



基于深度多模态网络的季节不变性语义分割
摘要
语义场景理解是自动驾驶车辆在非公路环境中运行的一项重要能力。尽管相机是最常用于语义分类的常用传感器,但在光照、天气和季节变化导致训练集和测试集之间存在显著差异时,仅使用图像的方法性能可能会下降。另一方面,来自主动传感器(如激光雷达)的三维信息对这些因素具有相对不变性,这促使我们研究其是否可用于提升此场景下的性能。本文提出了一种新颖的多模态卷积神经网络(CNN)架构,该架构包含二维和三维双流,并通过将三维特征投影到图像空间进行融合,以实现鲁棒的像素级语义分割。我们在一个新的非铺装路面地形分类基准上评估了所提出的方法,相对于仅使用图像的基线方法,在与导航相关的语义类别的平均交并比(IoU)上提升了25%。
1 引言
对于在非结构化非铺装环境中运行的自动驾驶车辆而言,理解环境中的语义类别(如“小路”、“草地”或“岩石”)有助于实现安全且有目的的导航。鲁棒的场景理解至关重要,因为错误信息可能导致碰撞或其他事故。

场景理解的一个重要步骤是语义图像分割,它在像素级别对图像进行分类。近年来,深度卷积神经网络(CNN)在语义分割任务中达到了最先进的水平,超越了传统的计算机视觉算法。然而,我们观察到,当训练集和测试集之间存在由光照、天气和季节引起显著的外观变化时,卷积神经网络的分割性能会下降(图1)。一种直接的解决方案是增加包含相关变化因素的训练数据,但这种方法成本较高,因为收集数据并为训练标注真实标签需要大量人力。
相反,解决这一问题的有效方法是使用一种额外的、互补的传感器,例如激光雷达。相机在视野范围和数据密度方面具有优势,而激光雷达则在应对由光照、天气和季节引起的外观变化不变性方面具有优势。因此,结合使用相机获取的图像和激光雷达采集的三维点云,为卷积神经网络利用这两种模态的互补特性创造了机会。然而,以下问题仍未解决:(1)如何联合使用这两种传感器进行图像分割;(2)每种模态中的哪些特征对鲁棒分割有用。
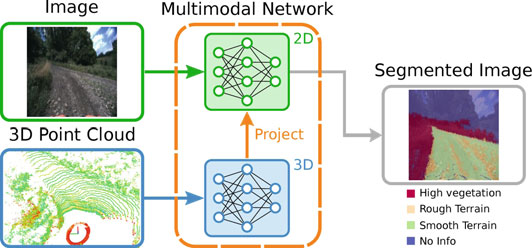
在本研究中,我们提出了一种基于深度多模态网络的解决方案,该方案联合使用图像和三维点云数据,并输出分割图像。我们的主要贡献是一个包含投影模块的框架,该框架不仅使多模态网络能够学习二维和三维特征表示,还能在训练过程中有效地融合不同域的特征,从而实现鲁棒的图像分割。为了评估所提方法对外观变化的鲁棒性,我们构建了一个标注数据集,该数据集包含从一辆改装过的全地形车在非公路环境中于冬季和夏季两个不同季节采集的图像和激光雷达数据。实验表明,我们提出的方法具有很高的准确性,且相较于仅图像基线方法,在应对此类变化时表现出显著更强的鲁棒性。
2 相关工作
一般来说,语义场景理解的相关方法大致可分为两类,具体取决于输入模态的数量:单模态(例如仅图像输入)或多模态(例如图像和三维点云)。
2.1 单模态图像方法
RGB图像的语义分割是一个活跃的研究课题。许多成功的方法使用图模型,例如马尔可夫随机场或条件随机场(MRFs或CRFs)。这些方法通常首先将图像过分割为超像素,并从单个区域及其相邻区域中提取手工特征。图模型利用提取的特征来确保相邻区域标签的一致性。
与依赖人工设计特征不同,基于CNN的方法通过从原始数据中学习强大的特征表示,实现了最先进的分割性能。不同CNN方法之间的主要区别在于网络架构。Shelhamer等人引入了跳跃连接层,用于优化所谓反卷积层生成的分割结果。Badrinarayanan等人提出了一种带有非池化层的编码器‐解码器架构。这些架构采用了相对较慢的VGG架构。为了降低计算成本——这对机器人学而言是一个重要目标——Paszke等人应用了瓶颈结构,受启发,构建了一个参数数量少但精度与先前模型相当的高效网络。我们网络的基于图像的部分正是建立在这些架构基础之上的。
2.2 多模态方法
研究人员已使用图像和三维点云进行场景理解。在我们工作的主要灵感之一中,穆尼奥斯等人[14]为每种模态训练两个分类器级联,并通过堆叠方法在两个分类器之间分层传播信息。纽曼等人[15]描述了一个框架,该框架通过贝叶斯决策规则和支持向量机对单个激光雷达数据进行分类,并使用多数共识为图像中的超像素标注标签。Cadena和Košecká [16]提出了一种 CRF框架,用于强制执行从两个传感器覆盖范围中提取的独立特征集之间的空间一致性。Alvis 等人 [17]从图像中提取外观特征用于CRF,并从三维点云中获取超像素集合的全局约束。
还有一些基于卷积神经网络的方法使用RGB和深度(RGBD)表示,通常来自立体视觉或结构光传感器。库普里耶等人 [4] 将来自RGB‐D的多尺度卷积神经网络的特征图与从RGB图像获得的超像素相结合以进行图像分割。Gupta等人[5]从颜色和编码深度中提取卷积神经网络特征,以在室内进行目标检测。他们证明,基于目标检测结果计算得到的增强特征可提升[18]的分割性能。
一种近期相关的RGBD方法是Valada等人[6]提出的方法。该方法首先使用相同的二维卷积神经网络学习分割不同模态的输入,然后通过将每个CNN输出的特征图相加来融合不同模态的特征,并在后续进行处理(后期融合卷积方法)。尽管他们的融合发生在每个CNN模型的输出端(后期融合),但我们考虑从另一模态分层引入特征,因为CNN学习到的多层级抽象已被证明具有优势[7]。
与使用RGBD的方法相比,我们方法的一个关键区别在于,我们不仅学习二维特征,还学习三维特征。三维特征包含有用的空间信息,而这些信息在二维中很难学习。
3 提出的方法
我们的目标是预测四种语义类别(“高大植被”、“粗糙地形”、“平滑地形”、“无信息”),以实现非道路环境中的安全导航。相机是用于场景理解的最常用传感器,因其具有远距离视野(例如可远距离检测障碍物)和密集数据的优势。然而,当训练和测试图像集之间因光照、天气和季节变化而存在显著差异时,基于图像的卷积神经网络的性能可能会下降。另一方面,来自激光雷达的3D信息相对于这些因素具有较强的不变性。我们额外使用三维点云数据,以帮助卷积神经网络学习对外观变化更具鲁棒性的特征集。
我们的深度多模态网络(图2)联合使用来自相机的图像和来自激光雷达的三维点云,并输出分割图像。该框架包括一个从图像中学习二维特征表示的图像网络、一个从点云中学习三维特征表示的点云网络,以及一个将学习到的三维特征传播到图像网络的投影模块。三维特征的传播使得图像网络能够在训练过程中结合二维/三维特征,并学习到更鲁棒的特征集。在本节中,我们将详细描述该多模态网络的这些主要组件。
 )
)
3.1 图像网络
图像网络的目标是从图像中学习二维特征表示 θ 2D,以最小化分类交叉熵损失。网络应具备良好的分割性能,而且还具有快速的预测时间和较少的参数数量,便于嵌入实时自主系统。在本研究中,我们基于ENet设计网络[3],该网络已证明其性能与现有模型(例如SegNet[2])相似,但推理时间更短,参数数量更少。ENet包含编码器部分(初始阶段、第1‐3阶段)和解码器部分(第4‐5阶段),由初始、下采样、上采样和瓶颈模块组成,如图3所示。瓶颈模块具有单个主分支和一个带有卷积滤波器的分离分支的架构。我们在每个阶段多次使用该模块,使网络更深的同时降低了对网络退化问题的敏感性[13]。ENet架构如图 5(上方网络)所示。有关该网络的更多细节,请参阅[3]。
3.2 点云网络
与图像网络类似,点云网络学习3D特征表示 θ3D以最小化3D模态中的分类交叉熵损失。在实验中,我们使用图像网络(第3.1节),但通过使用3D卷积层、最大池化层和上采样层将其应用于3D。
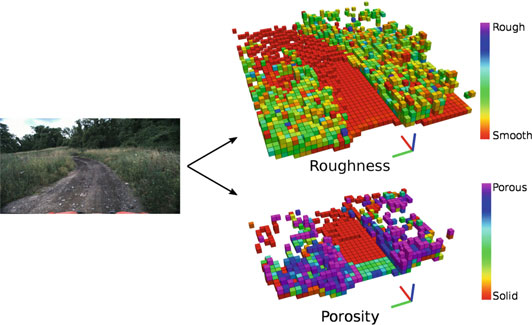
我们希望预测高大植被和地形的语义类别,因为这些在非道路区域中经常出现。直观上,我们期望地形区域比高大植被区域更平滑;而包含植被的空间相比地形区域更具孔隙性。Maturana 和 Scherer [19]利用这一假设,使用孔隙度作为输入训练一个3D卷积神经网络来预测着陆区检测。类似地,我们提供粗糙度和孔隙度特征(图4)作为网络的输入,而不是原始点云。我们的假设是,这些特征相比原始点云能更好地表示所需的语义类别。
对于每个由索引 (i,j, k) 标识的网格体素,我们通过计算体素[20]内每个点到拟合平面的平均残差来得到粗糙度特征R 3D i ,j,k:
$$
R^{3D}
{i,j,k} = \frac{1}{N} \sum
{n=1}^{N} \frac{|Ax_n + By_n + Cz_n + D|}{\sqrt{A^2 + B^2 + C^2}}
$$
其中,N 表示每个体素内点的数量,x、y、z表示每个点的位置,A、B、C、D 表示体素内 N 个点的拟合平面参数(即Ax+ By+ Cy+ D= 0)。对于空体素(即无点的情况),我们分配一个恒定的负粗糙度值 −0.1。
对于孔隙度特征 $P^{3D} {i,j,k}$,我们使用三维光线追踪 [21] 来获取每个网格体素的命中次数和通过次数。然后,我们通过更新激光雷达测量序列${z_t}^T {t=1}$[19]的Beta参数$\alpha^t_{i,j,k}$和$\beta^t_{i,j,k}$来建模孔隙度:
$$
\alpha^t_{i,j,k} = \alpha^{t-1}_{i,j,k} + z_t
$$
$$
\beta^t_{i,j,k} = \beta^{t-1}_{i,j,k} + (1 - z_t)
$$
$$
P^{3D}
{i,j,k} = \frac{\alpha^t
{i,j,k}}{\alpha^t_{i,j,k} + \beta^t_{i,j,k}}
$$
其中$\alpha^0_{i,j,k} = \beta^0_{i,j,k} = 1$对所有$(i,j, k)$成立,$z_t = 1$表示命中,$z_t = 0$表示通过。
 )
)
3.3 投影模块
投影模块首先将点云网络学习到的三维特征投影到二维图像平面上。然后如图3所示,接着使用瓶颈模块,以便将更好的特征表示传播到图像网络。
关于投影,我们将每个体素相对于激光雷达的质心位置(x, y,z)通过针孔相机模型投影到图像平面(u,v)上:
$$
s \begin{bmatrix} u \ v \ 1 \end{bmatrix} = \begin{bmatrix} f_x & 0 & c_x \ 0 & f_y & c_y \ 0 & 0 & 1 \end{bmatrix} [R | t] \begin{bmatrix} x \ y \ z \ 1 \end{bmatrix}
$$
其中 $f_x$、$f_y$、$c_x$、$c_y$ 是相机的内参,R和t分别是相机到 3×3激光雷达的 3×1旋转矩阵和平移矩阵。我们从原始点云维度中每个体素大小处采样(x, y,z)(例如,如图16× 48× 40所示5)。这是为了解决由于三维最大池化层减少了点云维度而导致投影变得稀疏的问题。我们应用z缓冲技术来处理多个激光雷达点投影到同一像素位置的情况。然后,使用最近邻插值对投影图像平面进行下采样,以匹配投影模块将要合并到的图像网络层的尺寸(第3.4节)。
我们考虑相对于激光雷达的固定的三维点云体积(第4.3节)。因此,体素位置及其在图像中的相应投影位置如果点云和图像的维度相同(例如第1阶段和第4阶段的投影),则网络中的维度保持不变。在实际操作中,我们预先计算体素位置及其对应的像素索引,并在网络内部使用这些索引。
3.4 多模态网络
图5总结了我们的多模态网络架构:点云网络从粗糙度和孔隙度点云中学习三维特征,投影模块将三维特征传播到图像网络,图像网络则将三维特征与从图像中提取的二维特征进行融合。我们将投影模块应用于初始阶段和第1至第5阶段的输出,因为卷积神经网络学习到的多层次特征是有益的 [7]。

4 结果
我们通过一系列实验来评估我们的方法。这些实验分析了我们的框架在光照、天气和季节变化引起的外观变化情况下,鲁棒地分割图像的能力。
4.1 数据集
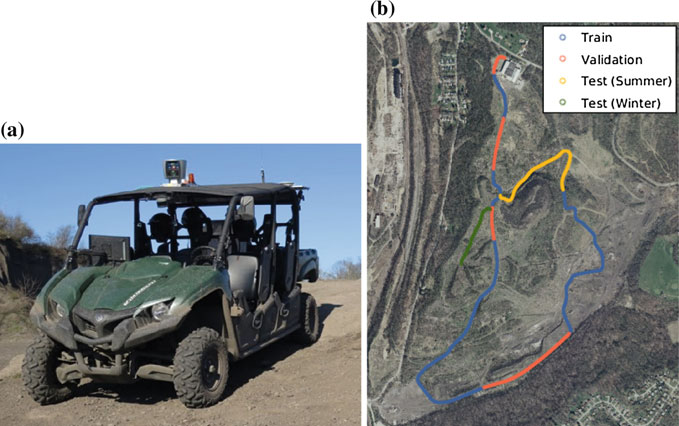
我们使用一辆改装的全地形车(图6a)进行数据采集,车上安装了相机和激光雷达HDL‐64E。为了获得具有较大外观变化的数据集,我们在两个不同日期进行了数据采集:2016年7月的夏季晴天(24次会话)和2017年1月的冬季阴天(2次会话)。由于采集的冬季数据量明显较少,不足以训练我们的多模态网络,因此我们仅使用夏季数据进行训练。我们将数据集基于会话划分:训练(17个夏季会话)、验证(4个夏季会话)、夏季测试(3个夏季会话)和冬季测试数据集(2个冬季会话)。对于第4.4节中的K折交叉验证,我们固定测试数据集,但对训练/验证会话进行随机打乱。其中一次K折交叉验证的数据分布如图6b所示。需要注意的是,训练、验证和测试数据集之间没有重叠。在各个K折中,训练数据平均包含7.2k对图像和点云,验证数据平均包含1.7k对图像和点云。夏季测试数据有1.3k对,冬季测试数据有0.6k对。
我们的真实语义标签包含4个类别:“高大植被”、“粗糙地形”、“平滑地形”和“无信息”。为了有效标注真实标签并最小化人为误差,我们首先通过随时间拼接点云构建一个配准点云(图7a)。然后我们在点云空间中手动标注配准点云中的地形与高植被类别(图7b)。我们使用公式1单独标注另一片点云,区分粗糙地形和平滑地形(图7c)。我们将两个标注的点云合并为一个包含三个类别的点云(图7d)。为了获得图像标签,我们将最终标注的点云投影到图像平面。我们将没有点的体素以及没有激光雷达点投影的像素视为无信息类。

4.2 网络架构
我们将我们的方法(Ours‐Proj)与基线方法进行了性能比较。第一个基线方法(模式法)根据训练数据集中标签的像素级众数对每个像素进行分类。由于非道路区域通常具有中间为小路、两侧为植被的一般结构,该基线方法的表现显著优于随机猜测。第二个基线方法SegNet是一种流行的编码器‐解码器图像分割网络 [2]。第三个基线方法Ours‐Image是我们的多模态网络中的图像网络,不包含点云网络和投影模块。最后一个基线方法(Ours‐RGBRP)与Ours‐Image相同,但其网络输入为5个通道(RGB、粗糙度、孔隙度),通过将点云网络的输入投影到图像平面上,并将其视为类似于颜色通道的额外通道。Ours‐RGBRP基线用于比较学习和传播三维特征相对于学习二维特征的有效性。
我们还探索了在不同位置设置投影模块的我们的‐投影方案。我们尝试了每个阶段使用一个投影模块、编码器投影(初始阶段和第1‐3阶段)以及解码器投影(第4‐5阶段)。
4.3 训练细节
所有输入和标签图像都被调整为 224 × 224像素。关于激光雷达,我们有一个固定的点云体积: −3.0到0.6米(z轴),3.0–17.4米(x轴),以及 −6.0到6.0 米(y轴),其中坐标轴对应于图4中的定义。体素大小为0.3米,因此输入和标签点云的维度为 12 × 48× 40(z, x, y轴)。投影模块中的内参和外参已进行离线校准。为了减少训练我们的‐投影方法所需的GPU内存,我们首先单独训练点云网络。然后移除反卷积以及点云网络中的softmax层,通过投影模块与图像网络连接,并在固定点云网络权重的情况下训练图像网络和投影模块。除了SegNet外,所有学习方法均基于Theano。对于SegNet[2],我们使用其公开的代码。我们从头开始训练所有学习方法。我们使用验证数据来确定测试时的权重。
4.4 实验结果
我们在表1和2中报告了每类交并比(IoU)和平均精确率‐召回率(PR)的定量性能。这些数值对应于K折交叉验证的均值和标准差,其中K= 5。
得益于非公路环境的通用结构,模式法在夏季和冬季均表现良好。然而,由于粗糙地形类相对于其他类别数量较少,因此不存在该类别的像素级众数。对于夏季场景,单模态网络(SegNet 和 我们的图像方法)与多模态网络(我们的 RGBRP方法 和 我们的‐投影)之间的性能相当。但在冬季场景中,多模态网络优于单模态网络。例如,与 SegNet 相比,我们的‐投影方法在与导航相关的语义类别(即除无信息类外的语义类别)的平均交并比(IoU)上提升了25%。在 我们的‐投影 与 我们的 RGBRP 方法之间,我们的‐投影 在 IoU 和 PR 上表现更优。特别是,我们的‐投影 对平滑地形类的预测比其他基线方法更为准确。结果表明,三维特征的学习与传播有助于网络学习到更鲁棒的特征表示。定性结果(图9)支持了我们的定量结果。定性结果的视频可在以下网址找到: http://frc.ri.cmu.edu/~dk683/fsr17/fsr17.mp4。
| Table 1 Quantitative results on summer test (mean and standard deviation) | ||||||
|---|---|---|---|---|---|---|
| Vege. | Rough | Smooth | No Info | Average PR | Average PR | |
| Mode | 0.513 | 0.000 | 0.508 | 0.806 | 0.572 | 0.611 |
| (0.041) | (0.000) | (0.015) | (0.009) | (0.006) | (0.010) | |
| SegNet | 0.816 | 0.182 | 0.670 | 0.828 | 0.741 | 0.767 |
| (0.008) | (0.007) | (0.019) | (0.010) | (0.003) | (0.008) | |
| Ours-Image | 0.814 | 0.183 | 0.702 | 0.837 | 0.742 | 0.767 |
| (0.007) | (0.008) | (0.059) | (0.003) | (0.004) | (0.008) | |
| Ours-RGBRP | 0.833 | 0.181 | 0.648 | 0.858 | 0.747 | 0.774 |
| (0.008) | (0.019) | (0.104) | (0.011) | (0.007) | (0.017) | |
| Ours-Proj | 0.839 | 0.179 | 0.655 | 0.864 | 0.747 | 0.772 |
| (0.005) | (0.014) | (0.072) | (0.003) | (0.006) | (0.015) |
| Table 2 Quantitative results on winter test (mean and standard deviation) | ||||||
|---|---|---|---|---|---|---|
| Vege. | Rough | Smooth | No Info | Average PR | Average PR | |
| Mode | 0.453 | 0.000 | 0.712 | 0.855 | 0.589 | 0.609 |
| (0.010) | (0.000) | (0.012) | (0.003) | (0.002) | (0.004) | |
| SegNet | 0.474 | 0.027 | 0.660 | 0.784 | 0.605 | 0.630 |
| (0.067) | (0.002) | (0.109) | (0.059) | (0.032) | (0.031) | |
| Ours-Image | 0.498 | 0.017 | 0.595 | 0.862 | 0.623 | 0.622 |
| (0.018) | (0.004) | (0.120) | (0.009) | (0.008) | (0.020) | |
| Ours-RGBRP | 0.582 | 0.036 | 0.692 | 0.881 | 0.678 | 0.689 |
| (0.035) | (0.008) | (0.107) | (0.002) | (0.010) | (0.022) | |
| Ours-Proj | 0.620 | 0.040 | 0.790 | 0.875 | 0.688 | 0.705 |
| (0.012) | (0.005) | (0.061) | (0.002) | (0.003) | (0.010) |
冬季的粗糙地形类的交并比得分较小,这是由于冬季标签中该类别的样本量较少。我们注意到,多模态方法在预测无信息类时可能具有优势,因为该类别的真实标签是基于激光雷达投影生成的。然而,多模态网络在与导航相关的类别上仍然表现出更优的结果。
对于在不同位置配置投影模块的我们的‐投影方法,实验结果表明,采用编码器投影(初始阶段和第1‐3阶段)的选项取得了最佳的分割性能(与图5中描述的完整投影结果相似)。对于单个投影模块,早期融合(第1或第2阶段)的效果优于晚期融合(第4或第5阶段)。
4.5 网络可视化
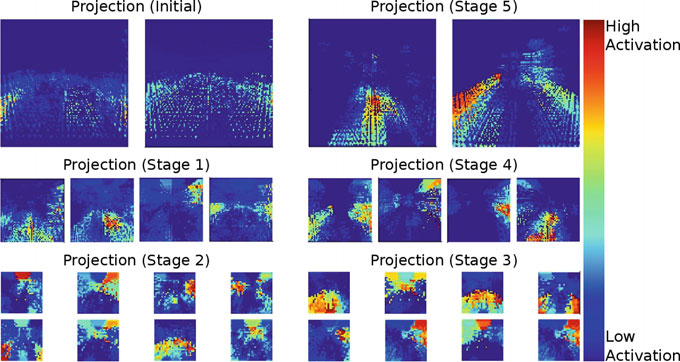
图8展示了每个投影模块的特征图。每个特征图表示滤波器在输入上关注的特定特征,因此有助于理解哪些三维特征被传播到图像网络以及它们为何能改善结果。
可视化结果显示,滤波器关注较低的水平面(例如地形)、两侧的垂直面(例如高大植被),或基于高度、宽度和深度的不同空间焦点组合。这些是有用的三维空间特征,在图像域中难以学习。因此,结合二维和三维特征的联合训练可以解释为什么我们的‐投影取得了最佳性能。
5 结论
我们提出了一种新颖的深度多模态网络,该网络由两个分支构成:一个二维卷积神经网络和一个3D卷积神经网络,通过将三维特征投影到图像空间来融合这两个分支,从而实现鲁棒的像素级语义分割。我们验证了该方法在应对由季节引起的严重外观变化挑战时仍能稳健分割的能力。未来的工作包括进一步提升预测速度以实现更快的预测时间,满足实时操作需求。


















 30
30

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









