




 本文深入讲解XML Schema约束机制,对比DTD,介绍Schema的语法特点,包括复杂与简单类型的定义,属性约束,以及如何在XML文档中引入Schema。同时,探讨了SAX解析原理及其在不同场景下的应用。
本文深入讲解XML Schema约束机制,对比DTD,介绍Schema的语法特点,包括复杂与简单类型的定义,属性约束,以及如何在XML文档中引入Schema。同时,探讨了SAX解析原理及其在不同场景下的应用。
xml另一个约束Schema:
1.schema约束:
-
schema符合xml的语法,xml语句
-
一个xml中可以有多个schema,多个schema使用名称空间区分(类似于Java包名)
-
dtd里面有PCDATA类型,但是在schema可以直接定义一个整数类型
例: 年龄 dtd只能是整数 在schema可以直接定义一个整数类型。 -
schema语法更加复杂,schema目前不能替代dtd。
2.schema的快速入门
1.创建schema文件:
-
创建一个schema文件 后缀名是.xsd
-
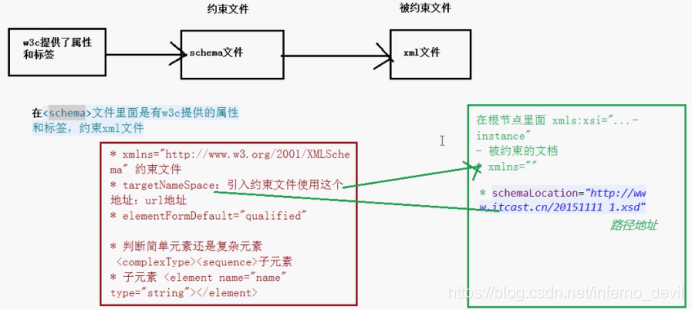
根节点< schema>
-
在schema文件里面
-
属性 xmlns=http://www.w3.org/2001/XMLSchema
-表示当前xml文件是一个约束条件 -
targetNamespace=“http://www.itcast.cn/20151111”
-使用schema约束条件,直接通过这个地址引入约束条件 -
elementFormDefault=“qualified”
2.步骤:
(1)看xml中有多少个元素
<element>
(2)看简单元素和复杂元素
*如果复杂元素
<complexType>
<sequence>
子元素
</sequence>
</complexType>
(3)简单元素,写在复杂元素的
<element name=“person”>
<complexType>
<sequence>
<element name=“string”></element>
<element name=“age” type=“int”></element>
</sequence>
</complexType>
</element>
(4)在被约束文件里面引入约束文件
<person xmlns:xsi=“http://www.w3.org/2001/XMLSchema-instance”
(起的别名)
xmlns=http://www.itcast.cn/20151111
xsi:schemaLocation=http://www.itcast.cn/20151111 1.xsd>
** xmlns:xsi=“http://www.w3.org/2001/XMLSchema-instance”
--表示xml是一个被约束文件
** xmlns=“http://www.itcast.cn/20151111”
--是约束文档里面 targetNamespace
** xsi:scheamLocation=“http://www.itcast.cn/20151111 1.xsd”>
--targetNamespace 空格 约束文档的地址路径
3.schema的开发过程:
*<sequence>:表示元素出现的顺序
<all>:元素只能出现一次
<choice>:元素只能出现其中的一个
maxoccurs=“unbounded”:表示元素的出现的次数
<any></any>:表示任意元素
4.可以约束属性
写在复杂元素里面
*写在</complexType>之前
--
<attribute name=”id1” type=”int” use=”required”></attribute>
-name:属性名称
-type:属性类型 int String
-use:属性是否必须出现 required
*福州市放入schema约束
<company xmlns=http://www.example.org/company
xmlns:xsi=”http://www.w3.org/department
xsi:schemaLocation=http://www.example.org/company company.xsd http://www.example.org/department department.xsd
*引入多个schema文件,可以给每个起一个别名
<employee age=”30”>
<!—部门名称—>
<dept:name>100</dept:name>
*想要引入部门的约束文件里面的name,使用部门的别名dept:元素的名称
<!—员工名称-->
<name>王晓晓</name>
</employee>
3.sax解析的原理
解析xml有两种技术dom和sax。
-
根据xml的层级结构在内存中分配一个树形结构
**把xml中标签,属性,文本封装成对象 -
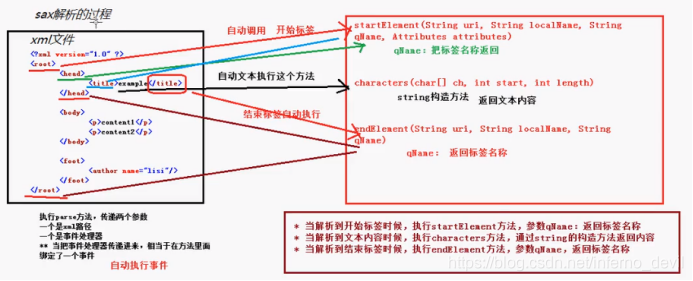
sax方式:时间驱动,边读边解析
-
在javax.xml.parsers包里面
**SAXParser 此类的实例可以从SAXParseFactory.newSAXParser()方法获取 -parse(File f,DefaultHandler dh) *两个参数 **第一个参数:xml的路径 **事件处理器 **SAXParseFactory 实例newInstance()方法得到
1.画图分析sax执行过程:
xml:可以被大多数浏览器所解析
2.解析:操作xml文档,将文档中的数据读取到内存中。
-
操作xml文档
*解析(读取):将文档中的数据读取到内存中 *写入:将内存中的数据保存到xml文档中。持久化的存储 -
解析xml的方式:
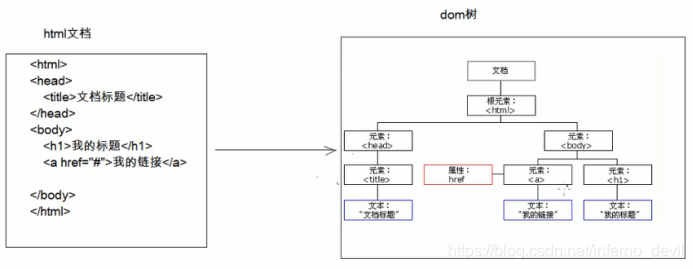
*DOM:
将标记语言文档一次性加载进内存,在内存中形成一颗dom树 -优点:操作方便,可以对文档进行CRUD的所有操作 -缺点:占内存大 (一般在服务器端用)JavaEE是做服务器端的*SAX:
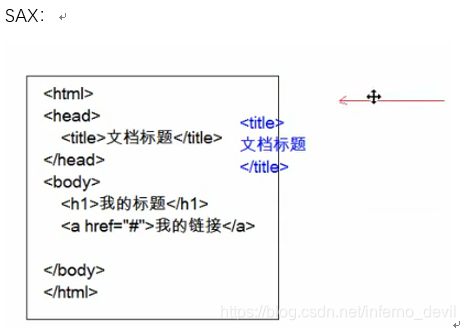
逐行读取,基于时间驱动的。 -优点:不占内存(每次读取一行) -缺点:只能读取,不能增删改 (一般在手机端用)
DOM:
3.JSOUP:
jsoup是一款Java的HTML解析器,可直接解析某个URL地址,HTML文本内容。他提供一套非常省力的API,可通过DOM,CSS以及类似于JQuery的操作方法来取出和操作数据。
1>快速入门:
步骤:
1.导入jar包
2.获取document对象
-根据 xml文档获取
获取student.xml的path
解析xml文档,加载文档进内存,获取dom树—>document
3.获取对应的标签element对象
获取第一个name的element对象
获取数据
2>对象的使用:
1.jsoup:工具类,可以解析HTML或xml文档,返回document
parse:解析HTML或xml文档,返回document
*parse(File in,String charsetName):解析xml或HTML文件的。
*parse(String html):解析xml或html字符串
*parse(URL url,int timeoutMillis):通过网络路径获取指定的html或xml的文档对象。
2.document:文档对象。代表内存中的dom树
*获取element对象
*getElementById(String id):根据id属性值获取唯一的element对象
*getElementByTag(String tagName):根据标签名称获取元素对象集合。
*getElementByAttribute(String key):根据属性名称获取元素对象集合。
*getElementByAttributeValue(String key,String value):根据对应的属性名和属性值获取元素对象集合。
3.elements:元素element对象的集合,可以当做ArrayList<Element>来使用。
4.element:元素对象
1)取子元素对象
*getElementById(String id):根据id属性值获取唯一的element对象
*getElementByTag(String tagName):根据标签名称获取元素对象集合。
*getElementByAttribute(String key):根据属性名称获取元素对象集合。
*getElementByAttributeValue(String key,String value):根据对应的属性名和属性值获取元素对象集合。
2)取属性值
*String attr(String key):根据属性名称获取属性值
3)取文本内容
*String text():获取文本内容
*String html():获取标签体的所有内容(包括子标签的字符串内容)
5.Node:节点对象
*是document和element的父类。
3>快捷查询方式:
1.selector:选择器
*使用的方法:Elements select(String cssQuery)
*语法:参考Selector类中定义的语法
2.XPth:xPath即为xml路径语言,他是一种用来确定xml(标准通用标记语言的子集)文档中某部分位置的语言。
*使用jsoup的Xpath需要额外导入jar包。
*查询w3cschool参考手册,使用Xpath的语法完成查询。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









