




 本文介绍如何使用Scrapy框架搭建并运行一个简单的爬虫项目,包括项目创建、Spider文件生成、运行方式及数据导出等内容。
本文介绍如何使用Scrapy框架搭建并运行一个简单的爬虫项目,包括项目创建、Spider文件生成、运行方式及数据导出等内容。
1、打开cmd,进入到项目准备所放在的文件夹,执行命令:
scrapy startproject douban然后就可以使用pycharm打开项目了
2、建立spider文件
cmd命令行进入到项目的spiders文件夹,执行:
scrapy genspider douban_spider url
scrapy genspider douban_spider movie.douban.com
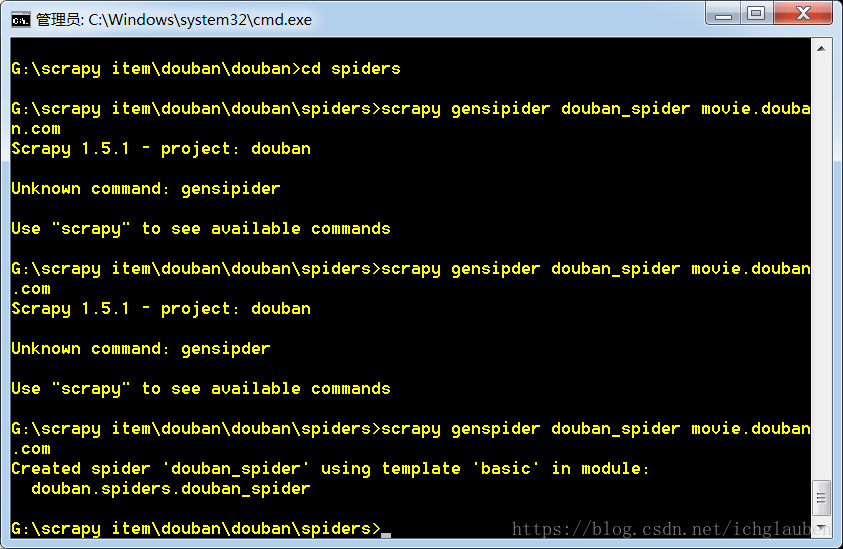
其中 spiderFileName为你所想创建的spider的文件名,url为你准备爬取的服务器域名,如 http://www.abc.com
然后可以在pycharm中进行编写了,如果没有新建的文件,就同步一下项目(项目名右键)
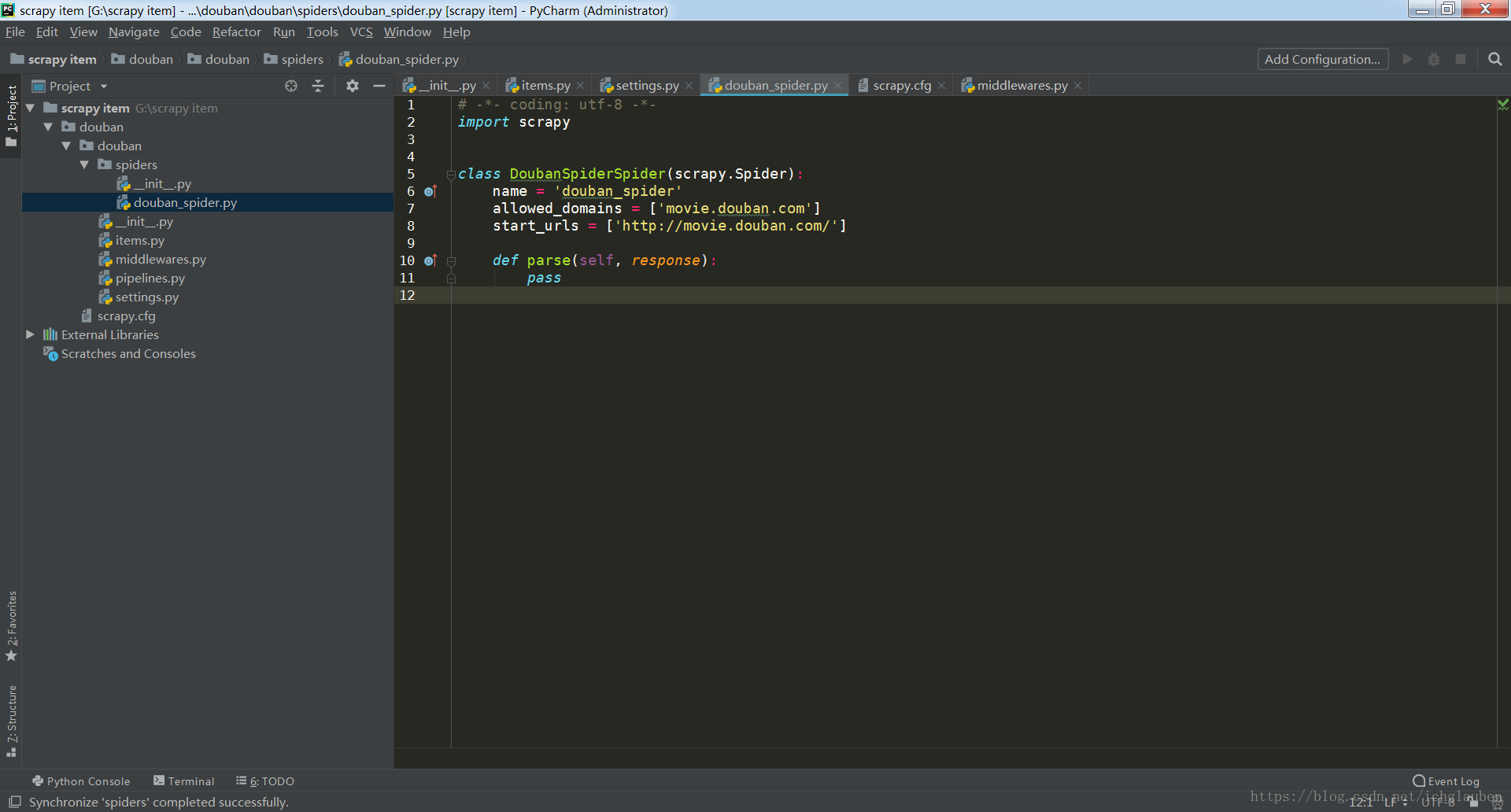
3、命令行中运行(spiders目录下):
scrapy crawl spiderName
其中,spiderName为 你建立的spiderFileName.py文件 中 name的值,默认与spiderFileName相同
4、在pycharm中直接运行项目:
可以在setting.py同目录下新建一个main.py文件,内容为:
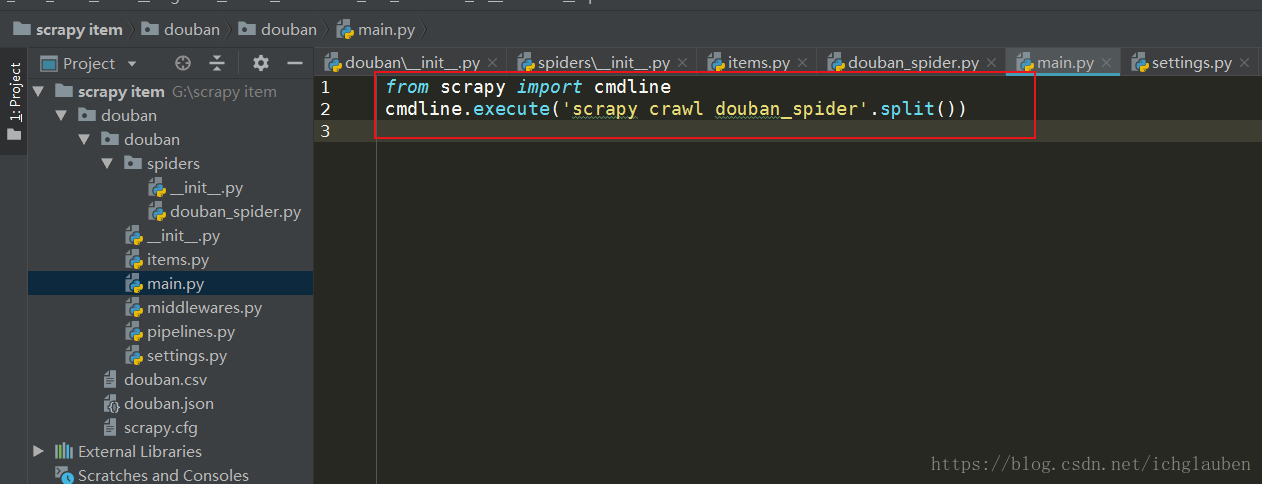
|
后续在pycharm中需要运行项目时,只需要运行此文件即可
5、将爬到的数据存储到文件中,比如 test.json或test.csv或其它,在spiders文件夹下执行cmd指令:
|
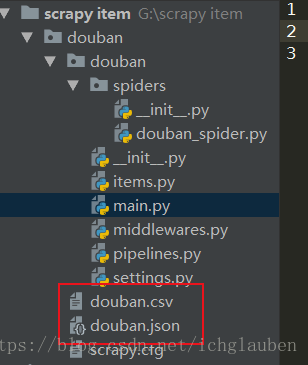
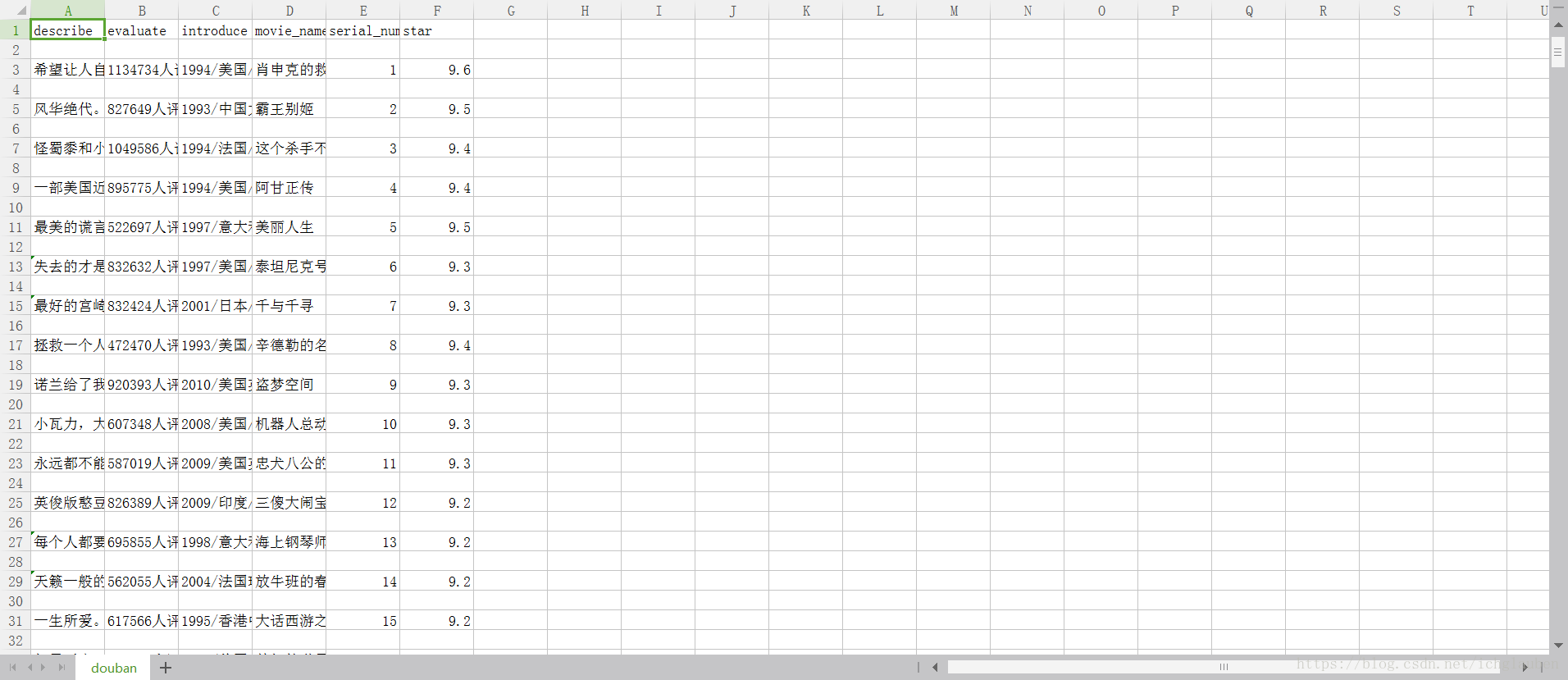
可以在spiders目录下看到一个test.json文件,文件编码utf-8,如果用Excel打开csv文件为乱码,可以使用文本编辑器修改编码为utf-8(bom)即可
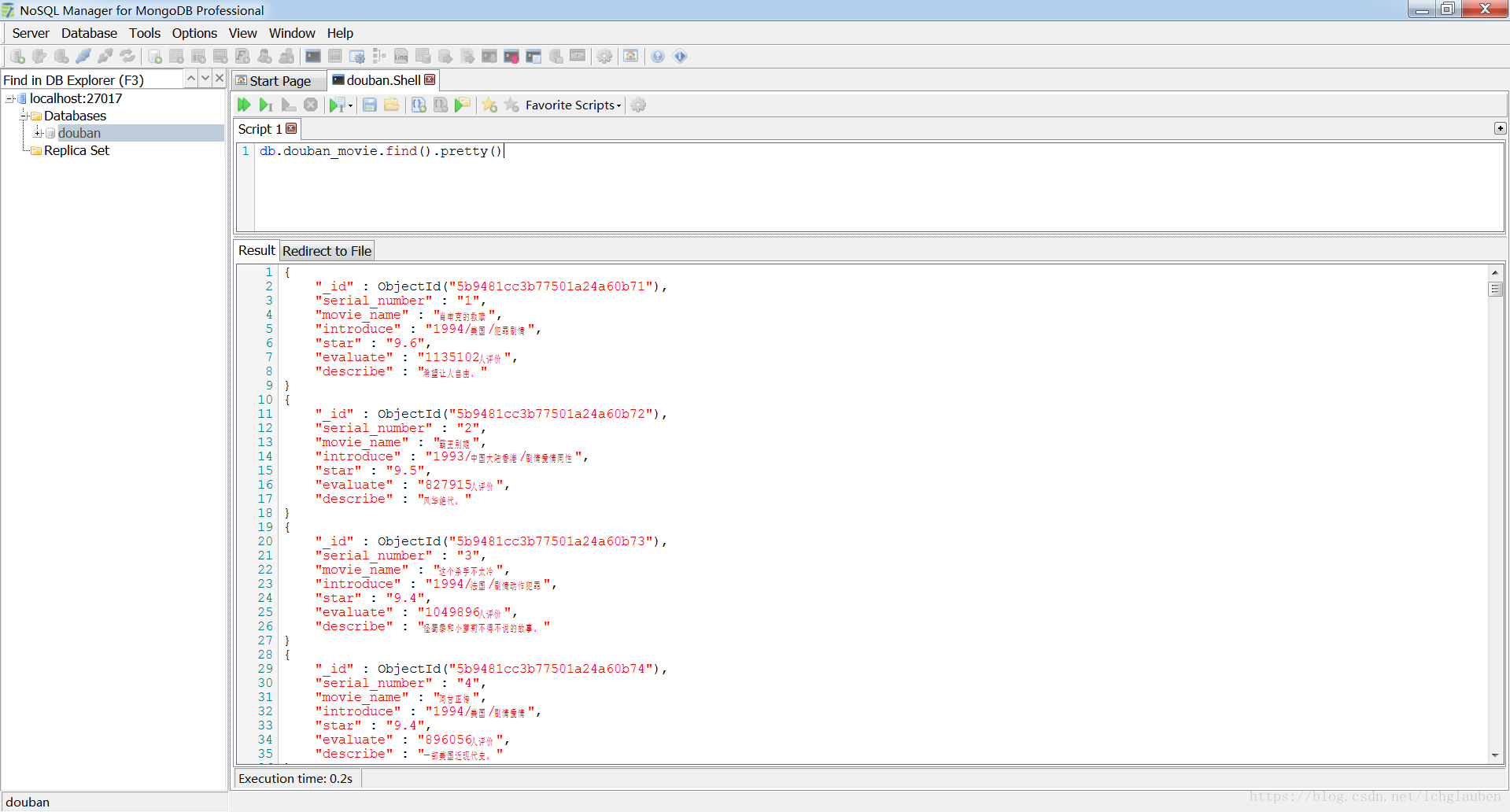
6、将爬到的数据存储到mongo数据库
mongodb GUI管理工具下载

















 6612
6612

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









