



 本文深入探讨BatchNormalization技术,解析其如何解决Internal Covariate Shift问题,并加速深度网络训练过程。介绍了BatchNormalization的基本原理及其在特征缩放中的应用,同时讨论了该方法如何改善梯度消失现象并降低对参数初始化的要求。
本文深入探讨BatchNormalization技术,解析其如何解决Internal Covariate Shift问题,并加速深度网络训练过程。介绍了BatchNormalization的基本原理及其在特征缩放中的应用,同时讨论了该方法如何改善梯度消失现象并降低对参数初始化的要求。
这篇文章记录下Batch Normalization的一些内容:
论文:
Sergey Ioffe, Christian Szegedy, “Batch Normalization: AcceleratingDeep Network Training by Reducing Internal Covariate Shift”, 2015
我们首先从 feature scaling 说起:
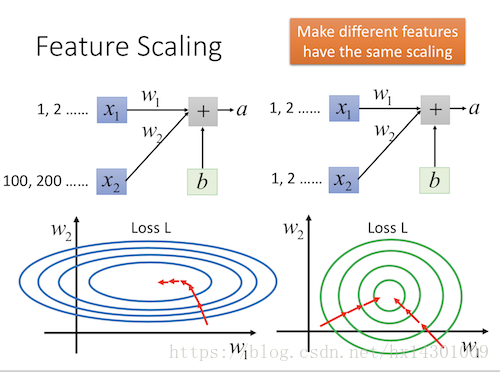
假设我们现在的两个输入X1,X2,他们的值很不平衡,X1都是1,2,3这样, X2都是100,200,300这样。
那么我们画出W1和W2的梯度图就会是上图左边的那样。可以看到,W1要变化很多才能达到W2的变化一点的程度,也就是在实际的train过程中,要想让W1和W2学习到同样的程度,我们需要给W1一个很大的learning rate,相应减少W2的learning rate。确实这个是可以做到的,但是并不容易。如果我们能有个方法,使得W1与W2的梯度图如右边的圆那样,岂不美滋滋?
有一个方法:
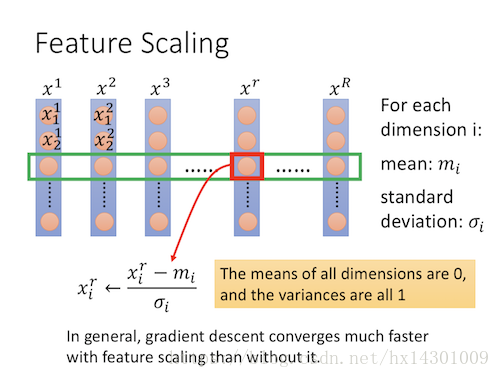
就是归一化,也就是给每个维度-均值 / 标准差。这样会使收敛速度快很多。对于输入的数据来说,我们在训练前做这一步会很有助于后面的学习。那么对于hidden layer呢?
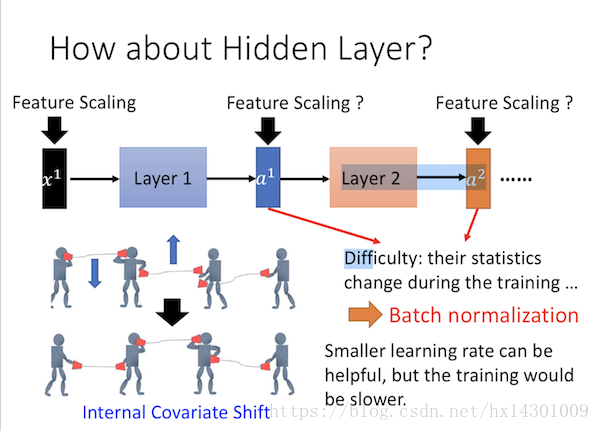
可以看到,随着参数的不断更新,layer1的输出也在不断的变化,这会使得后一层layer2接受的input会经常出现我们上面讲的梯度不平衡的问题。
在论文中给这个问题一个很高大上的词: Internal Covariate Shift
这个是什么意思呢?其实和之前讲的exposure bias的问题类似:
也就是有可能会导致,你后面学习的都是前面输出满足某个概率分布的条件下进行学习,现在前面学的差不多了,那么他的输出分布就会变化,导致你后面层以前学习的东西都白学了,又得按照前面层现在的输出条件重新开始学习。
从图中的小人来看,就是,左右的两个传声筒只有在一个高度才最好,现在你左右两边都在变化,如果不把握变化的幅度,会使得两个很难在同一高度。解决方法是吧learning rate调小,但是这样很难收敛的快。其实我们刚开始讲的Feature Scaling的作用就是为了解决 internal covariate shift的影响。因为如果我们队前一层的输出做feature scaling,那么下一层的输入分布就会相对固定,那么训练就会变得简单的多了。
因此,我们需要一个技术来固定每一层的output----------Batch Normalization
首先说下什么是Batch:
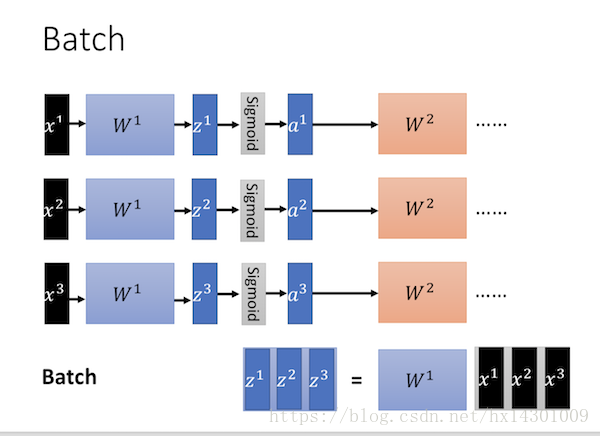
Batch就是每次训练使用一批数据来训练,它的原理是使用GPU加速批量并行运算矩阵化参数。且梯度更新方向更准
而batch normalization如下:
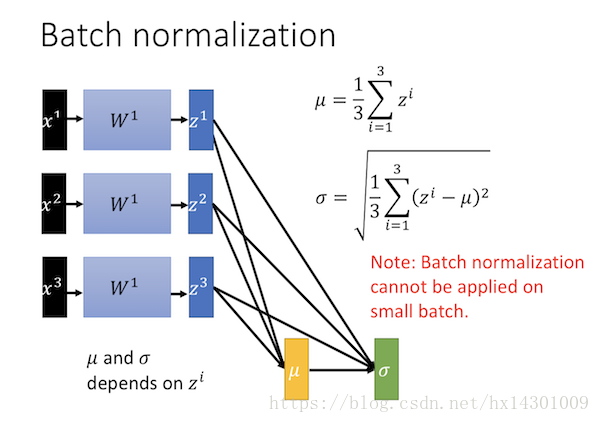
也就是对每个batch,进行归一化处理
BN不是凭空拍脑袋拍出来的好点子,它是有启发来源的:之前的研究表明如果在图像处理中对输入图像进行白化(Whiten)操作的话——所谓白化,就是对输入数据分布变换到0均值,单位方差的正态分布——那么神经网络会较快收敛,那么BN作者就开始推论了:图像是深度神经网络的输入层,做白化能加快收敛,那么其实对于深度网络来说,其中某个隐层的神经元是下一层的输入,意思是其实深度神经网络的每一个隐层都是输入层,不过是相对下一层来说而已,那么能不能对每个隐层都做白化呢?这就是启发BN产生的原初想法,而BN也确实就是这么做的,可以理解为对深层神经网络每个隐层神经元的激活值做简化版本的白化操作。
注意:
1. μ是依赖于输入的,σ是依赖于输入和μ的。
2. 我们希望μ和σ代表整个training set 全体的statistic 输出,但是在实际上,统计全体training set 的statistic 是否非常耗时也不切实际的,所以一般计算batch normalization时候是只会在一批训练数据中计算的,这意味着batch size 需要够大,如果batch size 太小的话,batch normalization 就会很差,因为无法从一个较小的batch里估测整个的 μ 和 σ 。
BN层通常使用在output到activation function之间因为:
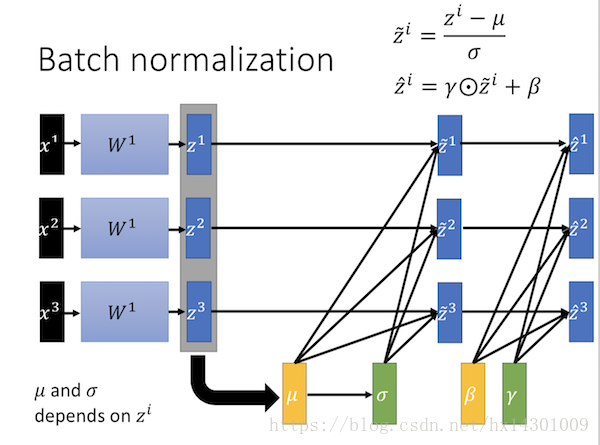
在归一化之后,又加了一个线性变化,这里的r和β的参数是由机器自己学的。
为什么这么做的原因,论文讲的也不清楚,摘抄点其他人的看法:
我们知道,BN其实就是把隐层神经元激活输入x=WU+B从变化不拘一格的正态分布通过BN操作拉回到了均值为0,方差为1的正态分布,即原始正态分布中心左移或者右移到以0为均值,拉伸或者缩减形态形成以1为方差的图形。什么意思?就是说经过BN后,目前大部分Activation的值落入非线性函数的线性区内,其对应的导数远离导数饱和区,这样来加速训练收敛过程。
但是很明显,看到这里,稍微了解神经网络的读者一般会提出一个疑问:如果都通过BN,那么不就跟把非线性函数替换成线性函数效果相同了?这意味着什么?我们知道,如果是多层的线性函数变换其实这个深层是没有意义的,因为多层线性网络跟一层线性网络是等价的。这意味着网络的表达能力下降了,这也意味着深度的意义就没有了。所以BN为了保证非线性的获得,对变换后的满足均值为0方差为1的x又进行了scale加上shift操作(y=scale*x+shift),每个神经元增加了两个参数scale和shift参数,这两个参数是通过训练学习到的,意思是通过scale和shift把这个值从标准正态分布左移或者由移一点并长胖一点或者变瘦一点,每个实例挪动的程度不一样,这样等价于非线性函数的值从正中心周围的线性区往非线性区动了动。核心思想应该是想找到一个线性和非线性的较好平衡点,既能享受非线性的较强表达能力的好处,又避免太靠非线性区两头使得网络收敛速度太慢。当然,这是我的理解,论文作者并未明确这样说。但是很明显这里的scale和shift操作是会有争议的,因为按照论文作者论文里写的理想状态,就会又通过scale和shift操作把变换后的x调整回未变换的状态,那不是饶了一圈又绕回去原始的“Internal Covariate Shift”问题里去了吗,感觉论文作者并未能够清楚地解释scale和shift操作的理论原因。
还有一种解释:
如果我们希望使用非 0 均值类型的激活函数,比如ReLU
有时候可能不希望你得到的output的mean 是0, variance 是1。可以给输出之前乘以γ 再加上 β,
γ和β可以当作网络的参数,他们也是可以跟着网络被一起学习出来的。
(γ和β)与(μ和σ)不一样的地方是,前者不受输入数据影响,是根据网络所需进行独立调整的。因此,这样的好处就是可以让网络具有学习非线性的效果,而不会被拘泥于线性的变化。
最后总结下BN的好处:

1. 解决了Internal Covariate Shift内部协方差移位的问题,这个问题会导致Learning Rate只能设的非常小。解决这个问题可以让Learning Rate设大一些,训练就会更快。
2. BN对防止Gradient Vanishing梯度弥散的问题是有帮助的。比如sigmoid 和tanh 如果输入很大或者很小,极有可能导致梯度弥散。但是加上BN后,就能保证输入在 0 附近,都是斜率比较大的线性区。
3. BN对于参数初始化的影响比较小
为什么呢?
假设现在把 输入的w1 都乘以 K 倍,当然他的输出Z 也会乘以 K 倍,这是BN中的 μ σ 都会乘上 K 倍,然而可以发现分子成了K 倍, 分母也乘上 K 倍,就是什么事也没有发生!!

















 2224
2224

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









