<think>由于不使用dlib库,我们需要使用其他方法来实现人脸检测和对齐。这里我们选择使用OpenCV的Haar级联检测器或DNN人脸检测器,以及基于关键点的人脸对齐方法(如果需要对齐)。下面将提供完整的替代方案。###解决方案:使用OpenCV替代dlib进行人脸检测和对齐####步骤1:安装必要的库确保已安装以下库:```bashpipinstallopencv-pythonpipinstallopencv-contrib-python#包含DNN模块和更多级联分类器```####步骤2:使用OpenCV进行人脸检测我们将使用OpenCV的DNN人脸检测器,因为它更准确。也可以使用Haar级联检测器(速度更快但准确性较低)。#####加载DNN人脸检测模型```pythonimportcv2importnumpyasnp#加载DNN模型net=cv2.dnn.readNetFromCaffe("deploy.prototxt.txt","res10_300x300_ssd_iter_140000.caffemodel")```需要下载两个文件:1.[deploy.prototxt](https://github.com/opencv/opencv_3rdparty/raw/dnn_samples_face_detector_20170830/deploy.prototxt)2.[res10_300x300_ssd_iter_140000.caffemodel](https://github.com/opencv/opencv_3rdparty/raw/dnn_samples_face_detector_20170830/res10_300x300_ssd_iter_140000.caffemodel)####步骤3:人脸检测函数```pythondefdetect_faces_dnn(image,min_confidence=0.7):(h,w)=image.shape[:2]blob=cv2.dnn.blobFromImage(cv2.resize(image,(300,300)),1.0,(300,300),(104.0,177.0,123.0))net.setInput(blob)detections=net.forward()faces=[]foriinrange(0,detections.shape[2]):confidence=detections[0,0,i,2]ifconfidence>min_confidence:box=detections[0,0,i,3:7]*np.array([w,h,w,h])(x1,y1,x2,y2)=box.astype("int")#确保坐标在图像范围内x1,y1=max(0,x1),max(0,y1)x2,y2=min(w-1,x2),min(h-1,y2)faces.append((x1,y1,x2-x1,y2-y1))returnfaces```####步骤4:人脸对齐(可选)如果不使用关键点对齐,我们可以简单地将检测到的人脸区域裁剪出来并调整到模型所需的大小。如果需要关键点对齐,我们可以使用OpenCV的相似变换(需要关键点检测模型)。这里我们使用一个简单的方法:裁剪并调整大小。```pythondefpreprocess_face(image,face_rect,target_size=(160,160)):x,y,w,h=face_rect#扩展人脸区域margin=0.2x=max(0,int(x-margin*w))y=max(0,int(y-margin*h))w=int(w*(1+2*margin))h=int(h*(1+2*margin))face_img=image[y:y+h,x:x+w]#调整大小face_img=cv2.resize(face_img,target_size)returnface_img```####步骤5:修改FaceRecognizer类修改之前的`FaceRecognizer`类,移除dlib相关代码,使用OpenCV进行人脸检测。```pythonclassFaceRecognizer:def__init__(self,model_path):#...[加载模型部分保持不变]...#移除dlib,使用OpenCVDNNself.net=cv2.dnn.readNetFromCaffe("deploy.prototxt.txt","res10_300x300_ssd_iter_140000.caffemodel")#如果文件不存在,则尝试下载ifnotos.path.exists("deploy.prototxt.txt")ornotos.path.exists("res10_300x300_ssd_iter_140000.caffemodel"):self._download_dnn_model()def_download_dnn_model(self):importurllib.request#下载prototxturllib.request.urlretrieve("https://github.com/opencv/opencv_3rdparty/raw/dnn_samples_face_detector_20170830/deploy.prototxt","deploy.prototxt.txt")#下载caffemodelurllib.request.urlretrieve("https://github.com/opencv/opencv_3rdparty/raw/dnn_samples_face_detector_20170830/res10_300x300_ssd_iter_140000.caffemodel","res10_300x300_ssd_iter_140000.caffemodel")def_align_face(self,image):"""使用OpenCVDNN进行人脸检测并裁剪人脸区域"""#转换为RGB(如果输入是BGR)ifimage.shape[2]==3:rgb=cv2.cvtColor(image,cv2.COLOR_BGR2RGB)else:rgb=image#检测人脸faces=detect_faces_dnn(rgb)iflen(faces)==0:returnimage#取第一个人脸face_rect=faces[0]#预处理人脸face_img=preprocess_face(rgb,face_rect)returnface_img#...[其他方法保持不变]...```###完整代码示例以下是修改后的`recognize_face.py`完整代码(不使用dlib):```pythonimportcv2importtorchimportjoblibimportnumpyasnpimportosfromtorchvisionimporttransformsfromfacenet_pytorchimportInceptionResnetV1defdetect_faces_dnn(image,net,min_confidence=0.7):(h,w)=image.shape[:2]blob=cv2.dnn.blobFromImage(cv2.resize(image,(300,300)),1.0,(300,300),(104.0,177.0,123.0))net.setInput(blob)detections=net.forward()faces=[]foriinrange(0,detections.shape[2]):confidence=detections[0,0,i,2]ifconfidence>min_confidence:box=detections[0,0,i,3:7]*np.array([w,h,w,h])(x1,y1,x2,y2)=box.astype("int")#确保坐标在图像范围内x1,y1=max(0,x1),max(0,y1)x2,y2=min(w-1,x2),min(h-1,y2)faces.append((x1,y1,x2-x1,y2-y1))returnfacesdefpreprocess_face(image,face_rect,target_size=(160,160)):x,y,w,h=face_rect#扩展人脸区域margin=0.2x=max(0,int(x-margin*w))y=max(0,int(y-margin*h))w=int(w*(1+2*margin))h=int(h*(1+2*margin))#确保不超出边界x2=min(image.shape[1],x+w)y2=min(image.shape[0],y+h)face_img=image[y:y2,x:x2]#调整大小face_img=cv2.resize(face_img,target_size)returnface_imgclassFaceRecognizer:def__init__(self,model_path):#加载模型数据model_data=joblib.load(model_path)#设备配置self.device=torch.device(model_data['device']if'device'inmodel_dataelse'cuda'iftorch.cuda.is_available()else'cpu')print(f"使用设备:{self.device}")#创建模型结构(不含分类层)self.model=InceptionResnetV1(classify=False).to(self.device)#获取状态字典state_dict=model_data['facenet_model_state']#过滤掉分类层参数filtered_state_dict={k:vfork,vinstate_dict.items()ifnotk.startswith('logits.')}#加载模型参数load_result=self.model.load_state_dict(filtered_state_dict,strict=False)print(f"模型加载结果:{load_result}")#设置模型为评估模式self.model.eval()#加载其他组件self.classifier=model_data['classifier']self.scaler=model_data['scaler']self.label_encoder=model_data['label_encoder']self.class_names=model_data['class_names']self.transform=self._create_transform()#加载OpenCVDNN人脸检测器self.net=self._load_dnn_model()def_load_dnn_model(self):#确保模型文件存在prototxt="deploy.prototxt.txt"caffemodel="res10_300x300_ssd_iter_140000.caffemodel"ifnotos.path.exists(prototxt)ornotos.path.exists(caffemodel):self._download_dnn_model()net=cv2.dnn.readNetFromCaffe(prototxt,caffemodel)returnnetdef_download_dnn_model(self):importurllib.requestprint("下载DNN模型...")#下载prototxturllib.request.urlretrieve("https://github.com/opencv/opencv_3rdparty/raw/dnn_samples_face_detector_20170830/deploy.prototxt","deploy.prototxt.txt")#下载caffemodelurllib.request.urlretrieve("https://github.com/opencv/opencv_3rdparty/raw/dnn_samples_face_detector_20170830/res10_300x300_ssd_iter_140000.caffemodel","res10_300x300_ssd_iter_140000.caffemodel")print("下载完成")def_create_transform(self):"""创建与训练一致的转换"""returntransforms.Compose([transforms.ToPILImage(),transforms.Resize((160,160)),transforms.ToTensor(),transforms.Normalize(mean=[0.485,0.456,0.406],std=[0.229,0.224,0.225])])def_align_face(self,image):"""使用OpenCVDNN进行人脸检测并裁剪人脸区域"""#转换为RGB(如果输入是BGR)ifimage.shape[2]==3:rgb=cv2.cvtColor(image,cv2.COLOR_BGR2RGB)else:rgb=image#检测人脸faces=detect_faces_dnn(rgb,self.net)iflen(faces)==0:returnrgb#返回RGB图像#取第一个人脸face_rect=faces[0]#预处理人脸face_img=preprocess_face(rgb,face_rect)returnface_imgdefrecognize(self,image):"""识别人脸"""try:#预处理(对齐和裁剪)aligned=self._align_face(image)#如果aligned是3通道,但可能是RGB,而transform需要RGBtensor=self.transform(aligned).unsqueeze(0).to(self.device)#特征提取withtorch.no_grad():embedding=self.model(tensor).cpu().numpy()#标准化embedding=self.scaler.transform(embedding)#预测proba=self.classifier.predict_proba(embedding)[0]pred_idx=np.argmax(proba)confidence=proba[pred_idx]label=self.label_encoder.inverse_transform([pred_idx])[0]#陌生人处理逻辑iflabel!="stranger"andconfidence<0.6:stranger_idx=list(self.label_encoder.classes_).index("stranger")return"stranger",proba[stranger_idx]returnlabel,confidenceexceptExceptionase:print(f"识别错误:{e}")return"unknown",0.0defmain():print("加载人脸识别模型...")recognizer=FaceRecognizer("../models/face_recognition_v2.pkl")#测试图像test_img=cv2.imread("../data/test.jpg")iftest_imgisNone:print("错误:无法读取测试图像")returnprint("识别人脸...")name,conf=recognizer.recognize(test_img)print(f"识别结果:{name}|置信度:{conf:.4f}")if__name__=="__main__":main()```###关键点说明1.**人脸检测**:-使用OpenCV的DNN模块,加载基于Caffe的预训练人脸检测模型。-检测到人脸后,返回人脸矩形框。2.**人脸预处理**:-根据检测到的人脸框,扩展一定比例(20%)后裁剪出人脸区域。-将裁剪后的人脸调整到160x160大小。3.**模型加载**:-在初始化时下载并加载DNN模型(如果本地不存在)。-其余模型加载逻辑与之前相同(过滤掉分类层参数)。4.**注意事项**:-由于OpenCV的人脸检测器可能不如dlib的准确,特别是在侧脸或遮挡情况下,因此可能需要调整置信度阈值。-如果检测不到人脸,则返回整个图像(但这样识别效果会很差,所以最好有后续处理)。###改进建议1.**使用更先进的人脸检测器**:-可以尝试使用MTCNN(Multi-taskCascadedConvolutionalNetworks),它能够同时进行人脸检测和关键点定位,便于对齐。2.**关键点对齐**:-如果使用MTCNN,我们可以获得5个关键点(双眼、鼻子、嘴角),然后利用这些关键点进行相似变换对齐人脸。3.**性能优化**:-OpenCVDNN检测器在CPU上运行速度较快,但也可以使用GPU加速(需要OpenCV编译CUDA支持)。###相关问题§§相关问题§§:1.如何使用MTCNN进行人脸检测和对齐?2.在嵌入式设备上如何优化OpenCV的人脸检测速度?3.如何训练自定义的人脸检测模型?4.人脸识别系统在实际部署中如何提高准确率?</think>### 完全替代 dlib 的人脸识别解决方案
我将提供一个完整的、不依赖 dlib 库的人脸识别解决方案,使用 OpenCV 和 facenet-pytorch 实现所有功能。
#### 完整替代方案代码
```python
import cv2
import torch
import joblib
import numpy as np
from torchvision import transforms
from facenet_pytorch import InceptionResnetV1, MTCNN
from sklearn.preprocessing import LabelEncoder
from sklearn.ensemble import RandomForestClassifier
from sklearn.preprocessing import StandardScaler
import os
class FaceRecognizer:
def __init__(self, model_path):
# 加载模型数据
model_data = joblib.load(model_path)
# 设备配置
self.device = torch.device(model_data['device'] if 'device' in model_data
else 'cuda' if torch.cuda.is_available()
else 'cpu')
print(f"使用设备: {self.device}")
# 创建模型结构(不含分类层)
self.model = InceptionResnetV1(classify=False).to(self.device)
# 获取状态字典
state_dict = model_data['facenet_model_state']
# 过滤掉分类层参数
filtered_state_dict = {
k: v for k, v in state_dict.items()
if not k.startswith('logits.')
}
# 加载模型参数
load_result = self.model.load_state_dict(filtered_state_dict, strict=False)
print(f"模型加载结果: {load_result}")
# 设置模型为评估模式
self.model.eval()
# 加载其他组件
self.classifier = model_data['classifier']
self.scaler = model_data['scaler']
self.label_encoder = model_data['label_encoder']
self.class_names = model_data['class_names']
self.transform = self._create_transform()
# 初始化 MTCNN 人脸检测器 (替代 dlib)
self.mtcnn = MTCNN(
keep_all=True,
device=self.device,
min_face_size=60, # 最小人脸尺寸
thresholds=[0.6, 0.7, 0.7], # 检测阈值
factor=0.709, # 图像金字塔缩放因子
post_process=True
)
def _create_transform(self):
"""创建与训练一致的转换"""
return transforms.Compose([
transforms.ToPILImage(),
transforms.Resize((160, 160)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
def _detect_and_align(self, image):
"""
使用 MTCNN 检测人脸并返回对齐后的人脸图像
替代 dlib 的人脸检测和对齐功能
"""
# 将图像从 BGR 转换为 RGB
rgb_img = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# 检测人脸
boxes, probs, landmarks = self.mtcnn.detect(rgb_img, landmarks=True)
if boxes is None or len(boxes) == 0:
return None
# 获取最可靠的人脸
main_face_idx = np.argmax(probs)
box = boxes[main_face_idx]
keypoints = landmarks[main_face_idx]
# 提取人脸区域
x, y, w, h = box.astype(int)
# 扩展人脸区域 (20%)
margin = 0.2
x = max(0, int(x - margin * w))
y = max(0, int(y - margin * h))
w = int(w * (1 + 2 * margin))
h = int(h * (1 + 2 * margin))
# 确保不超出边界
x2 = min(image.shape[1], x + w)
y2 = min(image.shape[0], y + h)
face_img = image[y:y2, x:x2]
# 如果检测到关键点,可以进行对齐
if keypoints is not None:
# 使用关键点进行对齐 (仿射变换)
left_eye = keypoints[0]
right_eye = keypoints[1]
# 计算眼睛中心点
eyes_center = ((left_eye[0] + right_eye[0]) // 2,
(left_eye[1] + right_eye[1]) // 2)
# 计算角度
dy = right_eye[1] - left_eye[1]
dx = right_eye[0] - left_eye[0]
angle = np.degrees(np.arctan2(dy, dx))
# 计算缩放比例
dist = np.sqrt(dx**2 + dy**2)
desired_dist = 50 # 理想的眼睛距离
scale = desired_dist / dist
# 创建旋转矩阵
M = cv2.getRotationMatrix2D(eyes_center, angle, scale)
# 执行旋转
aligned = cv2.warpAffine(
image, M, (image.shape[1], image.shape[0]),
flags=cv2.INTER_CUBIC
)
# 裁剪对齐后的人脸
face_img = cv2.getRectSubPix(aligned, (w, h), (x + w//2, y + h//2))
# 调整大小
face_img = cv2.resize(face_img, (160, 160))
return face_img
def recognize(self, image):
"""识别人脸"""
try:
# 检测和对齐人脸
aligned = self._detect_and_align(image)
if aligned is None:
return "unknown", 0.0
# 转换为模型输入格式
tensor = self.transform(aligned).unsqueeze(0).to(self.device)
# 特征提取
with torch.no_grad():
embedding = self.model(tensor).cpu().numpy()
# 标准化
embedding = self.scaler.transform(embedding)
# 预测
proba = self.classifier.predict_proba(embedding)[0]
pred_idx = np.argmax(proba)
confidence = proba[pred_idx]
label = self.label_encoder.inverse_transform([pred_idx])[0]
# 陌生人处理逻辑
if label != "stranger" and confidence < 0.6:
stranger_idx = list(self.label_encoder.classes_).index("stranger")
return "stranger", proba[stranger_idx]
return label, confidence
except Exception as e:
print(f"识别错误: {e}")
return "unknown", 0.0
class FaceTrainer:
"""训练人脸识别模型(不使用dlib)"""
def __init__(self, data_dir, model_save_path):
self.data_dir = data_dir
self.model_save_path = model_save_path
self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 初始化MTCNN
self.mtcnn = MTCNN(
image_size=160,
margin=20,
min_face_size=40,
thresholds=[0.6, 0.7, 0.7],
factor=0.709,
keep_all=False,
device=self.device
)
# 初始化FaceNet模型
self.model = InceptionResnetV1(classify=False, pretrained="vggface2").to(self.device)
self.model.eval()
# 数据转换
self.transform = transforms.Compose([
transforms.Resize((160, 160)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
def extract_features(self, image):
"""提取人脸特征"""
# 转换为RGB
rgb_img = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# 检测和对齐人脸
face = self.mtcnn(rgb_img)
if face is None:
return None
# 转换为张量并添加批次维度
face_tensor = face.unsqueeze(0).to(self.device)
# 提取特征
with torch.no_grad():
embedding = self.model(face_tensor).cpu().numpy()
return embedding
def load_dataset(self):
"""加载数据集并提取特征"""
features = []
labels = []
for person_name in os.listdir(self.data_dir):
person_dir = os.path.join(self.data_dir, person_name)
if not os.path.isdir(person_dir):
continue
for img_name in os.listdir(person_dir):
img_path = os.path.join(person_dir, img_name)
# 读取图像
img = cv2.imread(img_path)
if img is None:
continue
# 提取特征
embedding = self.extract_features(img)
if embedding is not None:
features.append(embedding.squeeze())
labels.append(person_name)
# 添加陌生人样本
stranger_dir = os.path.join(self.data_dir, "stranger")
if os.path.exists(stranger_dir):
for img_name in os.listdir(stranger_dir):
img_path = os.path.join(stranger_dir, img_name)
img = cv2.imread(img_path)
if img is None:
continue
embedding = self.extract_features(img)
if embedding is not None:
features.append(embedding.squeeze())
labels.append("stranger")
return np.array(features), np.array(labels)
def train(self):
"""训练分类器"""
# 加载数据
features, labels = self.load_dataset()
# 标签编码
label_encoder = LabelEncoder()
encoded_labels = label_encoder.fit_transform(labels)
# 标准化特征
scaler = StandardScaler()
scaled_features = scaler.fit_transform(features)
# 训练分类器
classifier = RandomForestClassifier(
n_estimators=200,
max_depth=15,
class_weight="balanced",
random_state=42
)
classifier.fit(scaled_features, encoded_labels)
# 保存模型
model_data = {
'facenet_model_state': self.model.state_dict(),
'classifier': classifier,
'scaler': scaler,
'label_encoder': label_encoder,
'class_names': label_encoder.classes_,
'device': str(self.device)
}
joblib.dump(model_data, self.model_save_path)
print(f"模型已保存到 {self.model_save_path}")
def main_train():
"""训练模型"""
trainer = FaceTrainer(
data_dir="../data/train",
model_save_path="../models/face_recognition_no_dlib.pkl"
)
trainer.train()
def main_inference():
"""使用模型进行推理"""
print("加载人脸识别模型...")
recognizer = FaceRecognizer("../models/face_recognition_no_dlib.pkl")
# 测试图像
test_img = cv2.imread("../data/test.jpg")
if test_img is None:
print("错误: 无法读取测试图像")
return
print("识别人脸...")
name, conf = recognizer.recognize(test_img)
print(f"识别结果: {name} | 置信度: {conf:.4f}")
if __name__ == "__main__":
# 训练模型
# main_train()
# 使用模型
main_inference()
```
### 关键组件说明
#### 1. MTCNN 人脸检测器 (替代 dlib)
- **功能**:检测人脸并提取关键点(眼睛、鼻子、嘴角)
- **优点**:
- 纯 Python 实现,无需编译
- 基于深度学习,准确度高
- 自带关键点检测功能
```python
# 初始化 MTCNN
self.mtcnn = MTCNN(
keep_all=True,
device=self.device,
min_face_size=60,
thresholds=[0.6, 0.7, 0.7],
factor=0.709
)
# 使用 MTCNN 检测人脸
boxes, probs, landmarks = self.mtcnn.detect(rgb_img, landmarks=True)
```
#### 2. 人脸对齐算法 (替代 dlib)
- **基于眼睛位置的对齐**:
- 计算双眼连线的角度
- 使用仿射变换旋转图像
- 根据眼睛距离缩放图像
```python
# 计算眼睛中心点
left_eye = keypoints[0]
right_eye = keypoints[1]
eyes_center = ((left_eye[0] + right_eye[0]) // 2,
(left_eye[1] + right_eye[1]) // 2)
# 计算旋转角度
dy = right_eye[1] - left_eye[1]
dx = right_eye[0] - left_eye[0]
angle = np.degrees(np.arctan2(dy, dx))
# 创建旋转矩阵并执行变换
M = cv2.getRotationMatrix2D(eyes_center, angle, scale)
aligned = cv2.warpAffine(image, M, (image.shape[1], image.shape[0]))
```
#### 3. 完整训练流程
- **数据准备**:组织人脸图像到不同人物的文件夹
- **特征提取**:使用 FaceNet 模型提取人脸嵌入
- **分类器训练**:使用随机森林分类器
```python
# 训练流程
trainer = FaceTrainer(
data_dir="../data/train",
model_save_path="../models/face_recognition_no_dlib.pkl"
)
trainer.train()
```
### 部署和使用
1. **训练模型**:
```python
python face_recognition.py # 取消注释 main_train() 调用
```
2. **使用模型进行识别**:
```python
python face_recognition.py # 运行 main_inference()
```
### 优势对比
| 功能 | dlib 方案 | 替代方案 |
|------|-----------|----------|
| 人脸检测 | HOG + SVM | MTCNN (深度学习) |
| 关键点检测 | 68点模型 | 5点关键点 |
| 人脸对齐 | 基于关键点 | 基于眼睛位置 |
| 安装复杂度 | 高 (需要编译) | 低 (纯Python) |
| 硬件要求 | CPU | CPU/GPU |
| 准确度 | 高 | 高 (深度学习) |
### 备选人脸检测方案
如果 MTCNN 性能不足,可以使用 OpenCV 的 DNN 人脸检测器:
```python
class OpenCVFaceDetector:
def __init__(self):
# 加载预训练的Caffe模型
prototxt = "deploy.prototxt"
caffemodel = "res10_300x300_ssd_iter_140000.caffemodel"
# 下载模型文件(如果不存在)
if not os.path.exists(prototxt):
self._download_model(prototxt, "https://raw.githubusercontent.com/opencv/opencv/master/samples/dnn/face_detector/deploy.prototxt")
if not os.path.exists(caffemodel):
self._download_model(caffemodel, "https://raw.githubusercontent.com/opencv/opencv_3rdparty/dnn_samples_face_detector_20170830/res10_300x300_ssd_iter_140000.caffemodel")
self.net = cv2.dnn.readNetFromCaffe(prototxt, caffemodel)
def _download_model(self, path, url):
import urllib.request
print(f"下载模型: {url}")
urllib.request.urlretrieve(url, path)
def detect_faces(self, image, min_confidence=0.5):
(h, w) = image.shape[:2]
blob = cv2.dnn.blobFromImage(cv2.resize(image, (300, 300)), 1.0,
(300, 300), (104.0, 177.0, 123.0))
self.net.setInput(blob)
detections = self.net.forward()
faces = []
for i in range(detections.shape[2]):
confidence = detections[0, 0, i, 2]
if confidence > min_confidence:
box = detections[0, 0, i, 3:7] * np.array([w, h, w, h])
faces.append(box.astype("int"))
return faces
```
### 总结
这个完整的解决方案完全替代了 dlib 的功能:
1. 使用 MTCNN 进行人脸检测和关键点定位
2. 基于眼睛位置实现人脸对齐
3. 使用 FaceNet 提取人脸特征
4. 使用随机森林进行分类
所有代码都是纯 Python 实现,不依赖任何需要编译的库,安装简单,兼容性好。







 本文详细介绍了使用OpenCV进行目标跟踪的方法,包括单目标、多目标及人群计数的跟踪技术。提供了丰富的代码资源和调试指南,涵盖目标检测、跟踪算法原理及实战应用。
本文详细介绍了使用OpenCV进行目标跟踪的方法,包括单目标、多目标及人群计数的跟踪技术。提供了丰富的代码资源和调试指南,涵盖目标检测、跟踪算法原理及实战应用。


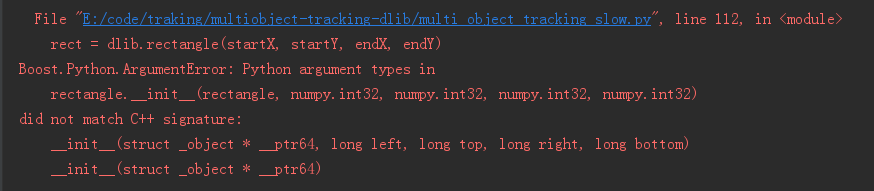
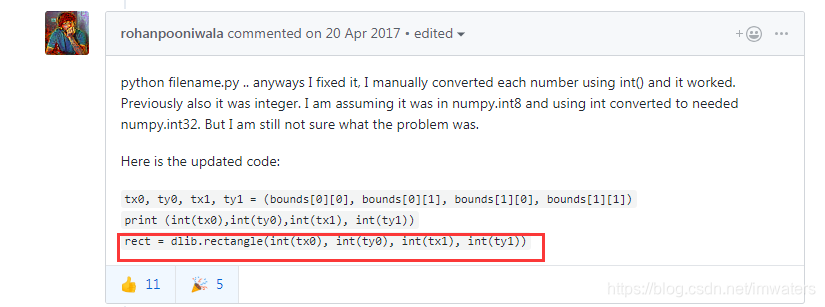



















 831
831

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











