






 本文详细介绍Kafka消息队列的搭建过程,包括JDK、Zookeeper和Kafka的安装配置,以及消息队列的基本概念如点对点模式和发布订阅模式。同时,深入解析Kafka的生产者和消费者工作原理,演示如何通过代码实现消息的生产和消费。
本文详细介绍Kafka消息队列的搭建过程,包括JDK、Zookeeper和Kafka的安装配置,以及消息队列的基本概念如点对点模式和发布订阅模式。同时,深入解析Kafka的生产者和消费者工作原理,演示如何通过代码实现消息的生产和消费。
消息队列基本概念
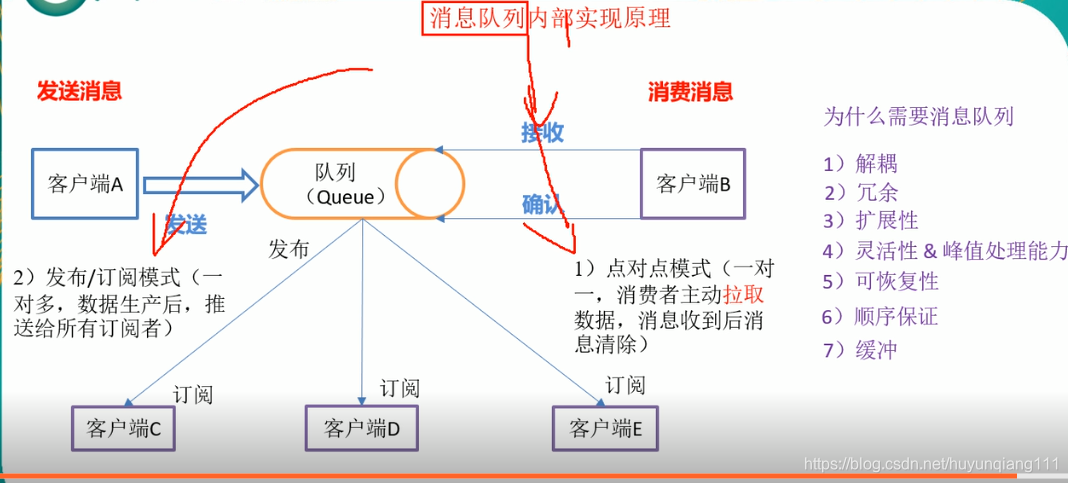
消息队列只要有发布订阅模式,和点对点模式,
点对点模式:是基于队列的消息生产者发送消息到队列,消息消费者从队列中拉去消息,却嗲是队列中有么有数据,客户端一直要进行监控。
发布订阅模式:定义了如何向一个内容节点发布和订阅消息,这个内容节点为主题(Topic),主题可以认为是消息发送的中介,消费者从主题中订阅消息。
1,安装jdk
--安装jdk
mkdir -p /user/java
mv jdk-8u131-linux-x64.tar.gz opt/soft
tar -zxvf jdk-8u131-linux-x64.tar.gz
vi /etc/profile
--配置环境变量
export JAVA_HOME=/usr/local/java/jdk1.8.0_162
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
//入下面命令让修改生效
source /etc/profile
//查看是否安装成功
java -verion2,安装Zookeeper
一般在root 用户权限下部署安装
//上传zookeeper安装包
mv zookeeper-3.4.12.tar.gz user/java
tar zxvf zookeeper-3.4.12.tar.gz
--配置环境变量
vi /etc/profile
export ZOOKEEPER_HOME=/usr/local/java/zookeeper-3.4.12
export PATH=$PATH:$ZOOKEEPER_HOME/bin
//入下面命令让修改生效
source /etc/profile
修改配置文件
huyunqiang@ubuntu:~/user/java/zookeeper-3.4.12/conf$ cp zoo_sample.cfg zoo.cfg
然后修改 zoo.cfg
# ZK 服务器心跳时间 (毫秒)
tickTime=2000
# 投票选举leader的初始化时间
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# 数据目录
dataDir=/tmp/zookeeper/data
#日志目录
dataLogDir=/tmp/zookeeper/log
#zk对外服务接口
clientPort=2181 创建存放日志和数据的根目录
mkdir -p /tmp/zookeeper/data
mkdir -p /tmp/zookeeper/data
在 /tmp/zookeepre/data 中创建一个myid文件 写入一个数值,主要存放服务器编号
启动和查看状态
bin/zkServer.sh start conf/zoo.cfg
bin/zkServer.sh status conf/zoo.cfg
单机部署以上已经完成,集群部署只需要修改一下配置文件
1,在三台机器的 /etc/hosts文件下添加 三台集群的IP地址与机器域名映射
192.168.234.6 node-3
192.168.234.7 node-4
192.168.1.103 node-3
2,然后在三台机器的zoo.cfg文件中添加一下配置
server.1=192.168.234.6:2888:3888
server.2=192.168.234.7:2888:3888
说明:
server.A=B:C:D
A: 服务器编号myid里面的唯一值
B: 服务器的IP 地址
C: 服务器与集群中的leade 服务器交换信息的端口。
D: 表示选举时服务器相互通信的端口
安装kfaka
1,解压安装kafka 配置环境变量和之前的jdk和zookeeper一样
2,修改kafka配置文件/conf/server.properties
#broker的编号,如果集群有多个broker 必须不同
broker.id=0
#broker对外提供的服务入口
listeners=PLAINTEXT://localhost:9092
#存放日志的文件地址
log.dirs=/tmp/kafka-logs
#kafka 所需要的集群地址,方便演示,假设kafka,zk 都安装在本机
zookeeper.connect=localhost:2181/kafka
--启动kafak
bin/kafka-server-start.sh config/server.properties
-- 测试生产消费者
创建回话
bin/kafka-topics.sh --create --bootstrap-server 192.100.2.44:9092 --replication-factor 2 --partitions 3 --topic alarmTopic查看topic是否创建成功
bin/kafka-topics.sh --list --bootstrap-server localhost:9092
展示更多的主题
bin/kafka-topics.sh --describe --bootstrap-server 192.100.2.44:9092 --topic alarmMessage
Topic
Topic:mySecondTopic PartitionCount:3 ReplicationFactor:2 Configs:
Topic: mySecondTopic Partition: 0 Leader: 2 Replicas: 2,1 Isr: 2,1
Topic: mySecondTopic Partition: 1 Leader: 0 Replicas: 0,2 Isr: 0,2
Topic: mySecondTopic Partition: 2 Leader: 1 Replicas: 1,0 Isr: 1,0
# 后面的 leader、replicas和ISR 涉及到 kafka 内核结构,我们后续单独开辟实验详细讲解,此时你只需要知道,这些参数保证了 kafka 集群的健壮性,保证消息不丢失,保证消息的高吞吐量。-- 通过kafka-console-producer.sh kafka-console-consumer.sh测试是否可以正常接收发送消息
--消息发送
bin/kafka-console-producer.sh --broker-list 192.168.234.3:9092 --topic topic-demo
--消息接收
bin/kafka-console-consumer.sh --bootstrap-server 192.168.234.3:9092 --topic topic-demo
遇到的问题
问题1:Kafka:Configured broker.id 2 doesn't match stored broker.id 0 in meta.properties.
网上搜查资料是说,log.dirs目录下的meta.properties中配置的broker.id和配置目录下的server.properties中的broker.id不一致了,解决问题的方法是将两者修改一致后再重启。
而当时为何会产生这个问题?
1、Kafka配置目录下文件server.properties中一个broker.id
# The id of the broker. This must be set to a unique integer for each broker.
broker.id=2
# A comma seperated list of directories under which to store log files
log.dirs=/tmp/kafka-logs另外还有一个属性log.dirs,这是kafka产生log目录,log目录 下有meta.properties文件,而meta.properties文件中也写有broker.id,这是在运行时产生的。
#Wed Nov 08 15:59:53 PST 2017
version=0
broker.id=2问题2:zookeep集群启动成功但是查看 zK的启动状态不成功主要是 上面提到的 myid么有设置唯一服务器标识
测试kafka消息队列 生产者,消费者
消费者通过轮询不断检测消息
public class ConsumerFastStart {
public static final String brokerList = "192.168.234.3:9092";
public static final String topic = "topic-demo";
/**
* 消费者隶属的消费组名称
*/
public static final String groupId = "group.demo";
public static void main(String[] args) {
Properties props = new Properties();
props.put("bootstrap.servers", brokerList);
props.put("group.id", groupId);
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
//创建客户端消费
KafkaConsumer<String,String> consumer = new KafkaConsumer<String, String>(props);
//订阅主题
consumer.subscribe(Collections.singletonList(topic));
/**
* Kafka中消息消费是不断轮询的过程,重复调用poll() 返回订阅主题(分区)上的一组消息
* poll() 有一个超时时间 timeout用来控制阻塞时间(在么有数据时发生阻塞)
*
*/
while (true){
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));
for(ConsumerRecord<String, String> record :records){
System.out.println("消息来了"+record.value());
}
}
}
}生产者 发送数据主要有三种模式
public class ProducerFastStart {
public static final String brokerList = "192.168.234.3:9092";
public static final String topic = "topic-demo";
public static void main(String[] args) {
Properties properties = new Properties();
//指定key 和 value 序列化 以数组的形式进行传递
properties.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
properties.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
//指定连接kafka集群所需的broker.id地址
properties.put("bootstrap.servers",brokerList);
//配置生产者客户端参数创建KafkaProducer是线程安全的 可以在多个线程中共享大哥KafkaProducer
KafkaProducer<String,String> producer = new KafkaProducer<String, String>(properties);
//构建所需要的参数
ProducerRecord<String,String> record = new ProducerRecord<>(topic,"hello,kafka+11");
/**
* 发送数组主要有三种形式
* 发后即忘(first-and-forget)producer.send :性能最好可靠性最差可能会丢失数据
* 同步(sync)producer.send(record).get() :通过调用get()来阻塞等待Kafka的响应知道消息发送成功
* 同步发送可靠性高要么发送成功要么发送失败,课捕获异常进行处理
* 异步(async)
*/
try {
producer.send(record).get();
}catch (Exception e){
e.printStackTrace();
}
}
}kafka概念名词解释
-
Broker :一台kafka服务器就是一个broker。一个集群由多个broker组成,一个broker可以容纳多个topic
-
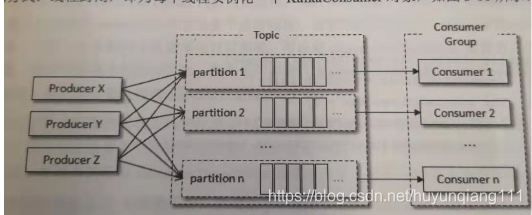
Partition:很多时候会把分区称为主题分区,同一主题下的不同分区的消息是不同的,一个非常大的topic可以分布到多个broker(即服务器)上,一个topic可以分为多个partition,每个partition是一个有序的队列。partition中的每条消息都会被分配一个有序的id(offset)。kafka只保证按一个partition中的顺序将消息发给consumer,不保证一个topic的整体(多个partition间)的顺序。
-
Offset:kafka的存储文件都是按照offset.kafka来命名,用offset做名字的好处是方便查找。例如你想找位于2049的位置,只要找到2048.kafka的文件即可。当然the first offset就是00000000000.kafka
kafka配置相关参数说明
listeners: 客户端连接broker的入口地址 listeners=PLAINTEXT://192.168.234.3:9092 如果有多个地址可用逗号分开,如果绑定127.0.0.1是无法对外提供服务。
broker.id:
消费者和消费组
每个消费者都有一个消费组。当消息发送主题后会被投递给订阅他的每个消费组中的一个消费者,是主动拉去消息

某个主题中有四个分区:有两个消费组A,B按Kafka的默认分配规则A 中的每个消费者有两个分区B 中的每个消费者有一个分区,两个互不影响。
发布消息
消费消息
kafka 中的消费是基于拉模式。消费的消息一般有两种: 推模式,和拉模式。推模式是服务端主动将消息推送给消费者,而拉模式是消费者主动向服务端发送请求拉取消息。
多线程实现
kafkfaProducer是线程安全的,然而KafkaConsumer是非线程安全的,但是并不意味着我们只能在单线程的环境中实现,如果生产者发送的速度大于消费者处理消息的速度,并且Kafka消息保留机制的作用可以通过多线程的方式来实现消息的消费提高整体消费。多线程实现方式有多种
第一种封闭线程,为每个线程实例化一个KafKaConsumer对象,
优点:
每个线程可以按顺序消费各个分区中的消息。
缺点
每个消费线程都要维护一个独立的TCP 连接,如果分区和和线程数很大,会造成不小的系统开销
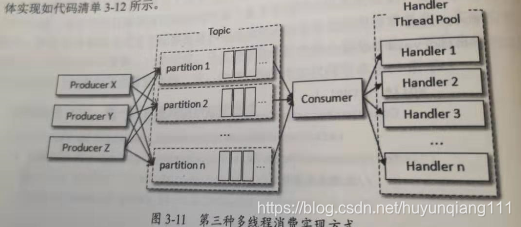
第二种实现方式通过线程池,横向扩展
public class ConsumerWorker implements Runnable {
private ConsumerRecord<String, String> consumerRecord;
public ConsumerWorker(ConsumerRecord record) {
this.consumerRecord = record;
}
private static Logger logger = Logger.getLogger(ConsumerWorker.class.getName());
public void run() {
// consumer接收消息后,这里可以写针对收到的消息的业务处理
logger.info("【Kafka】监听到kafka的TOPIC【" + consumerRecord.topic() + "】的消息");
logger.info("【Kafka】消息内容:" + consumerRecord.value());
}
public static void main(String[] args) throws Exception {
// 启动Kafka consumer监视
List<String> topics = new ArrayList<String>();
// 监听的消息通道
topics.add("topic-demo");
new ConsumerHandler(topics);
}
}public class ConsumerHandler {
static Logger logger = Logger.getLogger(ConsumerHandler.class.getName());
private final KafkaConsumer<String, String> consumer;
private ExecutorService executors;
public ConsumerHandler(List<String> topics) {
Properties props = new Properties();
props.put("bootstrap.servers", "192.168.234.3:9092");
props.put("group.id", "group.demo");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
consumer = new KafkaConsumer<String, String>(props);
consumer.subscribe(topics);
execute(2);
}
public void execute(int workerNum) {
executors = new ThreadPoolExecutor(workerNum, workerNum, 0L, TimeUnit.MILLISECONDS,
new ArrayBlockingQueue(1000), new ThreadPoolExecutor.CallerRunsPolicy());
Thread t = new Thread(new Runnable(){//启动一个子线程来监听kafka消息
public void run(){
while (true) {
ConsumerRecords<String, String> records = consumer.poll(200);
for (final ConsumerRecord record : records) {
logger.info("【Kafka】监听到kafka的TOPIC【" + record.topic() + "】的消息");
logger.info("【Kafka】消息内容:" + record.value());
executors.submit(new ConsumerWorker(record));
}
}
}});
t.start();
}
}说明
ConsumerWorker :类是用来处理消息的可以处理消息的业务逻辑
ConsumerHandler: 是一个消息线程,通过线程池的方式来调用ConsumerWorker 处理一批消息,
注意
ConsumerHandler 中的 ThreadPoolExecutor 设置最后一个参数CallerRunsPolicy()); 这样可以防止线程池的总体消费能力更不上poll()拉取能力而导致的异常发生。
优点:除了横向扩展能力,还可以减少TCP连接对系统资源消耗
缺点: 对消息的顺序处理比较困难

















 3915
3915

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









