






ACL2019 Best Long Paper解读:
- 目的:解决训练数据的Teacher Forcing问题
- 训练时使用true ground数据,而推断时使用预测结果作为上文,在训练时会造成overcorrection(同义词结果被过度矫正)
- 提出在训练时不仅仅使用true ground label,还会结合oracle word作为上下文,结构如下:
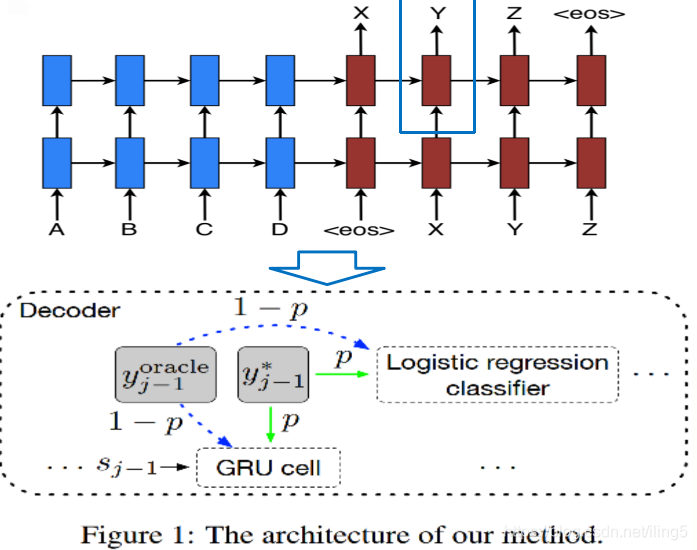
在原始NTM的基础上,在j时,输入j-1不再仅仅使用true groud label,而是会结合oracle word(soft机制),文章的重点在于如何选择oracle word,提出两种方式:词粒度和句子粒度。
- 使用oracle word机制的三步走:

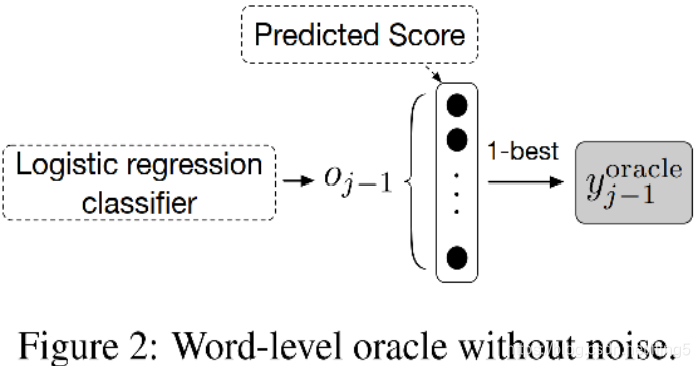
- Word-Level Oracle(WO)机制
- 直接拿预测概率最大的输出作为oracle word,下图及公式(9)所示
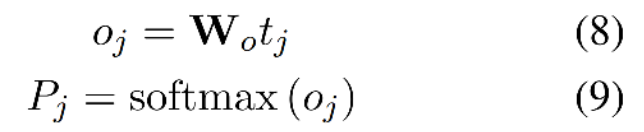
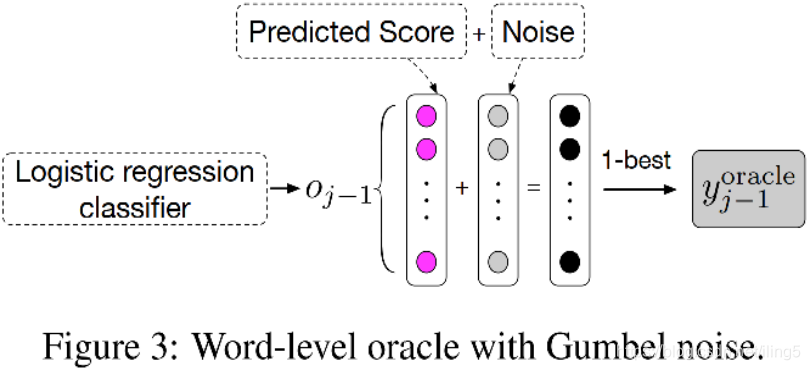
- 引入Gumbel noise正则项增加模型鲁棒性
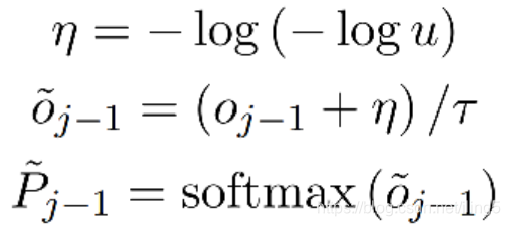
- Sentence-Level Oracle (SO)
- 在每个step时,对batch内样本做beam search decode,使用BLEU进行效果度量,得到最优目标句子,句子中第j-1个word作为SO
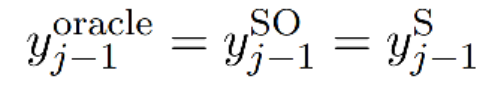
- 由于SO及来自于true ground又来自于beam search,所以需要二者长度对齐,对齐方式使用Force Decoding
- Force Decoding:根据EOS作为判断,步骤如下:

- Sampling with Decay 原则:训练开始的时候倾向于使用true ground label,训练后期倾向于选择oracle word
- p控制true groud和oracle word的选择,衰减公式如下,e为epoch,μ为超参
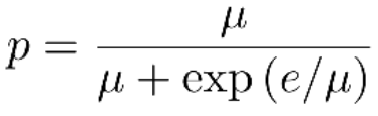
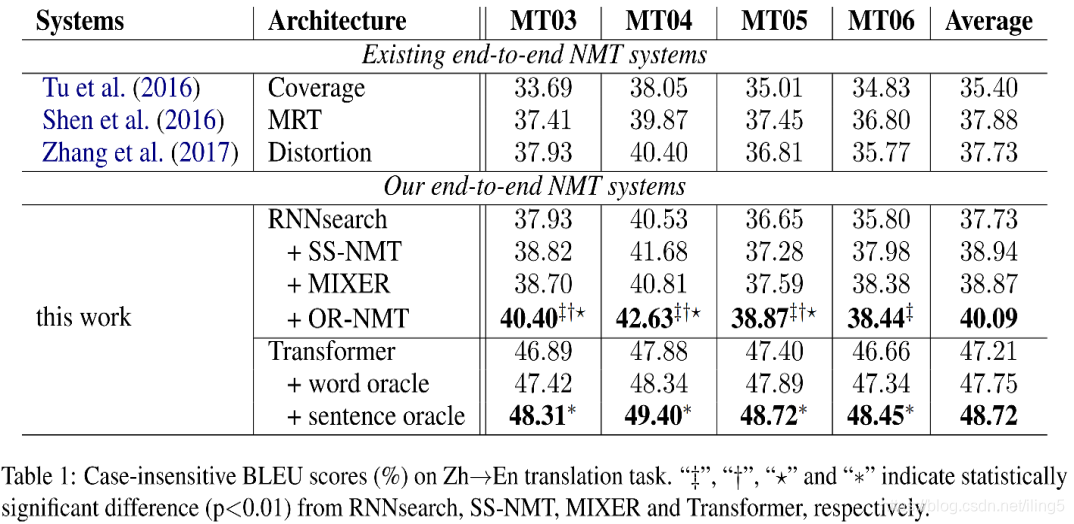
- 结果展示:使用Transformat结果效果好用RNN,引入sentence oracle效果好于WO

- 总结:文章创新性地使用了soft label作为next step的输入,可以解决训练过程中的「过度矫正及误差累及」问题,该方法在NMT上提及,但感觉可以扩展应用到其他「联合训练的模型上」,第二个任务基于第一个任务的输出label,在训练阶段可采用此soft label选取的方法。

















 821
821




 到【灌水乐园】发言
到【灌水乐园】发言







