




安装Hadoop集群
文章目录
1.安装
我们先去官网下载最新版的hadoop下载

将他传到Master Linux操作系统中,确保已经安装JDK(甲骨文的)
本次传到/opt目录下
然后在/opt目录下新建hadoop目录
mkdir /opt/hadoop
将压缩包解压到hadoop目录
tar -zxvf /opt/hadoop-3.2.3.tar.gz -C /opt/hadoop
为了后期能执行hadoop、start-all.sh等等 命令 我们将hadoop目录中的sbin、bin目录添加到环境变量
将以下内容添加到/etc/profile
export HADOOP_HOME=/opt/hadoop/hadoop-3.2.3
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
然后更新
source /etc/profile
2.配置
然后接着配置集群,配置集群,需要配置HDFS和YARN
HDFS 守护进程是 NameNode、SecondaryNameNode 和 DataNode。YARN 守护进程是 ResourceManager、NodeManager 和 WebAppProxy。
集群的设计如下图:

三台虚拟机(Vmware):
| 主机名称 | IP地址 | 虚拟机状态 |
|---|---|---|
| Master | 192.168.1.30 | 存活 |
| Slave1 | 192.168.1.31 | 待克隆 |
| Slave2 | 192.168.1.32 | 待克隆 |
现在只有Master主机,我们配置好Master 在直接从Master克隆
1.配置HOSTS文件
我们将主机IP和名称映射对应上
1.修改主机名称
vi /etc/hostname
将localhost.localdomain删除 修改成Master ,从机Slave1 Slave2 我们之后克隆完后,也要重新修改下。
2.修改hosts映射
vi /etc/hosts
末尾添加(名称要和上面修改的名称对应上)
192.168.1.30 Master
192.168.1.31 Slave1
192.168.1.32 Slave2
2.配置Hadoop 文件
1.修改hadoop Java环境
在主目录/etc/hadoop/hadoop-env.sh
vi /opt/hadoop/hadoop-3.2.3/etc/hadoop/hadoop-env.sh
添加如下内容
export JAVA_HOME=自己的JAVA_HOME 如:/usr/env/java/jdk1.8.0_321
export HADOOP_HOME=自己的Hadoop主目录 如:/opt/hadoop/hadoop-3.2.3
2.配置 Hadoop 守护进程
1.core-site.xml
编辑文件core-site.xml
vi /opt/hadoop/hadoop-3.2.3/etc/hadoop/core-site.xml
在 之间添加配置
<property>
<name>fs.defaultFS</name>
<value>hdfs://Master:9000</value>
</property>
如下:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://Master:9000</value>
</property>
</configuration>
2.hdfs-site.xml
vi /opt/hadoop/hadoop-3.2.3/etc/hadoop/hdfs-site.xml
更多配置查看官方文档:hdfs-default.xml
<!-- 设置hdfs副本数量 -->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>Master:9870</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>Master:9868</value>
</property>
3.yarn-site.xml
vi /opt/hadoop/hadoop-3.2.3/etc/hadoop/yarn-site.xml
添加如下:(更多配置:yarn-default.xml)
<!-- 指定resourcemanager管理器地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>Master</value>
</property>
<!-- NodeManager上运行的附属服务。需配置成mapreduce_shuffle,才可运行MapReduce程序 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
4.mapred-site.xml
vi /opt/hadoop/hadoop-3.2.3/etc/hadoop/mapred-site.xml
添加如下:
<!-- 通知框架MR使用YARN -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
MapReduce JobHistory 服务器的配置
继续添加
<property>
<name>mapreduce.jobhistory.address</name>
<value>Master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>Master:19888</value>
</property>
3.配置从机地址
etc/hadoop/workers(2.x版本的叫做slaves)
配置这个也是为了能操作从机启动和执行(必须通过无密码 ssh,也就是要配置ssh免密登录)
vi /opt/hadoop/hadoop-3.2.3/etc/hadoop/workers
删除原来的,添加下面的
Master
Slave1
Slave2
3.克隆
将Master克隆出来两份,作Slave1和Slave2
为从机配置:
-
1.主机名称
vi /etc/hostname # 一个叫Slave1 另一个叫 Slave2 -
2.对应的ip地址
Slave1 对应 192.168.1.31 Slave2 对应 192.168.1.32
3.配置ssh免密登录
因为Master要去操作从机,要远程,所以要配置免密去登录从机。
我们在Master上执行
ssh Slave1
发现需要密码 才能进入。
1.配置免密登录
1.在Master上生成公钥
ssh-keygen -t rsa # 三下回车 生成公钥和私钥
2.将公钥复制到从机(第一次要输入密码就输入)
ssh-copy-id -i ~/id_rsa.pub root@Slave1
ssh-copy-id -i ~/id_rsa.pub root@Slave2
3.为自己连接自己 也配置以下
cat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys
4.然后我们测试连接是否需要密码
ssh Slave1
进入后使用 exit退出
4.关闭防火墙
如果不关闭,外部访问不了指定端口的服务,打不开web界面
执行关闭命令:
systemctl stop firewalld
执行开机禁用防火墙自启命令:
systemctl disable firewalld
5.启动集群
1.启动
1.格式化
启动集群之前需要格式化
在Master上执行
hdfs namenode -format
注意:找不到命令说明环境变量没配好
2.启动所有
我们可以在节点中一个一个指定需要运行哪些服务。
不过我们直接全部启动:执行脚本
start-all.sh
报错找不到也是因为环境变量没配置好
如需停止执行
stop-all.sh
启动完成后 使用jps命令查看服务
master:
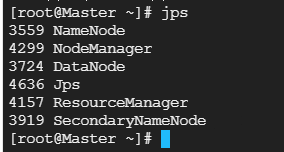
从机:
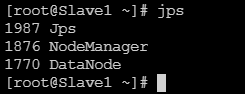
注意:使用start-all.sh没有启动JobHistoryServer服务,需要启动,在Master上执行
mapred --daemon start historyserver
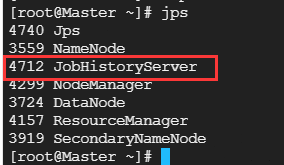
2.网页界面
一但 Hadoop 集群启动并运行,检查组件的 web-ui,如下所述:
| 守护进程 | 网页界面 | 笔记 |
|---|---|---|
| 名称节点 | http://nn_host:port/ | 默认 HTTP 端口为 9870。 |
| 资源管理器 | http://rm_host:port/ | 默认 HTTP 端口为 8088。 |
| MapReduce JobHistory 服务器 | http://jhs_host:port/ | 默认 HTTP 端口为 19888。 |
| :-------------------- | :----------------------- |
| 名称节点 | http://nn_host:port/ | 默认 HTTP 端口为 9870。 |
| 资源管理器 | http://rm_host:port/ | 默认 HTTP 端口为 8088。 |
| MapReduce JobHistory 服务器 | http://jhs_host:port/ | 默认 HTTP 端口为 19888。 |

















 2431
2431

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









