require-full-coverage配置:
yes(默认):必须所有槽可用才能服务
no:允许部分分区继续服务
-
-
集群至少几个节点
-
六个,三主三从
-
-
脑裂是怎么出现的
-
网络进行了分区,各自选举,各自提供服务了
-
参考文档:

















 38万+
38万+



 到【灌水乐园】发言
到【灌水乐园】发言








