



作者:晴筱、铭辉
本文介绍在C3级代码仓库中落地LLM代码评审的Agent实践。针对C3仓库禁用闭源模型的安全要求,基于Qwen3-Coder、RAG、iFlow实现,通过百炼Embedding构建知识索引,RAG知识库与生产代码同仓管理,文档与代码共生命周期保障一致性,AI辅助人工代码评审。
在CI流水线监听代码修改自动触发AI评审,LLM进行代码解释、逻辑分析和识别并发缺陷、资源泄漏、边界错误、性能瓶颈及规范问题。以块存储C/C++百万行大库为例,已累计执行上千次评审,并部署至存储统一代码门禁平台,支持平台接入所有仓库。
实践表明,AI可有效发现传统CR易忽略的逻辑风险,已数十次成功拦截高危缺陷,显著提升评审效率与质量。当前持续优化准确性、误报率、采纳率,增强上下文感知,探索修复建议生成。该实践可复用于各类代码门禁平台或AI辅助编程工具。
人机协同:AI代码评审的优势和局限
术语说明
1.RAG(Retrieval-Augmented Generation):是一种融合检索与生成的技术,通过从外部知识库(如文档、数据库)获取信息并注入提示(Prompt),使大语言模型基于最新、可信数据生成回答,提升准确性与实时性,缓解知识局限、幻觉和安全风险,广泛应用于私域知识问答场景。
2.iFlow CLI:基于Gemini CLI改造,模型均集团内部部署,完美适配Kimi-K2, Qwen3 Coder模型,可使用在C3代码。
3.Qwen3-Coder:一个480B 参数、35B有效参数、原生支持256K上下文的开源 MoE 智能编程引擎。
应用场景
Code Review 是 LLM 辅助的理想切入点,因为代码评审容错性高,且旨在增强而非取代人工环节。
然而,传统人工评审成本高、效率低,且评审质量严重依赖个人经验,复杂系统的逻辑缺陷和深层问题容易被遗漏。团队虽已使用 Copilot 完成数千次评审,但其发现的问题主要集中于语法级错误,缺乏上下文理解与逻辑推理能力,难以识别系统级缺陷;如果没有见过具体垂直领域的保密数据,模型通常在某个公司内部具体业务系统上表现欠佳。
同时,团队主仓库为 C3 级安全等级,无法使用 Cursor、Qoder 等工具。团队基于 Qwen3-Coder 构建评审 Agent,通过 RAG 注入私域知识(如设计文档、历史缺陷),增强 LLM 的上下文感知能力,并结合 Iflow 实现自动化工作流。Agent 部署于 CI 流水线,代码提交后自动触发评审,如下图所示,辅助开发者完成逻辑检查与风险分析,提升代码评审效率与质量。
| 示例 1,代码改动5000行左右 | 示例 2,代码改动1500行左右 |
| 风险采纳率80%(8个被采纳:潜在越界,除零,参数错配等问题)
| Top2 风险采纳:1. 缺失边界索引检查;2.多线程并发访问
|


优势局限
LLM + RAG 代码评审并非替代人工,而是作为“初级评审助手”,在提交前提供自动化逻辑预检。
用户普遍反馈 LLM 评审在代码逻辑总结方面表现出色,在风险分析缺陷发现方面符合预期,已多次有效辅助发现边界场景、并发访问、资源泄漏等缺陷。尽管如此,LLM 评审也存在模型输出不稳定、误报等问题,在对比其风险缺陷发现能力时,LLM+RAG评审与传统方法的优劣势如下表所示:
| 对比 | 新方式发现缺陷(LLM 代码评审) | 传统方式发现缺陷 (FuzzyTest、Asan) |
| 优势 | 1. 在代码提交前预判潜在边界场景/并发访问等 2.主动预防(提交前),基于私域知识库 + 语义理解 3.边际成本趋近于零,质量随模型能力和知识库提升 | 1. 对特定类型缺陷的发现具有高精度和可靠性 2.测试结果可稳定复现,便于定位和修复问题 3.已有测试用例覆盖后,有效拦截相同缺陷 |
| 劣势 | 1. LLM 模型输出不稳定,存在幻觉,易误报 2.上下文长度有限(当前最大支持 200K token) 3.输出质量依赖 RAG 知识库和Prompt引导质量 | 1. 对未知和新缺陷发现能力有限,依赖已有测试 2.被动防御,无法预判,基于随机变异 + 反馈驱动 3.构建和维护成本高,时间成本随接口线性增长 |
如何构建:Qwen3-Coder+RAG实现
工作流部署
流程:Webhook代码监听 → 知识库向量检索 → Promp引导拼接 → 输入LLM → 输出返回结果;
实现:RAG + iFlow + Qwen3-Coder,RAG使用的是百炼的 text-embedding-v4 模型进向量数据库索引;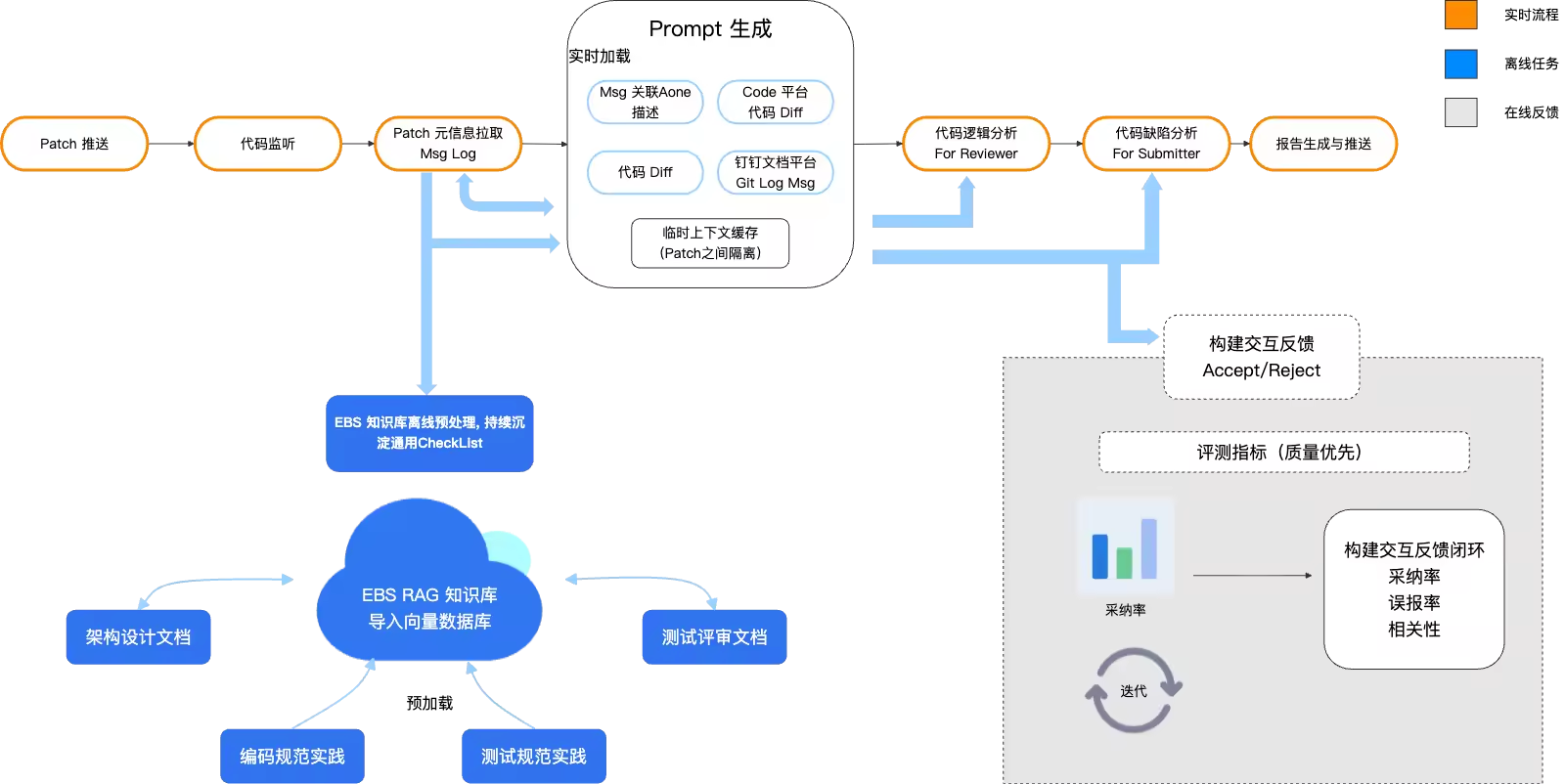
知识库构建
我们并非从零撰写知识库,而是收集了团队多年沉淀的知识资产,将已有的系统设计、组件介绍、编码规范、测试规范、测试设计模版等高质量文档,转化为大模型可用的格式,知识库整理和流程步骤图转文字均通过公司内部IdeaLab Gemini生成后人工校对再提交,构建过程如下:
| 构建步骤 | 实现流程 |
| 知识格式化 (Formatting) | 1. 动作: 将团队沉淀的 PDF、PPT 等异构文档,批量转换为 LLM 友好的结构化 Markdown; 2.关键点: 利用多模态模型将文档中的架构图、流程图解析为文字描述,确保知识无损。 |
| 向量化入库 (Embedding) | 1. 动作: 对 Markdown 文档进行语义切分 (Chunking),再调用 text-embedding-v4 模型生成向量索引; 2.目标: 建立从代码到高相关度知识片段的精准、高效检索通道。 |
| 版本化同步 (Version Sync) | 1. 动作: 参考开源社区,采用 “Docs-as-Code” 方式,将知识库与代码库在同一 Git 仓库中管理; 2.机制: 知识文档的变更须通过 PR 流程,与代码变更一同评审,确保二者生命周期强一致性。 |
| CheckList 规则 (Rules) | 1. 动作: 从知识库中提炼出关键场景、可机读的评审规则集 (Checklist); 2.范围: 聚焦分布式存储场景,如:防御性编码最佳实践、历史故障模式、强一致性校验等。 |
输入给LLM之前进行RAG检索的时候,是从Agent服务所在的本地向量数据库faiss消费数据,并非从git仓库实时获取;git仓库管理知识库只是作为人与人之间方便共享、知识库与代码之间同步的远程存储工具;所以RAG每次检索并非git仓库最新的版本,而是离线定时更新Word2Vec到本地向量知识库(该实现机制和Cursor的Code2Vec和Word2Vec后台向量知识库更新一致)。
代码仓库Documentation包含design/test目录保存文档,ebs/Documentation/README.md 文件如下图所示: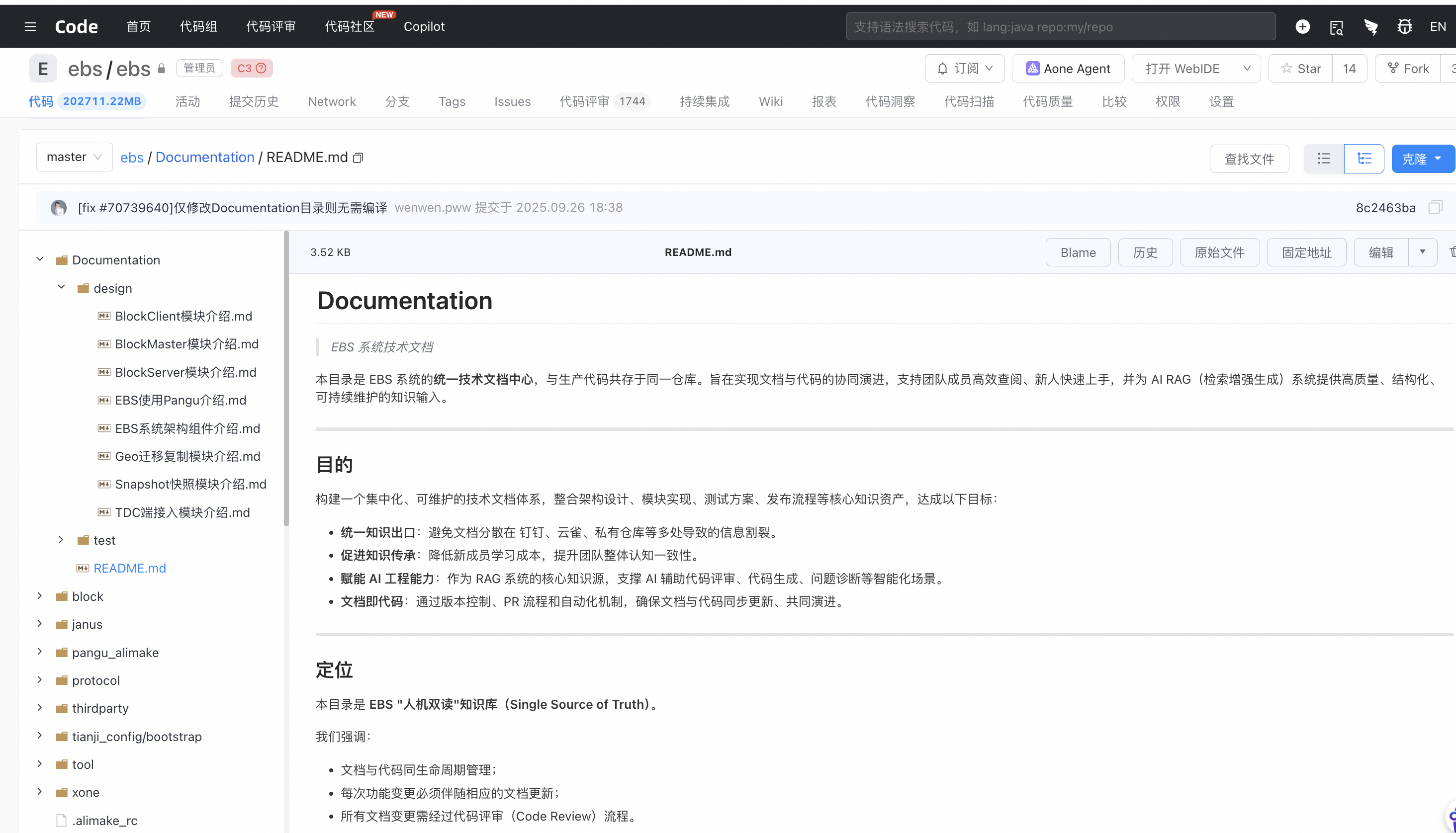
提示词设计
- Prompt 模板设计: 角色 + 原则 + CoT思维链 + 输出规范 + Few-Shot 少样本学习,引导 LLM;
- 交互策略设计: 区分 For Reviewer (逻辑解释)、For Submitter (风险分析)、LLM汇总 三种角色。
For Reviewer.md
你的任务是生成一份专业的 EBS CodeReview 分析报告,供代码审查者参考。报告必须包含以下结构和内容: ## 格式要求 1. 使用 Markdown 格式 2. 标题为 "# EBS CodeReview For Reviewer 总结报告" 3. 报告必须保存到 /tmp/ebs_code_review.{PatchId}.reviewer.md 文件中 4. 使用 **加粗** 标记关键信息和重要结论 5. 使用项目符号列表组织内容,使结构更清晰 6. 每个主要章节使用 ## 标题,子章节使用 ### 标题 ## 内容要求 1. 代码变更核心目的: - **明确描述**本次代码变更要解决的核心问题或实现的功能 - 简洁清晰,直击要点 - 使用加粗突出核心目的 2. 代码变更原因和原理: - **详细说明**变更的技术背景和原因 - **深入分析**实现原理和设计思路 - **解释**关键技术点和创新之处 - 按小节组织内容(如:变更背景、实现原理等) 3. 主要变更点概览: - **按模块分类**列出所有重要变更 - **对每个变更点提供详细说明** - **指出关键文件和函数的修改** - 使用加粗和项目符号突出重要信息 - BlockMaster 端、Client 端、协议层等分别详细说明 4. 对 EBS 系统的影响和作用: - **分析**变更对系统整体架构的影响 - **评估**性能、稳定性、安全性等方面的改进或风险 - **说明**变更的业务价值 - 使用加粗突出正面影响和潜在风险 5. Code Review 重点关注: - **从架构设计、性能优化、异常处理、代码质量等维度**指出需要重点关注的地方 - **指出潜在的风险点和技术债** - **提供具体的审查建议** - 按维度分类(架构设计层面、性能优化方面、异常处理方面、代码质量方面等) 6. 建议和改进点: - **基于深入分析提出具体的改进建议** - **按风险等级分类建议项**(如:性能监控、配置调优、错误处理优化等) ## 内容深度要求 1. 分析必须**全面、深入、细致**,不遗漏任何重要变更点 2. 每个技术点都要**解释清楚原因和实现方式** 3. 要结合 EBS 系统特点进行分析 4. 要**具体指出**文件名、函数名、关键代码逻辑 5. 要**评估影响**,包括正面和负面 ## 表达方式要求 1. 使用**专业但易懂**的技术术语 2. 使用**加粗**强调关键信息、重要结论、核心概念 3. 使用**项目符号列表**组织并列内容 4. 使用**清晰的逻辑结构**,段落之间有良好的过渡 5. **条理清晰**,先总后分,先重要后次要 ## 分析流程 1. 通过读取以下文件获取 Patch 修改的基本信息: 1.1 /tmp/ebs_code_review.{PatchId}.merge_request_detail (Patch 基本内容) 1.2 /tmp/ebs_code_review.{PatchId}.changed_files_list (变更文件列表) 1.3 /tmp/ebs_code_review.{PatchId}.changed_files_diff (详细变更信息) 1.4 /tmp/ebs_code_review.{PatchId}.doc (钉钉文档内容,可能不存在) 2. 深入分析代码变更: 2.1 仔细阅读每个变更文件的 diff 2.2 理解变更的核心目的和实现原理 2.3 结合 EBS 系统架构进行分析 3. 利用辅助工具增强分析: 3.1 使用 ebs_doc_rag 工具获取 EBS 架构文档 3.2 使用 ebs_doc_rag 工具获取 EBS 代码规范 4. 生成专业报告: 4.1 报告内容必须**准确、详细、有条理** 4.2 分析必须**深入、客观、有理有据** 4.3 重点关注点必须**具体、可操作** 4.4 **务必参考示例文件的格式和表达方式**
For Submitter.md
你的任务是生成一份专业的 EBS CodeReview Bug 分析报告,供代码提交者参考以改进代码质量。报告必须包含以下结构和内容: ## 格式要求 1. 使用 Markdown 格式 2. 标题为 "# EBS CodeReview ForSubmiter 总结报告" 3. 报告必须保存到 /tmp/ebs_code_review.{PatchId}.submitter.md 文件中 4. 使用 **加粗** 标记关键信息和重要结论 5. 使用项目符号列表组织内容,使结构更清晰 6. 每个主要章节使用 ## 标题,子章节使用 ### 标题 7. 问题描述使用标准格式(风险等级标识、问题标题、问题描述、代码范围、修改建议) ## 内容要求 1. 代码变更核心目的: - **简明扼要地重述**本次代码变更的核心目的 - **说明**变更的技术背景 - 使用加粗突出核心目的 2. 主要变更原理: - **按模块详细分析**各个部分的实现原理 - **重点解释**关键技术点和设计思路 - BlockMaster端、客户端、协议层等分别详细说明 - 使用加粗和项目符号突出重要信息 3. 发现的问题和修改建议: - **按风险等级分类**(🔴高风险 🟡中风险 🟢低风险) - **每个问题必须包含**: * **清晰的问题标题**(带风险等级标识) * **详细的问题描述** * **具体的代码范围**(文件名和行号) * **明确的修改建议** - 问题必须**基于代码分析,有理有据**,不能无中生有 - 使用加粗突出关键问题和建议 4. 测试代码分析: - **分析**测试代码是否覆盖了关键场景 - **评估**测试的完整性和有效性 - **指出**测试中可能存在的问题或改进建议 - 使用加粗突出测试覆盖情况和改进建议 5. 总结: - **综合评估**代码变更的整体质量 - **提出**最终建议 - 使用加粗突出最终结论 ## 分析维度要求 在分析问题时,请从以下维度全面评估代码质量: - **逻辑正确性**:新增代码逻辑是否正确实现预期功能 - **边界条件**:异常情况、边界值处理是否完善 - **资源管理**:内存、文件句柄等资源是否正确释放 - **并发安全**:多线程环境下是否存在竞态条件 - **性能影响**:是否有潜在性能瓶颈或不当的性能优化 - **安全性**:是否存在安全漏洞或不当的安全处理 - **可维护性**:代码结构、命名、注释是否清晰 - **兼容性**:是否存在兼容性问题 - **可扩展性**:是否存在可扩展性问题 ## 内容深度要求 1. 分析必须**全面、深入、细致**,不遗漏任何重要问题 2. 每个问题都要**详细描述原因和影响** 3. 要结合 EBS 系统特点进行分析 4. 要**具体指出**文件名、函数名、行号 5. 要**提供可操作的修改建议** ## 表达方式要求 1. 使用**专业但易懂**的技术术语 2. 使用**加粗**强调关键信息、重要结论、核心概念 3. 使用**项目符号列表**组织并列内容 4. 使用**清晰的逻辑结构**,段落之间有良好的过渡 5. **条理清晰**,先总后分,先重要后次要 6. 问题描述要**结构化**,便于理解和修复 ## 分析流程 1. 通过读取以下文件获取 Patch 修改的完整信息: 1.1 /tmp/ebs_code_review.{PatchId}.merge_request_detail (Patch 基本内容) 1.2 /tmp/ebs_code_review.{PatchId}.changed_files_list (变更文件列表) 1.3 /tmp/ebs_code_review.{PatchId}.changed_files_diff (详细变更信息) 1.4 /tmp/ebs_code_review.{PatchId}.doc (钉钉文档内容,可能不存在) 1.5 /tmp/ebs_code_review.{PatchId}.reviewer.md (Reviewer分析报告,帮助理解变更目的) 2. 深入分析代码变更: 2.1 逐文件、逐段分析所有代码变更 2.2 结合上下文全面理解代码逻辑 2.3 识别潜在问题和改进点 3. 利用辅助工具增强分析: 3.1 使用 ebs_doc_rag 工具获取 EBS 代码规范 3.2 使用 ebs_doc_rag 工具获取 EBS 架构信息 4. 生成专业报告: 4.1 按风险等级分类所有发现的问题 4.2 每个问题都必须有明确的修改建议 4.3 报告结构清晰,内容准确详实 4.4 **务必参考示例文件的格式和表达方式**
LLM汇总.md
1. 读取核心报告总结内容 1.1 CodeReview For Reviewer 的报告总结文件路径: /tmp/ebs_code_review.{PatchId}.reviewer.md 1.2 CodeReview For Submitter 的报告总结文件路径: /tmp/ebs_code_review.{PatchId}.submitter.md 1.3 CodeReview 生成的总体流程图的 Url 链接存放路径: /tmp/ebs_code_review.{PatchId}.url 2. 整合多分报告, 并按照 Markdown 方式合并生成. 注意: 必须不能遗漏, 清晰分类, 重复的只保留 For Reviewer, 链接要支持用 [总体流程分析链接](...) 方式跳转 2.1 结果要写入到本地 /tmp/ebs_code_review.{PatchId}.summary 2.1 输出结果 - 代码变更核心目的 (背景 + 目的) - 主要变更原理 - 代码审查发现的潜在问题 - 测试代码覆盖情况 - 对 EBS 系统的影响和作用 (正面影响 + 潜在风险) - 总结 3. 通过 aone mcp comment_merge_request 接口统一上传到 CR 中
落地实践:CI代码门禁的自动化集成
CI 流水线集成
我们与存储代码门禁平台团队合作,将AI Agent工作流嵌入到门禁平台,支持平台所有接入仓库,不同角色的实现交互:
| 定位角色 | 交互实现 |
| 服务部署 (系统维护者) | 1. 部署: Agent工作流被打包为Docker镜像,以Serverless服务形式,弹性部署于代码门禁k8s集群; 2.特点: 结果存储在中心化数据库中,实现了服务的快速伸缩、资源隔离与高可用。 |
| 开发者使用 (代码提交者) | 1. 使用: 提交 pull request 评审被自动触发,AI评审意见以PR评论呈现,过程对用户完全透明; 2.策略: 代码平台采用“强制确认 (Confirm)”策略,确保建议被审阅,但预检风险不阻塞代码合并。 |
| 仓库接入 (仓库管理员) | 1. 接入方式: 在仓库根目录创建docs知识库,服务将自动纳管并定时同步; 2.维护职责: 管理员仅需维护docs内容及可选的 Prompt,无需关心底层部署实现。 |
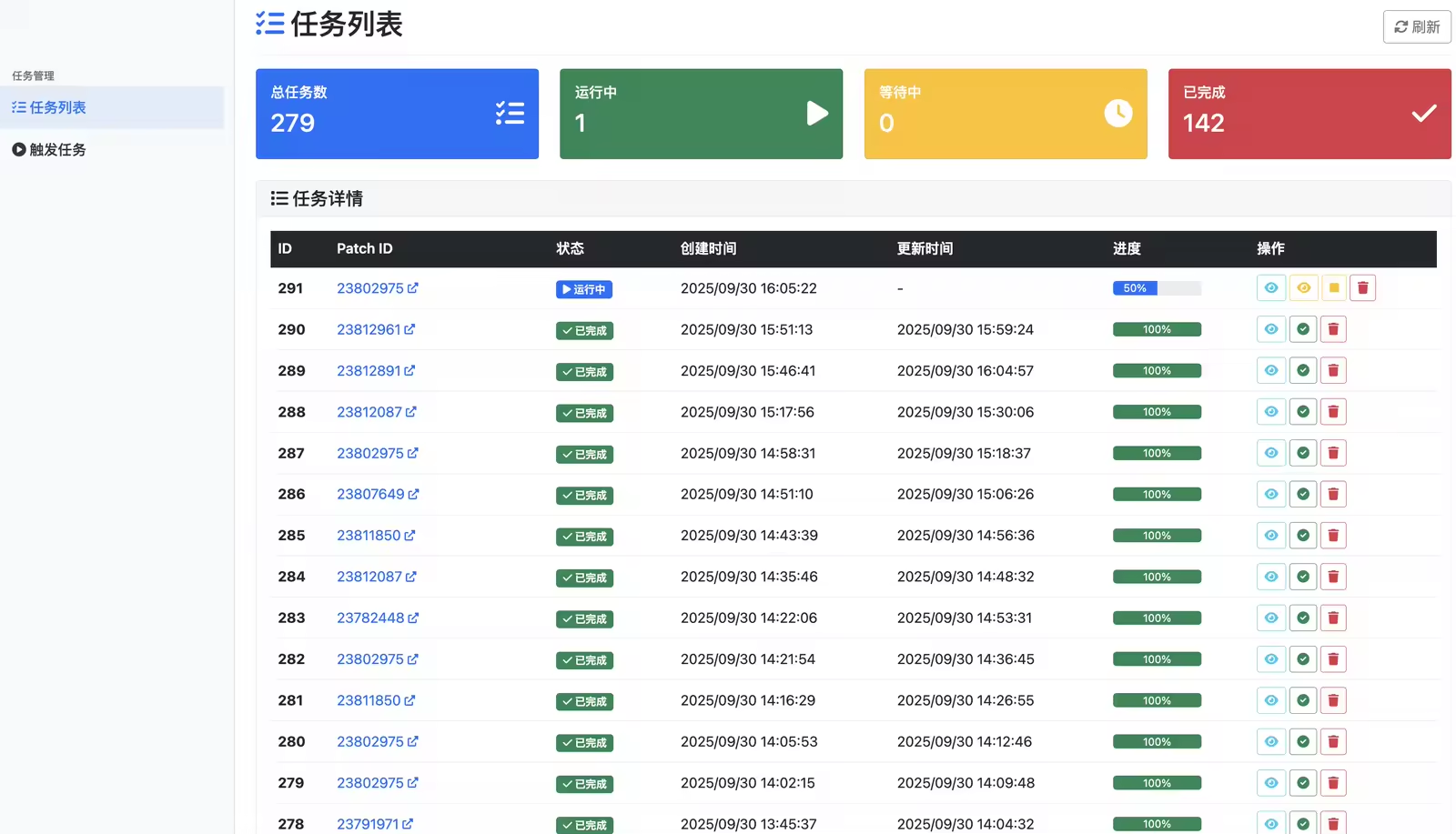
代码门禁webhook监听触发的AI评审任务列表如下图所示:
上下文构建
代码评审聚合“在线上下文”(短期记忆)和“离线知识库”(长期记忆)信息,构建成一个完整的Prompt输入给大模型作为决策依据。
| 信息加载 | 信息内容 | 实现方式 |
| 在线上下文 (Patch 特有) | 代码变更 (Code Diff) | 实时获取本次 pull request 的代码变更文件。 |
| 变更原因 (Change Intent) | 自动解析Git Message 中的关联链接,通过API实时获取Aone需求/缺陷单、钉钉设计/测试文档的完整正文。 | |
| 离线知识库 (通用沉淀) | 领域知识 (Domain Knowledge) | 基于代码变更的语义,从预处理的向量化知识库中,通过 RAG 服务检索最相关的设计/编码/测试文档。 |
每个Patch强制要求关联Aone单,建议关联设计/测试钉钉文档,标准规范Git Log Message如下图所示: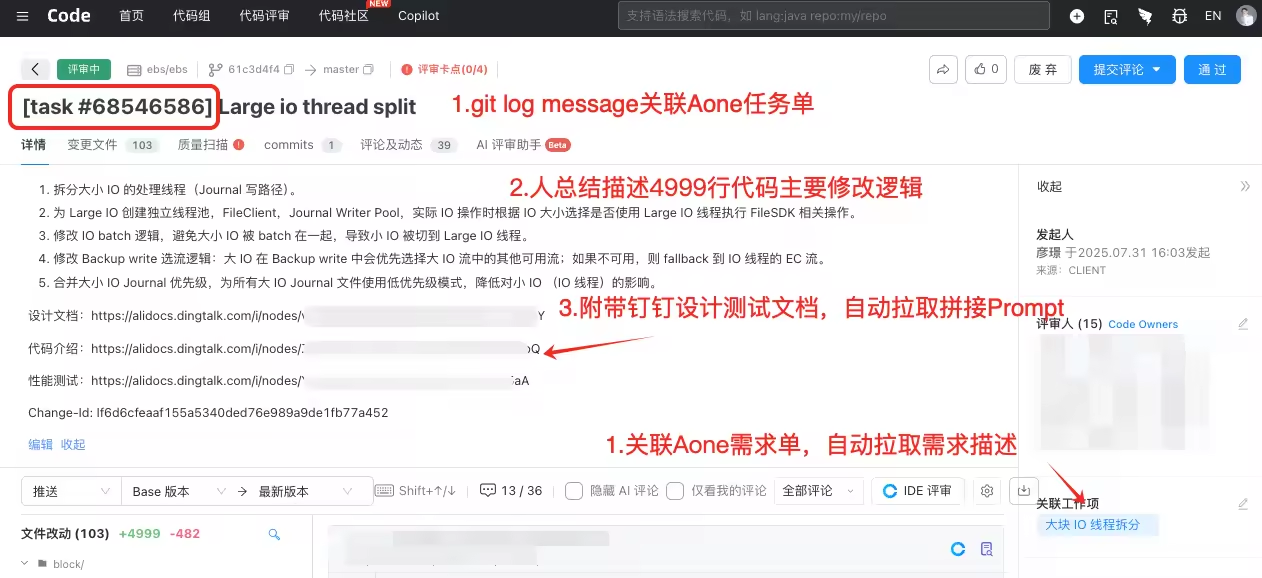
仓库所有历史代码提交均关联Aone需求/缺陷单,如下图所示:
评审效果
LLM 代码评审的用户交互反馈功能开发中,暂无全量的采纳率、误报率等量化数据,初见效果:
1.累计使用次数:已在EBS仓库代码门禁触发上千次LLM代码评审,日均 1W 次模型调用、5 亿 Token 使用量;
2.评审效率:10 分钟/次:从PR创建到收到AI首轮评论,大幅缩短了代码评审的等待周期;
3.发现问题多样性:不限于编码错误,多次识别出深层次的并发问题、边界场景和资源泄漏等。
根据开发者用户反馈,LLM 代码逻辑解释总结能力很强,For Reviewer 大幅提到的代码理解效率;For Submitter 风险发现能力有待提升,褒贬不一,抽样选择了L/M/S/XS的PR,代码修改行数分别是5000行/1500行/300行/30行的评审质量对比,存在100%建议全部被Accept的情况,也存在100%建议被Ignore的情况,评审质量很大程度取决于Code Diff聚合程度和Git Log Message的质量,部分用户反馈如图: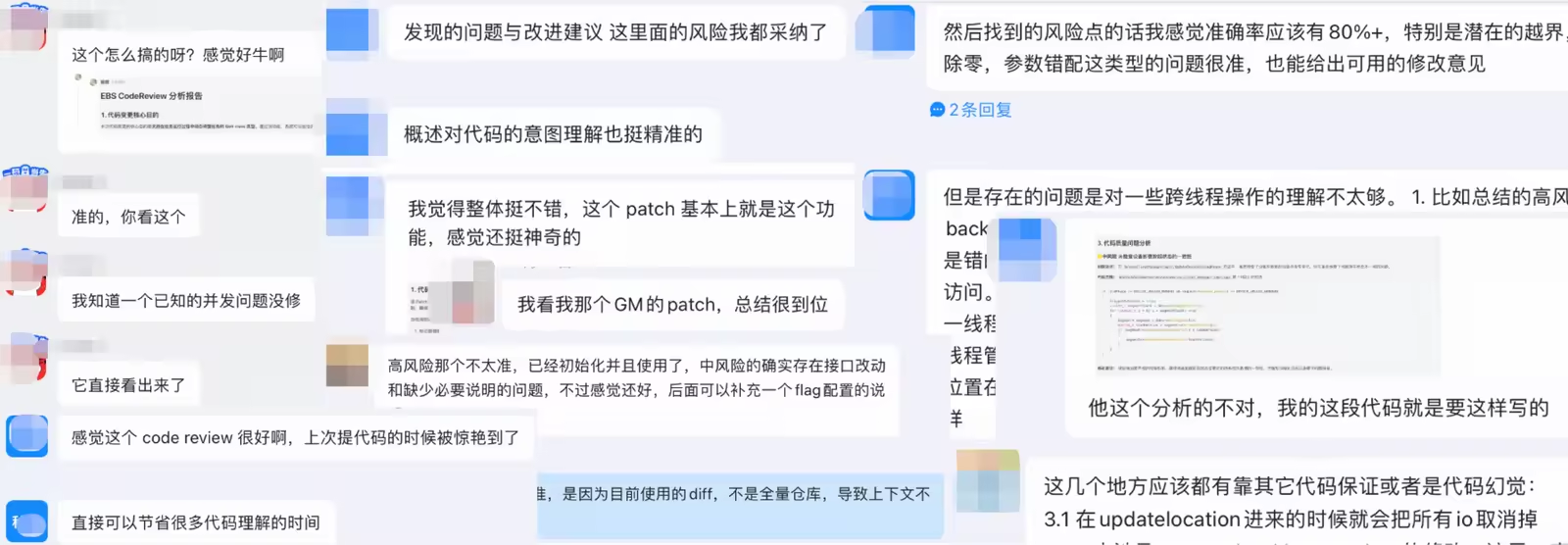
最佳实践:开发者和维护者协同机制
开发使用建议
结合前文所述,Prompt上下文引导融合了Patch特有的“在线上下文”和系统通用“离线知识库”信息,实践验证,上下文和 Prompt 质量对输出影响很大,对于开发者而言,有如下建议:
| 建议 | 核心动作 |
| PR 精准描述 | 规范填写Git Commit Msg信息,关联Aone需求/缺陷单和钉钉设计/测试文档,修改Aone需求描述重新 git push 即更新 Prompt 重新生成评审结果。 |
| 保持原子化提交 | 一个PR一个改动,避免不相关改动在同一个PR,导致分散模型注意力,降低模型的质量; |
| 积极提交反馈 | 积极提交反馈(点击Accept/Reject 或 评论建议),每一次互动反馈都在驱动进化。 |
系统维护经验
在系统维护过程中,我们发现理论上的“最优”并不总是等于实践中的“有效”,分享一些尝试经验:

持续探索:AI 代码评审复用优化演进
复用场景
一次企业级安全要求 RAG+开源LLM代码评审探索,该方法具备高度的通用性和扩展性:
1.“LLM评审功能” 横向复用: 将当前AI Agent封装为标准化的原子能力,嵌入到代码门禁平台或作为IDE插件,让其他团队仅需维护自己的知识库即可“开箱即用”。
2.“RAG+开源LLM” 纵向拓展: 知识库不仅能服务于代码评审,亦可辅助 Feature 测试设计、用例生成、故障模式分析等,实现“一次沉淀,多次复用”。
优化方向
维护经验表明,提升AI评审质量并非依赖单一技巧,而是必须建立系统化的调优流程。核心在于构建“反馈-评估-优化”闭环,依托固定评测集和量化指标,系统性排查知识库质量、向量切片策略、RAG检索精度、Prompt引导方式及LLM能力边界等关键因素。
实践中,“模型+Prompt+知识库+参数”的任意组合变化均可能引发结果波动,组合爆炸导致验证成本显著上升。要将AI评审打造成真正有效助力开发提效的工具,需持续投入人力进行工程打磨,开展充分的回归测试与A/B验证,确保迭代可衡量、效果可预期。


















 728
728

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









