




欢迎关注我的公众号:

目前刚开始写一个月,一共写了18篇原创文章,文章目录如下:
istio防故障利器,你知道几个,istio新手不要读,太难!
不懂envoyfilter也敢说精通istio系列-http-rbac-不要只会用AuthorizationPolicy配置权限
不懂envoyfilter也敢说精通istio系列-02-http-corsFilter-不要只会vs
不懂envoyfilter也敢说精通istio系列-03-http-csrf filter-再也不用再代码里写csrf逻辑了
不懂envoyfilter也敢说精通istio系列http-jwt_authn-不要只会RequestAuthorization
不懂envoyfilter也敢说精通istio系列-05-fault-filter-故障注入不止是vs
不懂envoyfilter也敢说精通istio系列-06-http-match-配置路由不只是vs
不懂envoyfilter也敢说精通istio系列-07-负载均衡配置不止是dr
不懂envoyfilter也敢说精通istio系列-08-连接池和断路器
不懂envoyfilter也敢说精通istio系列-09-http-route filter
不懂envoyfilter也敢说精通istio系列-network filter-redis proxy
不懂envoyfilter也敢说精通istio系列-network filter-HttpConnectionManager
不懂envoyfilter也敢说精通istio系列-ratelimit-istio ratelimit完全手册
————————————————
vpa
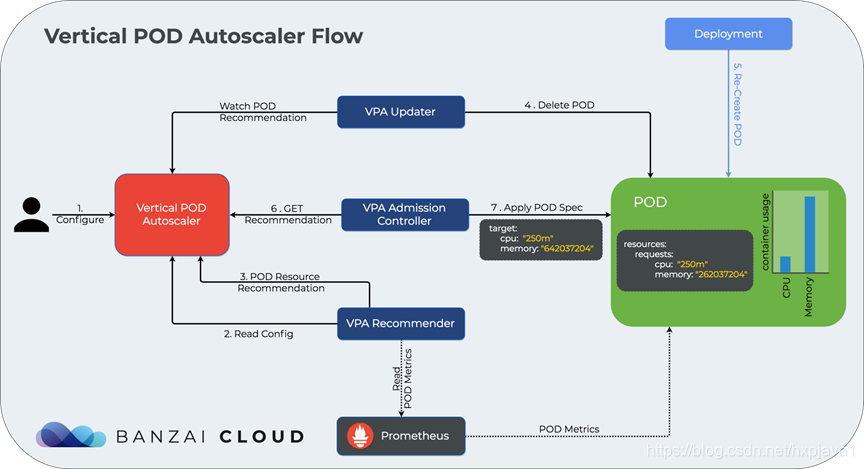
•VPA 全称 Vertical Pod Autoscaler,即垂直 Pod 自动扩缩容,可以根据容器资源使用情况自动设置 CPU 和 内存 的请求值,从而允许在节点上进行适当的调度,以便为每个 Pod 提供适当的资源。它既可以缩小过度请求资源的容器,也可以根据其使用情况随时提升资源不足的容量。
部署:
git clone GitHub - kubernetes/autoscaler: Autoscaling components for Kubernetes
cd vertical-pod-autoscaler/
./hack/vpa-up.sh
VPA 有以下四种更新策略:
•Initial:仅在 Pod 创建时修改资源请求,以后都不再修改。
•Auto:默认策略,在 Pod 创建时修改资源请求,并且在 Pod 更新时也会修改。
•Recreate:类似 Auto,在 Pod 的创建和更新时都会修改资源请求,不同的是,只要Pod 中的请求值与新的推荐值不同,VPA 都会驱逐该 Pod,然后使用新的推荐值重新启一个。因此,一般不使用该策略,而是使用 Auto,除非你真的需要保证请求值是最新的推荐值。
•Off:不改变 Pod 的资源请求,不过仍然会在 VPA 中设置资源的推荐值。
recommand:
[root@master01 recommend]# cat ./*
apiVersion: autoscaling.k8s.io/v1beta2
kind: VerticalPodAutoscaler
metadata:
name: my-rec-vpa
spec:
targetRef:
apiVersion: "apps/v1"
kind: Deployment
name: my-rec-deployment
updatePolicy:
updateMode: "Off"
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-rec-deployment
labels:
purpose: try-recommend
spec:
selector:
matchLabels:
purpose: try-recommend
replicas: 2
template:
metadata:
labels:
purpose: try-recommend
spec:
containers:
- name: my-rec-container
image: nginx:latestauto:
[root@master01 try-auto-requests]# cat ./*
apiVersion: autoscaling.k8s.io/v1beta2
kind: VerticalPodAutoscaler
metadata:
name: my-rec-vpa
spec:
targetRef:
apiVersion: "apps/v1"
kind: Deployment
name: my-deployment
updatePolicy:
updateMode: "Auto"
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-deployment
labels:
purpose: try-auto-requests
spec:
replicas: 2
selector:
matchLabels:
purpose: try-auto-requests
template:
metadata:
labels:
purpose: try-auto-requests
spec:
containers:
- name: my-container
image: alpine:latest
resources:
requests:
cpu: 100m
memory: 50Mi
command: ["/bin/sh"]
args: ["-c", "while true; do timeout 0.5s yes >/dev/null; sleep 0.5s; done"]VPA 主要包含三个组件:
•Admission Controller
•Recommender
•Updater


















 3508
3508

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











