




 RCU(Read-Copy-Update)是一种用于多线程环境的数据结构保护机制,确保在更新数据时不会出现不一致的情况。其基本流程包括复制旧数据、修改副本、发布新数据和安全地释放旧数据。在RCU中,读者可以无阻塞地读取数据,直到所有读者完成读取,然后才释放旧数据,从而保证了数据一致性。
RCU(Read-Copy-Update)是一种用于多线程环境的数据结构保护机制,确保在更新数据时不会出现不一致的情况。其基本流程包括复制旧数据、修改副本、发布新数据和安全地释放旧数据。在RCU中,读者可以无阻塞地读取数据,直到所有读者完成读取,然后才释放旧数据,从而保证了数据一致性。
基本原理
RCU的基本思想是这样的:先创建一个旧数据的copy,然后writer更新这个copy,最后再用新的数据替换掉旧的数据。这样讲似乎比较抽象,那么结合一个实例来看或许会更加直观。
假设有一个单向链表,其中包含一个由指针p指向的节点:
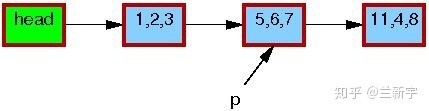
现在,我们要使用RCU机制来更新这个节点的数据,那么首先需要分配一段新的内存空间(由指针q指向),用于存放这个copy。
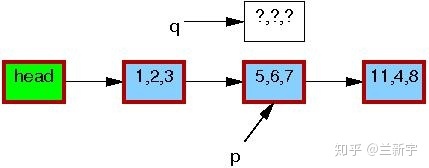
然后将p指向的节点数据,以及它和下一节点[11, 4, 8]的关系,都完整地copy到q指向的内存区域中。
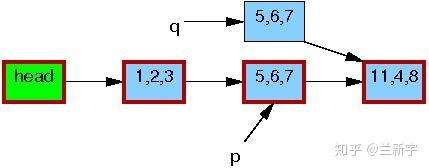
接下来,writer会修改这个copy中的数据(将[5, 6, 7]修改为[5, 2, 3])。
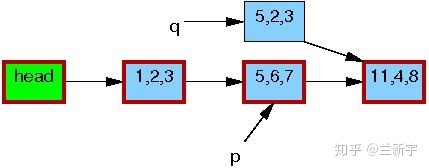
修改完成之后,writer就可以将这个更新“发布”了(publish),对于reader来说就“可见”了。因此,pubulish之后才开始读取操作的reader(比如读节点[1, 2, 3]的下一个节点),得到的就是新的数据[5, 2, 3](图中红色边框表示有reader在引用)。
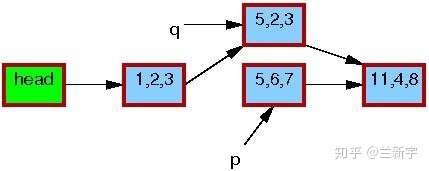
而在publish之前就开始读取操作的reader则不受影响,依然使用旧的数据[5, 6, 7]。
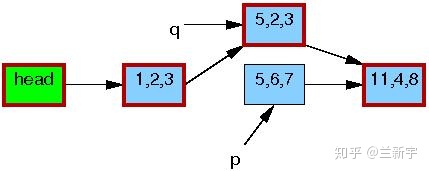
等到所有引用旧数据区的reader都完成了相关操作,writer才会释放由p指向的内存区域。
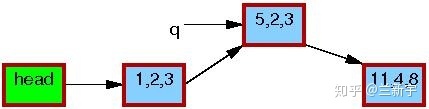
可见,在此期间,reader如果读取这个节点的数据,得到的要么全是旧的数据,要么全是新的数据,反正不会是「半新半旧」的数据,数据的一致性是可以保证的。重要的是,RCU中的reader不用像rwlock中的reader那样,在writer操作期间必须spin等待了。
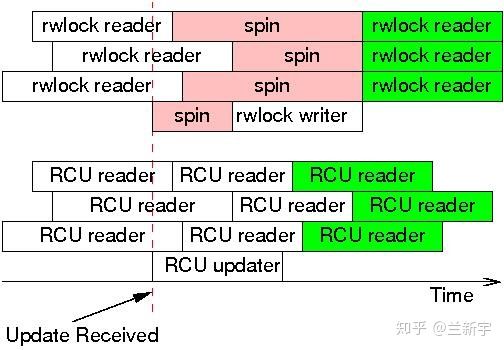
RCU的全称是"read copy update",可以这样来理解:read和进行copy的线程并行,目的是为了update。好像有点"copy on write"的意思?反正有人觉得RCU的命名不够准确,宁愿叫它"publish protocol"(比如 Fedor Pikus)。不管怎样,RCU的命名已经成了业界默认的,我们还是就叫它RCU吧。

















 1475
1475

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









