




K-近邻算法(KNN)
K nearest neighbour
欧几里得距离
一维:
A(a) B(b)
d = |a-b| = ((a-b)**2)**0.5
二维:
A(a1,a2) B(b1,b2)
d =((a1-b1)**2 + (a2-b2)**2)**0.5
三维:
A(a1,a2,a3) B(b1,b2,b3)
d = ((a1-b1)**2 + (a2-b2)**2 + (a3-b3)**2)**0.5
多维:
A(a1,a2,...,an) B(b1,b2,....,bn)
d = ((a1-b1)**2 + (a2-b2)**2+....+(an-bn)**2)**0.5
0、导引
如何进行电影分类
众所周知,电影可以按照题材分类,然而题材本身是如何定义的?由谁来判定某部电影属于哪
个题材?也就是说同一题材的电影具有哪些公共特征?这些都是在进行电影分类时必须要考虑的问
题。没有哪个电影人会说自己制作的电影和以前的某部电影类似,但我们确实知道每部电影在风格
上的确有可能会和同题材的电影相近。那么动作片具有哪些共有特征,使得动作片之间非常类似,
而与爱情片存在着明显的差别呢?动作片中也会存在接吻镜头,爱情片中也会存在打斗场景,我们
不能单纯依靠是否存在打斗或者亲吻来判断影片的类型。但是爱情片中的亲吻镜头更多,动作片中
的打斗场景也更频繁,基于此类场景在某部电影中出现的次数可以用来进行电影分类。
本章介绍第一个机器学习算法:K-近邻算法,它非常有效而且易于掌握。
1、k-近邻算法原理
简单地说,K-近邻算法采用测量不同特征值之间的距离方法进行分类。
- 优点:精度高、对异常值不敏感、无数据输入假定。
- 缺点:时间复杂度高、空间复杂度高。
- 适用数据范围:数值型和标称型。
工作原理
存在一个样本数据集合,也称作训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一数据
与所属分类的对应关系。输人没有标签的新数据后,将新数据的每个特征与样本集中数据对应的
特征进行比较,然后算法提取样本集中特征最相似数据(最近邻)的分类标签。一般来说,我们
只选择样本数据集中前K个最相似的数据,这就是K-近邻算法中K的出处,通常K是不大于20的整数。
最后 ,选择K个最相似数据中出现次数最多的分类,作为新数据的分类。
回到前面电影分类的例子,使用K-近邻算法分类爱情片和动作片。有人曾经统计过很多电影的打斗镜头和接吻镜头,下图显示了6部电影的打斗和接吻次数。假如有一部未看过的电影,如何确定它是爱情片还是动作片呢?我们可以使用K-近邻算法来解决这个问题。
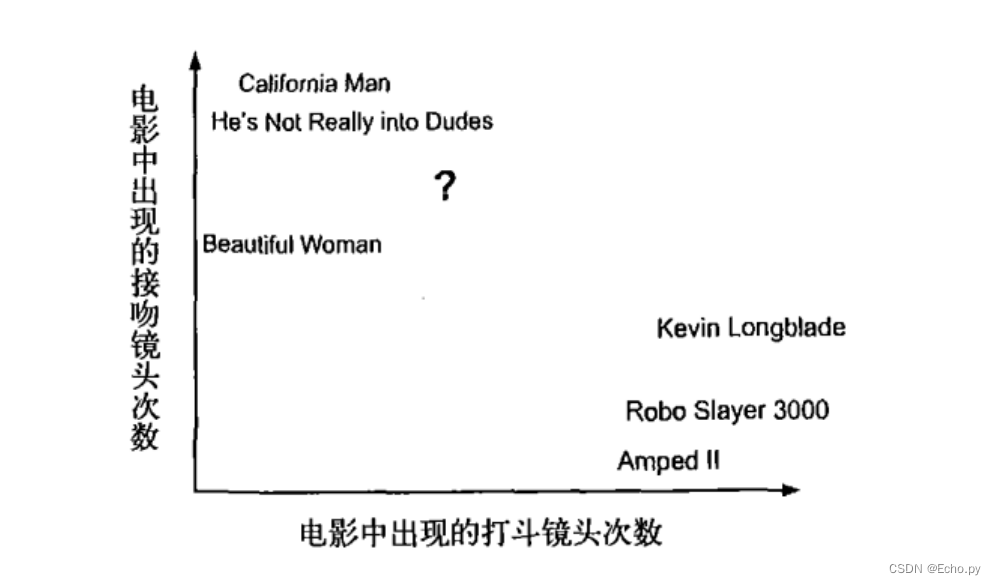
首先我们需要知道这个未知电影存在多少个打斗镜头和接吻镜头,上图中问号位置是该未知电影出现的镜头数图形化展示,具体数字参见下表。
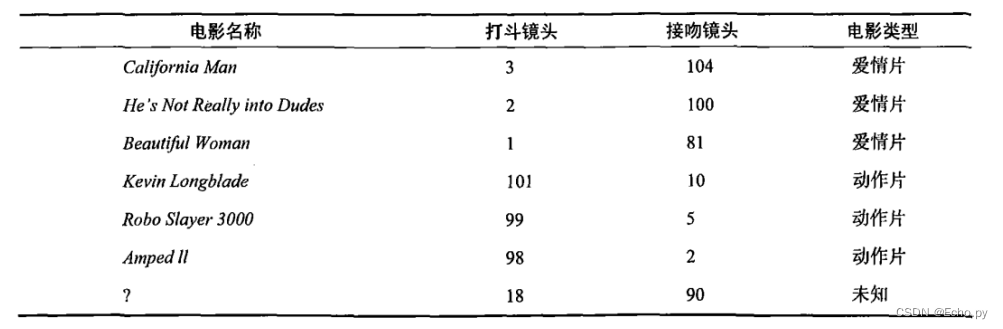
即使不知道未知电影属于哪种类型,我们也可以通过某种方法计算出来。首先计算未知电影与样本集中其他电影的距离,如图所示。
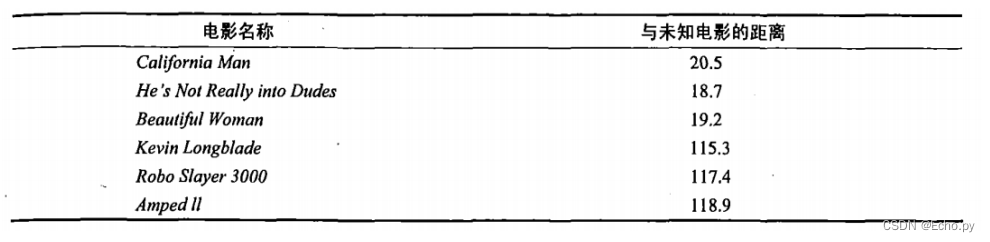
现在我们得到了样本集中所有电影与未知电影的距离,按照距离递增排序,可以找到K个距
离最近的电影。假定k=3,则三个最靠近的电影依次是California Man、He’s Not Really into Dudes、Beautiful Woman。K-近邻算法按照距离最近的三部电影的类型,决定未知电影的类型,而这三部电影全是爱情片,因此我们判定未知电影是爱情片。
欧几里得距离(Euclidean Distance)
欧氏距离是最常见的距离度量,衡量的是多维空间中各个点之间的绝对距离。公式如下:
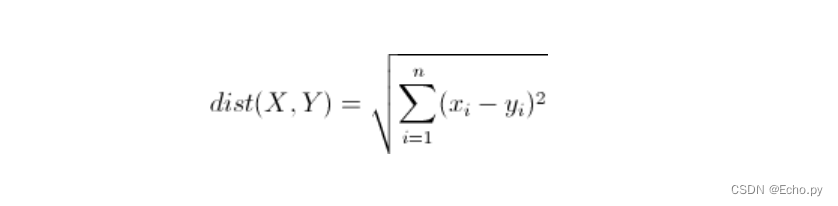
K-近邻算法的步骤:
1、我们求未知点到所有样本点的距离
2、对以上求的距离进行排序(从小到大)
3、对排序号的样本点取前K个(注意K值一般不大于20)
4、对这前K个样本的标签进行分析,如果某一样本标签占优势那么未知点就属于该标签的类别
2、在scikit-learn库中使用k-近邻算法
安装:
pip install sklearn
- 分类问题:from sklearn.neighbors import KNeighborsClassifier
- 回归问题:from sklearn.neighbors import KNeighborsRegressor
0)一个最简单的例子
根据身高、体重和鞋子尺码来判断性别
import numpy as np
# 构造特征数据
x = np.array([[173,68,40],[172,64,38],[155,70,42],[178,78,43],[156,45,39],[185,80,44],
[166,68,42],[163,59,37]])
# 构造标签数据
y = np.array(["男","女","男","男","女","男","男","女"])
# 生成一些未知的特征数据
x_test = np.array([[168,40,40],[170,68,39],[153,45,44],[166,79,43],[180,89,42]])
导入k-近邻模型
from sklearn.neighbors import KNeighborsClassifier
# sklearn,全称是scikit-learn,它是一个机器学习的框架,里面集成了几乎所有的经典机器学习算法
# 以及一些数据过滤清洗和处理的算法
# sklearn的封装程度非常高,几乎对开发者是透明,我们可以直接把里面的模型拿过来用,不需要过多
# 的关心算法的集成过程
# neighbors包是sklearn中的一个算法程序包,里面包含了和近邻有关所有的算法的集成模型
创建k-近邻分类模型
knn = KNeighborsClassifier(n_neighbors=3)
# 参数n_neighbors代表k-近邻的那个K
knn
KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=None, n_neighbors=3, p=2,
weights='uniform')
训练knn模型
knn.fit(x,y)
# 训练过程,首先要把训练数据(即已知样本)带入,然后模型就会对这些数据进行训练
# knn的训练过程就是把数据保存,供后面使用
KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=None, n_neighbors=3, p=2,
weights='uniform')
用训练好的knn模型来预测未知数据
knn.predict(x_test)
# 预测过程,1)分别拿每一个未知样本和所有的已知样本求距离 2)对距离排序 3)取前3个标签进行
# 判断进一步决定
array(['女', '男', '女', '男', '男'], dtype='<U1')
性能检测
y
array(['男', '女', '男', '男', '女', '男', '男', '女'], dtype='<U1')
knn.predict(x)
# 此时我们拿x和y作为训练数据来训练,然后又用x和y作为测试数据来测试(即训练集合测试集都是
# 同一批数据),此时造成的误差我们称之为经验误差
array(['男', '男', '男', '男', '女', '男', '男', '女'], dtype='<U1')
# 经验误差
knn.score(x,y) # 经验准确率
# score是sklearn的监督学习算法的一个函数,它用于将x参数中的特征带入训练好的模型中,然后预测
# 出结果,然后拿预测的结果和正确的结果y做比较,查看其中预测的准确率
0.875
1)用于分类
from sklearn import datasets
# datasets是sklearn提供的一个官方的数据集合,这个集合中提供了大量的官方实验数据
iris = datasets.load_iris()
iris
{'DESCR': '.. _iris_dataset:\n\nIris plants dataset\n--------------------\n\n**Data Set Characteristics:**\n\n :Number of Instances: 150 (50 in each of three classes)\n :Number of Attributes: 4 numeric, predictive attributes and the class\n :Attribute Information:\n - sepal length in cm\n - sepal width in cm\n - petal length in cm\n - petal width in cm\n - class:\n - Iris-Setosa\n - Iris-Versicolour\n - Iris-Virginica\n \n :Summary Statistics:\n\n ============== ==== ==== ======= ===== ==================== 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1377
1377

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









