




 本文探讨了MySQL中InnoDB引擎的多表查询效率,重点关注了子查询、联接查询(内连接、左连接)以及索引使用的影响。通过实验展示了不同查询策略的性能差异,并提供了优化建议,如选择合适的数据结构、避免临时表、合理设置索引等,以提高查询效率。
本文探讨了MySQL中InnoDB引擎的多表查询效率,重点关注了子查询、联接查询(内连接、左连接)以及索引使用的影响。通过实验展示了不同查询策略的性能差异,并提供了优化建议,如选择合适的数据结构、避免临时表、合理设置索引等,以提高查询效率。
Mysql多表查询效率的研究(一)
本文探究了mysql InnoDB引擎在多表查询的应用场景下,使用子表、内连接和左联接运行速度的差别,并且比较了索引使用与否对查询效率的影响。
第一部分简略地概括了索引、子表查询、联接查询的算法和数据结构;
第二部分探讨索引的使用策略和查询语句的优化并进行测试;
第三部分在前两部分的基础上进一步讨论mysql高性能的实现。
一、数据结构基础
- 索引原理
索引:INDEX,官方介绍索引是帮助MySQL高效获取数据的数据结构。笔者理解索引相当于一本书的目录,通过目录就知道要的资料在哪里,不用一页一页查阅找出需要的资料。
为什么需要索引(Why is it needed)?
当数据保存在磁盘类存储介质上时,它是作为数据块存放。这些数据块是被当作一个整体来访问的,这样可以保证操作的原子性。硬盘数据块存储结构类似于链表,都包含数据部分,以及一个指向下一个节点(或数据块)的指针,不需要连续存储。
记录集只能在某个关键字段上进行排序,所以如果需要在一个无序字段上进行搜索,就要执行一个线性搜索(Linear Search)的过程,平均需要访问N/2的数据块,N是表所占据的数据块数目。如果这个字段是一个非主键字段(也就是说,不包含唯一的访问入口),那么需要在N个数据块上搜索整个表格空间。
但是对于一个有序字段,可以运用二分查找(Binary Search),这样只要访问log2 (N)的数据块。这就是为什么性能能得到本质上的提高。但是,每种查找算法都只能应用于特定的数据结构之上,例如二分查找要求被检索数据有序,而二叉树查找只能应用于二叉查找树上,但是数据本身的组织结构不可能完全满足各种数据结构(例如,理论上不可能同时将两列都按顺序进行组织),所以,在数据之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种方式引用(指向)数据,这样就可以在这些数据结构上实现高级查找算法。这种数据结构,就是索引。
由于索引只是用来加速数据查询,那么显然对只是用来输出的字段建立索引会浪费磁盘空间以及发生插入、删除操作时的处理时间,所以这种情况下应该尽量避免。此外鉴于二分搜索的特性,数据的基数或独立性是很重要的。在基数为2的字段上建立索引,将把数据分割一半,而基数为1000则将返回大约1000条记录。低基数的二分查找效率将降低为一个线性排序,而且查询优化器可能会在基数小于记录数某个比例时(如30%)的情况下将避免使用索引而直接查询原表,所以这种情况下的索引浪费了空间。
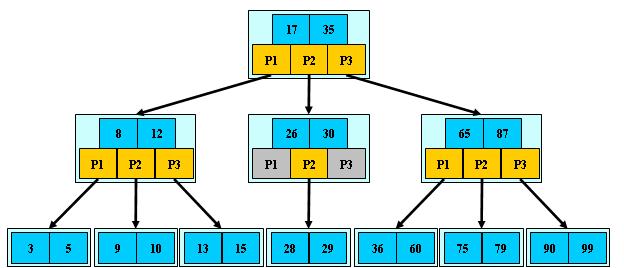
B-Tree:B-Tree是一种多路搜索树(并不是二叉的):
1.定义任意非叶子结点最多只有M个儿子;且M>2;
2.根结点的儿子数为[2, M];
3.除根结点以外的非叶子结点的儿子数为[M/2, M];
4.每个结点存放至少M/2-1(取上整)和至多M-1个关键字;(至少2个关键字)
5.非叶子结点的关键字个数=指向儿子的指针个数-1;
6.非叶子结点的关键字:K[1], K[2], …, K[M-1];且K[i] < K[i+1];
7.非叶子结点的指针:P[1], P[2], …, P[M];其中P[1]指向关键字小于K[1]的子树,P[M]指向关键字大于K[M-1]的子树,其它P[i]指向关键字属于(K[i-1], K[i])的子树;
8.所有叶子结点位于同一层;
如:(M=3)
B+Tree:B+树是B-树的变体,也是一种多路搜索树:
1.其定义基本与B-树同,除了:
2.非叶子结点的子树指针与关键字个数相同;
3.非叶子结点的子树指针P[i],指向关键字值属于[K[i], K[i+1])的子树(B-树是开区间);
5.为所有叶子结点增加一个链指针;
6.所有关键字都在叶子结点出现;
如:(M=3)
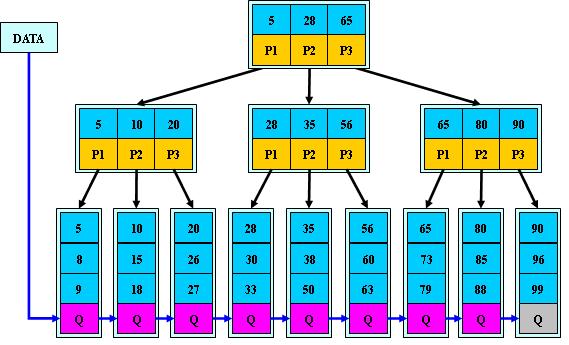
为什么选用B+Tree因为B+树不在节点中储存数据,那么一个磁盘块中可以储存更多的B+树非叶子节点,在对相同大小的数据建立索引时,B+树的度数更少,深度降低,那么查找时间也相应降低。同时B+树的双亲节点保存的是最小的数值,在SELECT时有效。最重要的是,磁盘读取数据时会进行一次**“预读”**,大小通常为页的整数倍。即使只需要读取一个字节,磁盘也会读取一页的数据(通常为4K)放入内存,内存与磁盘以页为单位交换数据。因为局部性原理认为,通常一个数据被用到,其附近的数据也会立马被用到。每次新建节点时,直接申请一个页的空间,这样就保证一个节点物理上也存储在一个页里,加之计算机存储分配都是按页对齐的,就实现了一个node只需一次I/O。并把B+tree中的m值设的非常大,就会让树的高度降低,有利于一次完全载入。
聚簇索引
所谓聚簇索引,就是指主索引文件和数据文件为同一份文件,聚簇索引主要用在Innodb存储引擎中。在该索引实现方式中B+Tree的叶子节点上的data就是数据本身,key为主键,如果是一般索引的话,data便会指向对应的主索引,如下图所示:
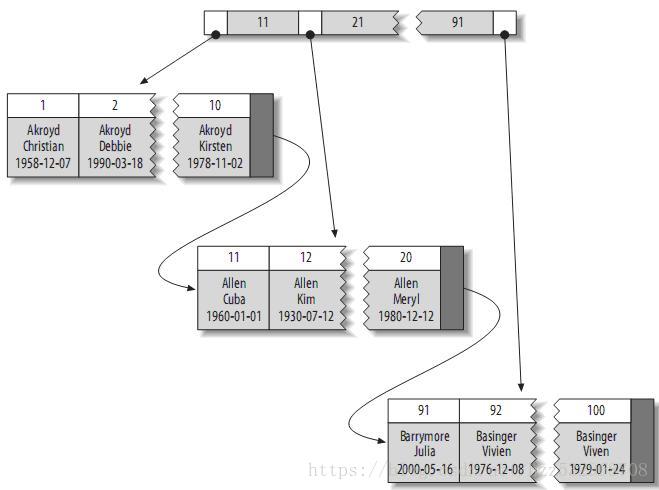
在B+Tree的每个叶子节点增加一个指向相邻叶子节点的指针,就形成了带有顺序访问指针的B+Tree。做这个优化的目的是为了提高区间访问的性能,例如图4中如果要查询key为从18到49的所有数据记录,当找到18后,只需顺着节点和指针顺序遍历就可以一次性访问到所有数据节点,极大提到了区间查询效率。
在InnoDB的表建立时会默认选择UNIQUE的Auto-Increase字段作为叶子节点的主索引。如果没有unique的字段,则MySQL自动为InnoDB表生成一个隐含字段作为主键,这个字段长度为6个字节,类型为长整形。并且一些经常会被修改、插入、删除的字段不适合作为聚簇索引的主索引
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 907
907





 到【灌水乐园】发言
到【灌水乐园】发言







