



O_DIRECT和O_SYNC是系统调用open的flag参数。通过指定open的flag参数,以特定的文件描述符打开某一文件。
这两个flag会对写盘的性能有很大的影响,因此对这两个flag做一些详细的了解。
先看一个open函数的使用例子.
/* Open new or existing file for reading and wrting,sync io and no buffer io;
file permissions read+ write for owner, nothing for all others */
fd = open("myfile", O_RDWR | O_CREAT | O_SYNC | O_DIRECT, S_IRUSR | S_IWUSR);
if (fd == -1)
errExit("open");
O_DIRECT: 无缓冲的输入、输出。
O_SYNC:以同步IO方式打开文件。
下面对这两个flag做一些详细的说明。
一,O_DIRECT,绕过缓冲区高速缓存,直接I/O
直接IO: Linux允许应用程序在执行磁盘IO时绕过缓冲区高速缓存,从用户空间直接将数据传递到文件或磁盘设备,称为直接IO(direct IO)或者裸IO(raw IO)。
应用场景: 有特定I/O需求的应用。如数据库系统,其高速缓存和IO优化机制均自成一体,无需内核消耗CPU时间和内存去完成相同的任务。
使用直接IO的弊端: 可能会大大降低性能,内核对缓冲区高速缓存做了不少优化,包括:按顺序预读取,在成簇(clusters)磁盘块上执行IO,允许访问同一文件的多个进程共享高速缓存的缓冲区。
使用方法: 针对一个单独文件或块设备(比如,一块磁盘)执行直接I/O。需要在调用open()函数打开文件或设备时指定O_DIRECT标志。
注意可能发生的不一致性: 若一进程以O_DIRECT标志打开某文件,而另一进程以普通(即使用了高速缓存缓冲区)打开同一文件,则由直接IO所读写的数据与缓冲区高速缓存中内容之间不存在一致性,应尽量避免这一场景。
**直接I/O的对齐限制:**因为直接I/O(针对磁盘设备和文件)涉及对磁盘的直接访问,所以在执行I/O时,必须遵守一些限制。
使用直接IO需要遵守的一些限制:
• 用于传递数据的缓冲区,其内存边界必须对齐为块大小的整数倍
• 数据传输的开始点,即文件和设备的偏移量,必须是块大小的整数倍
• 待传递数据的长度必须是块大小的整数倍。
不遵守上述任一限制均将导致EINVAL错误。在上述列表中,块大小(block size)指设备的物理块大小(通常为512字节)。
当执行直接I/O时,Linux 2.4比Linux 2.6限制更为严格:对齐、长度及偏移量必须是底层文件系统逻辑块大小的整数倍。(典型文件系统的逻辑块大小为1024、2048或4096字节。)
分配内存可以使用memalign()函数来达到文件和设备的偏移量对齐,其内存块与第一个参数的整数倍对齐。
二,O_SYNC,以同步方式写入文件
功能: 强制刷新内核缓冲区到输出文件。这是有必要的,因为为了数据安全,需要确保将数据真正写入磁盘或者磁盘的硬件告诉缓存中。
我们先熟悉一下同步IO相关定义和系统调用。
同步IO数据完整性和同步IO文件完整性
同步IO的定义: 某一IO操作,要么已成功完成到磁盘的数据传递,要么被诊断为不成功。
SUSv3定义的两种同步IO完成类型
synchronized IO data integrity completion: 确保针对文件的一次更新传递了足够的信息(部分文件元数据)到磁盘,以便于之后对数据的获取。
synchronized IO file integrity completion: 确保针对文件的一次更新传递了所有的信息(所有文件元数据)到磁盘,即使有些在后续对文件数据的操作并不需要。
用于控制文件IO内核缓冲的系统调用
1 fsync
#include
int fsync(int fd);
功能:
fsync()系统调用将使缓冲数据和fd相关的所有元数据都刷新到磁盘上。调用fsync会强制使文件处于Synchronized IO file integrity completion状态。
函数返回值:
0: success
-1: error
返回时间:仅在对磁盘设备(或者至少是其高速缓存)的传递完成后,fsync()调用才会返回。
2 fdatasync
#include
int fdatasync(int fd);
功能:
fdatasync()系统调用的作用类似fsync(),只是强制文件处于synchronized IO data integrity compeletion状态。
函数返回值:
0: success
-1: error
与fsync的区别:fdatasync()可能会减少磁盘操作的次数,由fsync()调用请求的两次变成一次。例如,修改了文件的数据,而文件大小不变,那么调用fdatasync调用请求只强制进行了数据更新,相比之下,fsync()调用会强制将元数据传递到磁盘上,而元数据和文件数据通常驻留在磁盘的不同区域,更新这些数据需要反复在整个磁盘上执行寻道操作。
3 sync系统调用
#include
void sync(void);
功能:
sync()系统调用会使包含更新文件信息的所有内核缓冲区(即数据块、指针块、元数据等)刷新到磁盘上。
若内容发生变化的内核缓冲区在30s内未经显式方式同步到磁盘上,则一条长期运行的内核线程会确保将其刷新到磁盘上。这一做法是为了规避缓冲区与相关磁盘文件内容长期处于不一致状态。
4 使所有写入同步:O_SYNC
调用open()函数时,如制定O_SYNC标志,则会使所有后续输出同步。
fd = open(pathname, O_WRONLY | O_SYNC);
调用open后,每个write调用会自动将文件数据和元数据刷新到磁盘上,即按照Synchronized IO file integrity completion的要求执行写操作。
5 有无O_SYNC性能对比
场景:将一百万字节写入一个ext2文件系统上的新创建文件,比较写入时间。
对比结果:
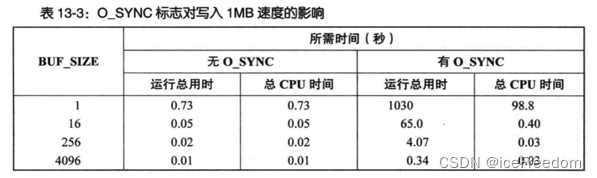
从结果中可以得到的结论:
• 采用O_SYNC标志(或者频繁调用fsync(), fdatasync()或sync())对性能影响极大。
• 性能下降的直接表现为运行总用时大为增加:在缓冲区为1字节的情况下,运行时间相差1000多倍。
• 以O_SYNC标志执行写操作时运行总用时和CPU时间之间的巨大差异(1030 - 98.8),原因是系统在每个缓冲区中将数据向磁盘传递时会把程序阻塞起来。
三,IO缓冲层次关系
先总结一下stdio函数库和内核采用的缓冲这两级缓冲,然后用图说明两层缓冲机制和各种缓冲类型的控制机制。
首先,通过stdio库将用户数据传递到stdio缓冲区,该缓冲区位于用户态内存区。当缓冲区填满,stdio库会调用write()系统调用,将数据传递到内核高速缓冲区,该缓冲区位于内核态内存区。最终,内核发起磁盘操作。
该层次结构如下图所示
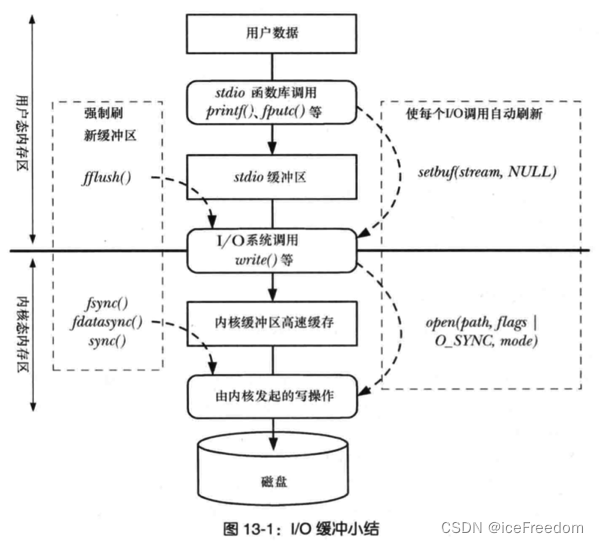
上图中,左侧虚线方框中为可于任何时刻显式强制刷新各类缓冲区的调用。
右侧所示为促使刷新自动化的调用:通过禁用stdio的缓冲,和在文件输出类的系统调用中启用同步,从而使每个write()调用立刻刷新到磁盘。
四,小结
输入输出数据的缓冲由内核和stdio库完成。有时可能希望阻止缓冲,但这需要了解其对应用程序性能的影响。
可以使用各种系统调用和库函数来控制内核和stdio缓冲,并执行一次性的缓冲区刷新。
在Linux环境下,open()所特有的O_DIRECT标识允许特定应用跳过缓冲区高速缓存。

















 1342
1342

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









