




AdaBoost
martin
AdaBoost是典型的Boosting方法,并且效果很显著。下图是AdaBoost的框架图:
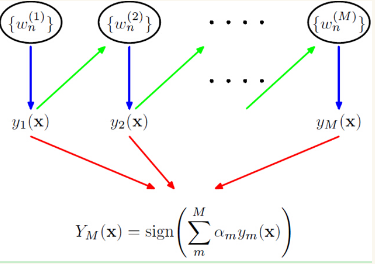
算法过程
下面介绍AdaBoost算法的过程:
1. 初始化训练数据的权值分布:
2. 对
m=1,2,...,M
(a) 使用具有权值分布
Dm
的训练集学习,得到基本分类器:
(b) 计算 Gm(x) 在训练数据集上的分类误差:
(c) 计算 Gm(x) 的系数:
(d) 更新数据集的权值分布:
(e) 重复 (a)−(d) 步 m 次得到
3. 构建基本分类器的线性组合:
4. 最终得到分类器:
基分类器权值
a
与训练数据集权值w 的分析
1. 先来看基分类器的权值
α
,公式如下:
我们知道AdaBoost是将多个弱分类器组合起来形成一个很强的分类器,但这里有个隐含条件:弱分类器。什么叫弱分类器?意思就是在效果上比随机猜想要好的分类器。比如二分类问题,随机猜想的正确率是0.5,所以说弱分类器的正确率一定要比0.5高,于是它的错误率 em<0.5 ,所以 α会随着em的减小而增大 ,这是什么意思?意思是,如果我的基分类器的错误率很小,也就是正确率很大,那么在众多基分类器中我给予它很大的权值 α ,让它能发挥更大的作用。
2. 再来看训练数据集分布的权值分配,公式如下:
由公式可知,对训练集的样例正确分类与错误分类之间,错误分类样本的权值被放大: e2αm=1−emem 倍,所以,在下一轮学习中将会被更大关注。
AdaBoost推导
AdaBoost模型是由基本分类器组成的 加法模型 ,损失函数是 指数函数 。
1. 加法模型: f(x)=∑Mm=1αmGm(x)
2. 损失函数: L(y,f(x))=e−yf(x)
3. 每次训练后的基分类器都是乘以
α
再与前一个模型线性相加,所以对于第
m−1
次训练后模型为:
4. 于是,在第
m
次训练后有:
5. 目标是每一次的损失在训练集上最小,所以最小化目标函数为:
上式中,将 e−yifm−1(xi)=wmi ,因为 wmi 既不依赖 α 也不依赖与 G ,所以与最小无关。
6. 于是,有:
所以,我们得到了优化的目标函数:
7. 对6中的目标函数关于
α
求导,令
∂L(α)∂α=0
,求的最小值:
等价于:
因为: em=∑Ni=1wmiI(yi≠Gm(xi)) , ∑Ni=1wmi=1
所以有:
等价于:
解得:
8. 由于之前有个假设:
wmi=e−yifm−1(xi)
,而这个式子又可以化为:
于是,就有了更新公式:
参考:
[1] 《统计学习方法》李航

















 426
426

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









