








作者:Fyuocuk
链接:https://www.zhihu.com/question/54356960/answer/293804923
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
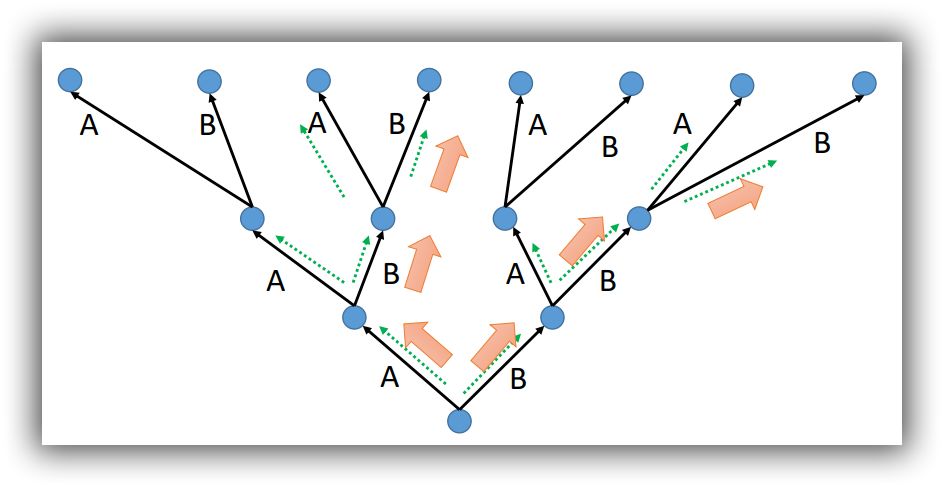
首先需要确定一个`Beam Size`,这里设置为2,意思是每个`word`后面的分支考虑概率最大的那两个`words`。比如下面的例子,从下往上首先分成A、B两个words,然后继续往上传播,句子变成是AA/AB/BA/BB这四种情况(绿色虚线)。考虑到`Beam Size=2`,选择概率最大的两个,假设是AB/BA(橙色大箭头)。然后以选择的AB/BA继续向上传播,又出现了四种情况ABA/ABB/BBA/BBB,依然是选择综合概率最大的两个ABB/BBB。以此类推,直至句子结束。只要可以调整好`Beam Size`,就能够使用最小的计算量,得到最优的结果。

















 1679
1679

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









