




 该篇博客介绍了如何利用XPath解析HTML以及Python的requests和lxml库来抓取并处理豆瓣Top250电影列表的数据,包括电影的标题、评分、评价人数、引言和详情页面URL。文章详细讲解了翻页处理、XPath选择器的使用,并给出了多种避免重复写入CSV表头的方法。
该篇博客介绍了如何利用XPath解析HTML以及Python的requests和lxml库来抓取并处理豆瓣Top250电影列表的数据,包括电影的标题、评分、评价人数、引言和详情页面URL。文章详细讲解了翻页处理、XPath选择器的使用,并给出了多种避免重复写入CSV表头的方法。
xpath复习
导入第三方库,向网页发起请求,获取html文件,把html文件加载成element对象加载给tree,然后就可以使用xpath方法,xpath是不确定的路径,通过字符串的形式把确定的路径传进去,就能够根据路径找到元素。
需求:
取出前三个li标签里文本值和class值,保存到csv文件里
from lxml import etree
import csv
# etree 里包含了xpath的一些功能
html = """
<html>
<head>
<title>测试</title>
</head>
<body>
<li class="item-0">first item</li>
<li class="item-1">second item</li>
<li class="item-inactive">third item</li>
<li class="item-1">fourth item</li>
<div>
<li class="item-0">fifth item</li>
</div>
<span>
<li class="item-0">sixth item</li>
<div>
<li class="item-0">eighth item</li>
</div>
</span>
</body>
</html>
"""
tree = etree.HTML(html)
# 需求:获取前三个li标签里的内容
# /表示层级关系,//表示子字节(子子孙孙的内容)
# text = tree.xpath('//li/text()') # ['first item', 'second item', 'third item', 'fourth item', 'fifth item', 'sixth item', 'eighth item']
# 以列表的形式显示li里的所有内容,可以用下标索引,左闭右开,获取属性不用text()
text = tree.xpath('//li/text()')[:3] # ['first item', 'second item', 'third item']
cs = tree.xpath('//li/@class')[:3] # ['item-0', 'item-1', 'item-inactive'],获取class的属性值
# 以 {'class':'item-0','text':'first item'},{'class':'item-1','text':'second item'}的形式存放
# print(text)
# print(cs)
lis_data = [] # 用来存放所有的数据
for c in cs:
d = {} # 定义一个字典,用来存放一条数据
# print(c) # item-0 item-1 item-inactive
# # print(cs.index(c)) # 0 1 2 打印的内容和索引值一一对应
# print(text[cs.index(c)])
# print('*'*50) # 循环成对对应取出文本和属性值。
d['class'] = c
d['text'] = text[cs.index(c)] # 循环添加key和value值到空字典中
# print(d)
lis_data.append(d) # 把获取的字典添加到空列表中
# print(lis_data)
# 保存数据
header = ('class', 'text')
with open('lis_data.csv', 'w', encoding='utf-8', newline="") as f:
write = csv.DictWriter(f, header)
write.writeheader()
write.writerows(lis_data)
案例分析:爬取某瓣Top250
目标
如何用xpath解析数据,熟悉xpath解析数据的方式。
通过观察目标网站了解爬取的需求,最终把数据保存到csv里。
需求
需要爬取的内容:标题 评分 评价人数 引言 详情页面url
页面分析
先复制一部分内容,看是否在网页源码中,点击鼠标右键,查看网页源码,通过下面的图片可以看到,我们需要的内容都在网页源码中,我们只需要对目标网站(https://movie.douban.com/top250)发起请求,在网页源码中提取数据就可以了,网站是静态加载出来了,属于服务器渲染。要得到250条数据还要有个翻页的处理,只需要爬取第一页的内容,再动态的更替start值,就可以得到其他页面的数据
目标url:https://movie.douban.com/top250
我们可以试着把第一页的url改为start=0,仍然可以访问第一页
翻页处理:
https://movie.douban.com/top250?start=0 第一页 025
https://movie.douban.com/top250?start=25 第二页 125
https://movie.douban.com/top250?start=50 第三页 225
https://movie.douban.com/top250?start=75 第四页 325
start = (page-1) * 25
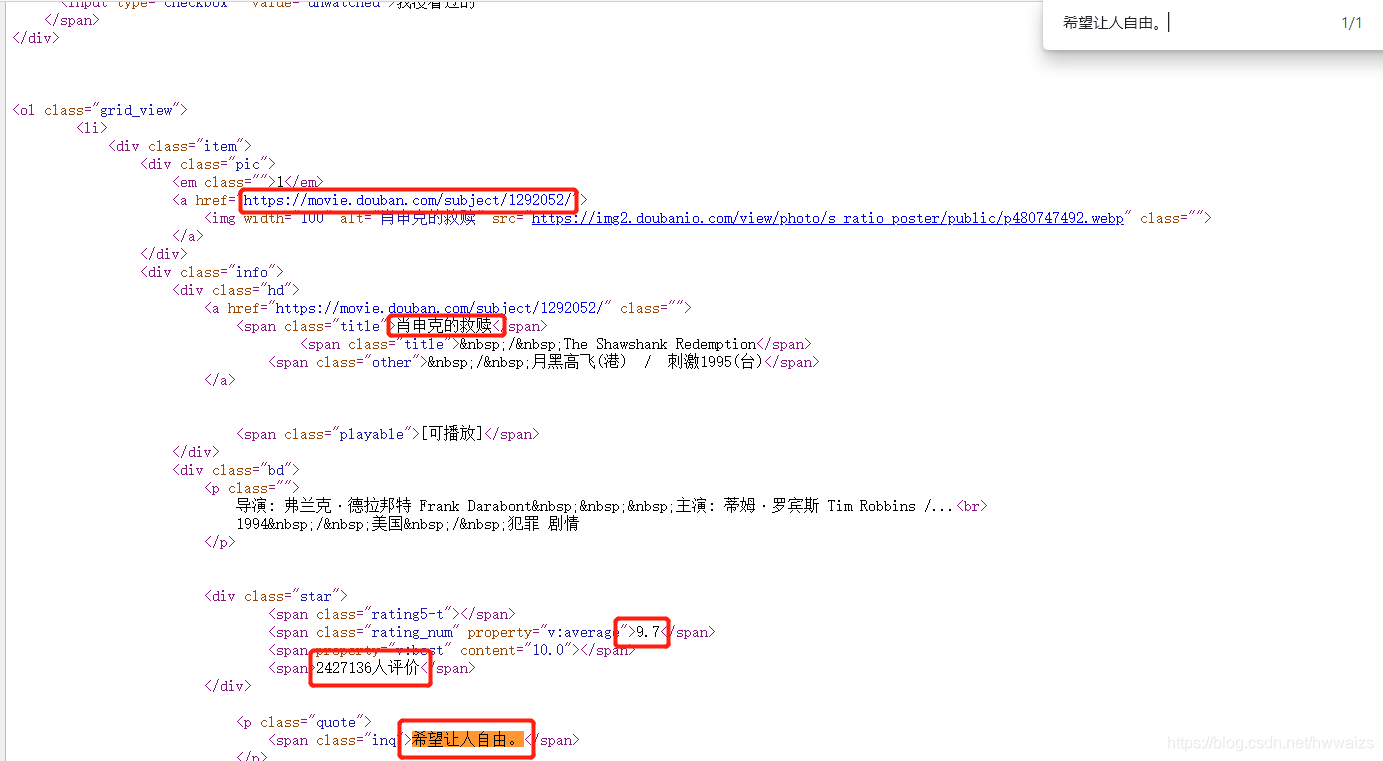
鼠标放到页面第一个电影“肖生克的救赎”名字处,点右键,检查,可以看到当光标放到肖生克的救赎处,对应标题处于高亮状态,放到<div class ="info"处整个电影的信息处于高亮,说明需要的信息都在此标签下面;光标放到<div class ="pic"处,图片高亮,可以在此次获取图片的信息;光标放到·<·li>处,第一个影片所有的信息都处于高亮状态,说明·<·li>标签里包含整个影片的信息;再往下看一共25个·<·li>标签,光标放到相应标签上分别对应本页面25个影片。element是最终加载出来的,我们还是要去网页源码中去看一下是否一致,比如复制’class=“info”'到网页源码中查看,可以看到有25个一样的标签。
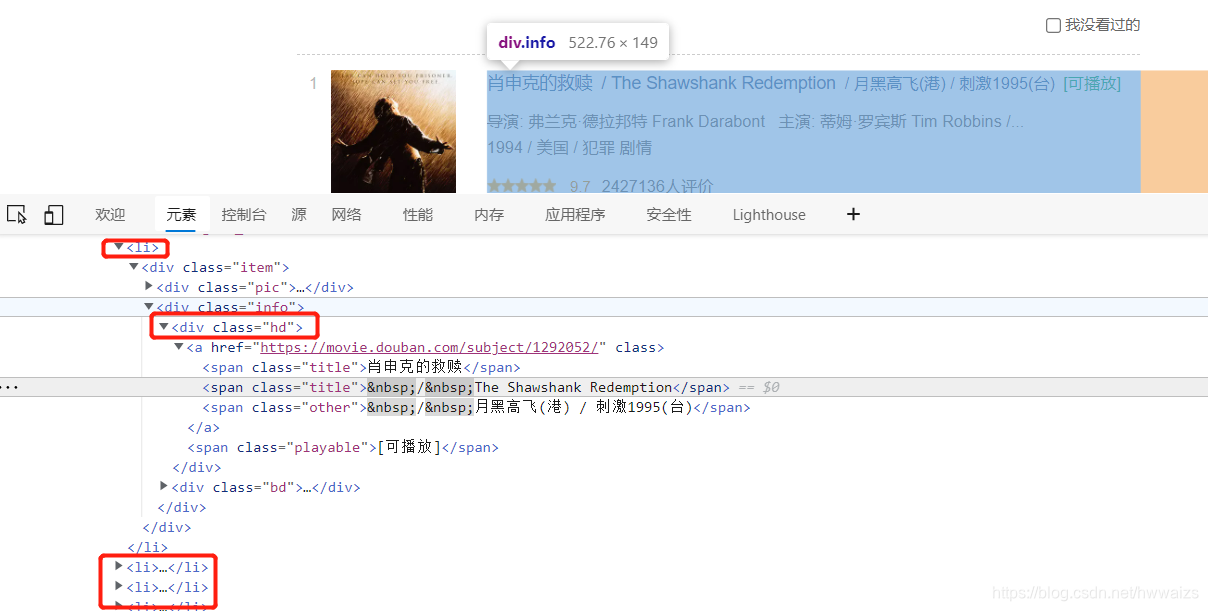
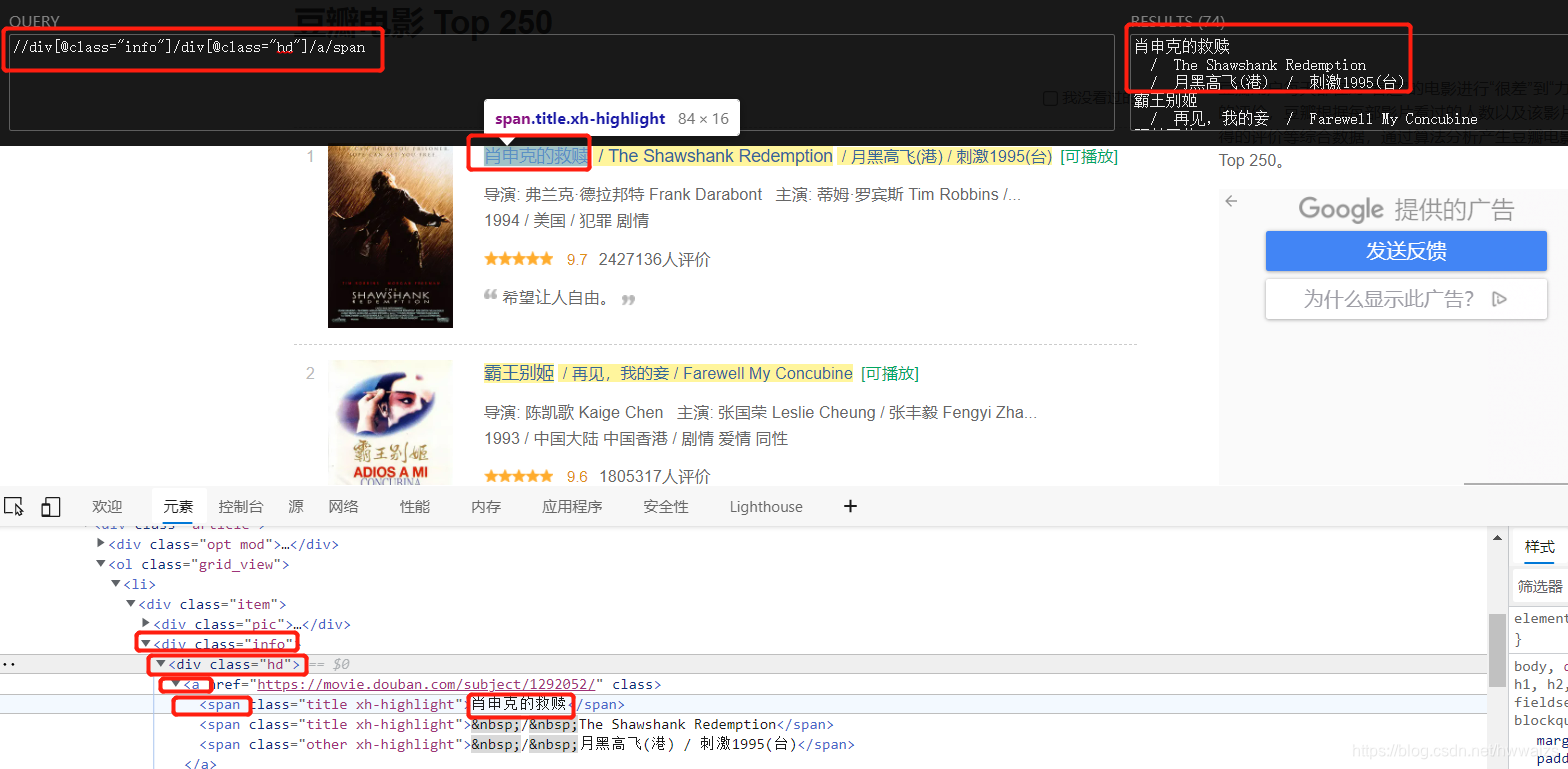
用快捷键 CTRL+shift+x 打开xpath helper,可以通过路径找到电影名字所在的位置
步骤
- 发请求,获网页源码,第一个函数
- 获取源码,解析数据,第二个函数。每一条数据都放在一个li标签的class="info"的div标签里面 再去class="info"的div标签中解析数据
- 保存数据,第三个函数。[{‘title’:‘xxx’, ‘score’:‘xxx’, ‘com_num’:‘xxx’, ‘quote’: ‘xxx’, ‘link_url’: ‘xxx’}, {xxx},{xxx}]
* 需要用到的工具:requests xpath csv
代码实现
import requests
from lxml import etree
import csv
# 发请求,获相应。传入发起请求的url
def get_url(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.107 Safari/537.36 Edg/92.0.902.62'
}
res = requests.get(url, headers=headers)
html = res.content.decode("utf-8")
# print(html)
return html
# 解析数据
def s_sourse(h):
# 将网页源码加载成element对象
tree = etree.HTML(h)
divs = tree.xpath('//div[@class="info"]')
# print(len(divs)) # 25个
last_data = [] # 存放所有数据的列表
for div in divs: # 用xpath获取到所有影片的info信息,再从每一个影片对象里去提取
d = {} # 用来存储一条数据的字典
# print(div)
# 用获取对象的相对路径获取每一个影片的信息,列表的下标从0开始,strip()去除字符串首尾的空白字符,
# 如果去除字符串中间的空白字符,可以用replace()
title = div.xpath('./div[@class="hd"]/a/span[@class="title"][1]/text()')[0].strip()
score = div.xpath('./div[@class="bd"]/div[@class="star"]/span[@class="rating_num"]/text()')[0].strip()
com_mun = div.xpath('./div[@class="bd"]/div[@class="star"]/span[4]/text()')[0].strip()
quote = div.xpath('./div[@class="bd"]/p/span/text()')
link_url = div.xpath('./div[@class="hd"]/a/@href')[0].strip()
# print(title, score, com_mun, quote, link_url)
# [0].strip() 取出列表的第一个元素,为了存储方便
# 以key,value值的形式添加到空字典中
d['title'] = title
d['score'] = score
d['com_mun'] = com_mun
if quote:
d['quote'] = quote[0].strip()
else:
d['quote'] = ""
d['link_url'] = link_url
# print(d)
# 把存放一条数据的字典插入列表
last_data.append(d)
# 每一个电影的数据存放在一个字典中,所有电影的数据存放在大列表中
# print(last_data)
return last_data
# 保存数据
def save_page(last_data, header):
# w是从头开始写, a是追加
with open('movie_data2.csv', 'a', encoding='utf-8', newline="") as f:
writ = csv.DictWriter(f, header)
# 写入表头不再传参
writ.writeheader()
# writerows 一次写入多行数据
writ.writerows(last_data)
# 主函数 调用函数
def main():
for m in range(10):
print(f'正在爬取第{m}页')
url = f'https://movie.douban.com/top250?start={m*25}'
# url = f'https://movie.douban.com/top250'
h = get_url(url)
# 表头可以用字典,列表,元组的形式传入
header = ('title', 'score', 'com_mun', 'quote', 'link_url')
lis = s_sourse(h)
save_page(lis, header)
if __name__ == '__main__':
main()
到此为止实现了翻页爬取数据,这里有一个坑,一定要注意:quote部分会出现空白,导致程序出现“IndexError: list index out of range”,在取quote的时候,“quote = div.xpath(’./div[@class=“bd”]/p/span/text()’)”,不能在后面[0].strip(),因为本身取得数据都是空白的,你在去除空白后,会使得到的结果有问题。这一部分正常取值,在加到字典里的时候,对quote进行判断,如果不为空,就返回“quote[0].strip()”,为空就直接返回“”,这样的话课避免出现错误。
得到结果后会发现,重复打印了表头,下面列举几种方法去除重复的表头。
方法一:只改动主函数
def main():
data_box = [] # 定义一个盒子放所有的数据
# 表头可以用字典,列表,元组的形式传入
header = ('title', 'score', 'com_mun', 'quote', 'link_url')
for m in range(10):
time.sleep(5)
print(f'正在爬取第{m}页')
url = f'https://movie.douban.com/top250?start={m * 25}'
# url = f'https://movie.douban.com/top250'
h = get_url(url)
data_box += s_sourse(h) # 把函数的返回值都装到盒子里
# print(data_box)
save_page(data_box, header)
方法一:在主函数中定义一个放所有数据的盒子,把获取的数据都放到盒子里,然后把盒子data_box作为参数传到save_page()函数里面,多行打印的时候就只打印数据了。测试的时候ip被封了,用了爬虫文件(三)里的讲的设置代理IP,请求头里加上了别人进入网页后的cookie才能正常访问,为了避免再次被封,所以加了个time时间的限制。
方法二:提前在主函数中写入表头,循环之后在save_page()里只写入数据
def save_page(last_data, header):
# w是从头开始写, a是追加
with open('movie_data3.csv', 'a', encoding='utf-8', newline="") as f:
writ = csv.DictWriter(f, header)
# writerows 一次写入多行数据
writ.writerows(last_data)
# 主函数 调用函数
def main():
header = ('title', 'score', 'com_mun', 'quote', 'link_url')
with open('movie_data3.csv', 'a', encoding='utf-8', newline="") as f:
writ = csv.DictWriter(f, header)
writ.writeheader()
for m in range(10):
time.sleep(5)
print(f'正在爬取第{m}页')
url = f'https://movie.douban.com/top250?start={m * 25}'
# url = f'https://movie.douban.com/top250'
h = get_url(url)
lis = s_sourse(h) # 把函数的返回值都装到盒子里
# print(data_box)
save_page(lis, header)
方法二:在主函数main中,先在循环体外面把文件的表头写进去,在写入数据save_page的时候,只写爬取到的数据。
方法三:不用写入函数,在主函数里先写入表头,在直接写入多行数据
def main():
header = ('title', 'score', 'com_mun', 'quote', 'link_url')
f = open('movie_data4.csv', 'a', encoding='utf-8', newline="")
writ = csv.DictWriter(f, header)
# 写入表头不再传参
writ.writeheader()
for m in range(10):
time.sleep(5)
print(f'正在爬取第{m}页')
url = f'https://movie.douban.com/top250?start={m*25}'
# url = f'https://movie.douban.com/top250'
h = get_url(url)
# 表头可以用字典,列表,元组的形式传入
lis = s_sourse(h)
# save_page(lis, header)
writ.writerows(lis)
方法三:在main函数中直接写入表头,数据解析函数s_sourse 得到的数据不再往写入函数save_page中传,直接存放到表中
方法四:在主函数中定义遍历的m为全局变量,在写入函数的时候对m进行判断,如果是第一次写入就写表头,否则不写表头
# 保存数据
def save_page(last_data, header):
# w是从头开始写, a是追加
with open('movie_data5.csv', 'a', encoding='utf-8', newline="") as f:
writ = csv.DictWriter(f, header)
if m == 0:
writ.writeheader()
# writerows 一次写入多行数据
writ.writerows(last_data)
# 主函数 调用函数
def main():
global m
for m in range(10):
time.sleep(5)
print(f'正在爬取第{m}页')
url = f'https://movie.douban.com/top250?start={m * 25}'
# url = f'https://movie.douban.com/top250'
header = ('title', 'score', 'com_mun', 'quote', 'link_url')
h = get_url(url)
lis = s_sourse(h) # 把函数的返回值都装到盒子里
# print(data_box)
save_page(lis, header)
方法四:巧妙的点是在main中把用于遍历的“m”定义为全局变量,这样可以把m用于其他函数,在save_page中就对m进行一下判断,如果为0,说明是写入的第一页,就写入表头,否则就不写入表头。


















 22万+
22万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









