



 本文介绍了Redis的事务特性,包括不支持回滚、MULTI、EXEC和WATCH命令的使用。接着讨论了Redis的过期键删除策略,如noeviction、allkeys-lru等。还详细阐述了慢查询的定义、慢查询日志的记录和分析方法。最后,简要讲解了HyperLogLog用于近似统计Distinct Value的原理。
本文介绍了Redis的事务特性,包括不支持回滚、MULTI、EXEC和WATCH命令的使用。接着讨论了Redis的过期键删除策略,如noeviction、allkeys-lru等。还详细阐述了慢查询的定义、慢查询日志的记录和分析方法。最后,简要讲解了HyperLogLog用于近似统计Distinct Value的原理。
事务
redis 的事务跟之前了解的事务不一样。它是将多个命令请求打包,然后按顺序、一次性地执行多个命令。事务执行期间,服务器不会中断事务而去执行其他客户端的命令。
注意,redis事务是不支持回滚的。
事务分三步:
事务开始 MULTI,打开事务标识
命令入队
事务提交执行 EXEC
事务还可以配合watch使用,watch 即乐观锁。事务开始前,注册监视某key,在exec 提交后,发现 watch 的key被修改了,则拒绝执行。
发布订阅
过期键删除
对于一些过期键的删除,有三种方式删除:
| 删除策略 | 描述 | 优点 | 缺点 |
| 定时删除 | 设置过期时间时,创建定时器;过期时间来临时,立即执行对键的删除 | 能保证尽快删除并释放内存 | 过期键较多时耗费CPU,影响服务器的响应时间和吞吐量; |
| 惰性删除 | 过期不管,每次获取键时,检查是否过期,如果过期则删除 | 取出键时才删除,不消耗CPU | 如果键长时间未访问,可能永远无法删除,即内存泄漏 |
| 定期删除 | 每隔一段时间,对数据库进行一次检查,选择性地删除里面的过期键。 | 算是前两种策略的折中 | 取决于定期删除策略 |
定期删除采用一定策略来选择key来删除:
noeviction:达到限制内存以后再存新数据会返回出错。
allkeys-lru:淘汰最近没使用的数据。
volatile-lru:在设置了过期值(expire)的数据里淘汰最近没使用的数据。
allkeys-random:随机淘汰数据。
volatile-random:在设置了过期值(expire)的数据里随机淘汰数据。
volatile-ttl:在设置了过期值(expire)的数据里淘汰快要过期的数据。
慢查询
一个客户端的命令执行需要以下几步:
1.客户端发送命令到服务器
2.服务器命令排队
3.服务器执行命令
4.服务器把结果返回给客户端
慢查询指的是 执行命令 这一步。当然其他步骤也有可能导致客户端感知变慢。
慢查询日志
当服务器执行命令超过某个设定阈值时,会记录这次执行的日志:发生时间、执行时长、命令信息等。这样我们可以定位慢查询。
获取慢查询日志
slowlog len可以获取慢查询日志的长度。
我们也可以取部分来分析,比如取5条
slowlog get 5慢查询日志有4个属性:
唯一标识ID
命令执行的时间戳,秒
命令执行时长
命令名和参数
清理
清理慢查询日志只需要执行:
slowlog reset慢查询阈值
在conf文件中设置:
slowlog-log-slower-than=1000单位微秒,执行超过这个时间的就会被记录。
1秒 = 1000 毫秒 = 1000 000 微秒
设置 为负数,则不记录日志;设置为0,会记录所有日志
slowlog-max-len该属性指定保存慢查询日志最大条数。超过则删除最早的那条
慢查询的信息存放在 redisServer 下
struct redisServer {
/ **
*/
list *slowlog; /* SLOWLOG list of commands */
long long slowlog_entry_id; /* SLOWLOG current entry ID */
long long slowlog_log_slower_than; /* SLOWLOG time limit (to get logged) */
unsigned long slowlog_max_len; /* SLOWLOG max number of items logged */
}从上边看 慢查询日志使用双端链表存放的。
/* Push a new entry into the slow log.
* This function will make sure to trim the slow log accordingly to the
* configured max length. */
void slowlogPushEntryIfNeeded(client *c, robj **argv, int argc, long long duration) {
if (server.slowlog_log_slower_than < 0) return; /* Slowlog disabled */
if (duration >= server.slowlog_log_slower_than)
listAddNodeHead(server.slowlog,
slowlogCreateEntry(c,argv,argc,duration));
/* Remove old entries if needed. */
while (listLength(server.slowlog) > server.slowlog_max_len)
listDelNode(server.slowlog,listLast(server.slowlog));
}添加是在头部添加,删除是在尾部进行。
Hyperloglog
HyperLogLog 一般被用来近似统计某一字段的Distinct Value,比如页面UV等。之所以是近似,它是利用概率的方式来统计的,标准误差为0.81%。
这里我们介绍下原理,具体理论见论文《HyperLogLog the analysis of a near-optimal cardinality estimation algorithm》
1.类似抛硬币,出现正反面的概率各位 1/2,如果连续出现 k 个 0,则为 k 个 1/2.
2.而我们的任意记录都能hash 成二进制。
3.因此,就可以最长连续 0 的个数,来估算元素的总个数(类似进行了多少次实验)。
4.当然这样预估存在误差,因此利用多个桶来估算,减小误差
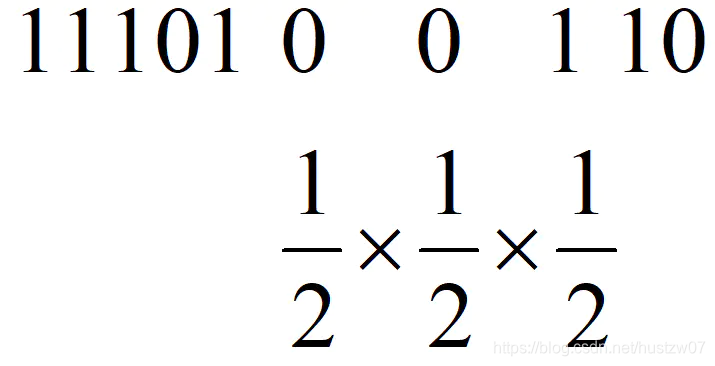
图片来自网络
先看下增加元素,对应命令
pfadd key value1
这个一个多参数命令,
存在key 则循环加入元素;否则新建 key 并分配空间,然后 循环加入元素。
其数据结构也分两种:桶、稀疏矩阵。后者在数据量较小时使用,节约内存。
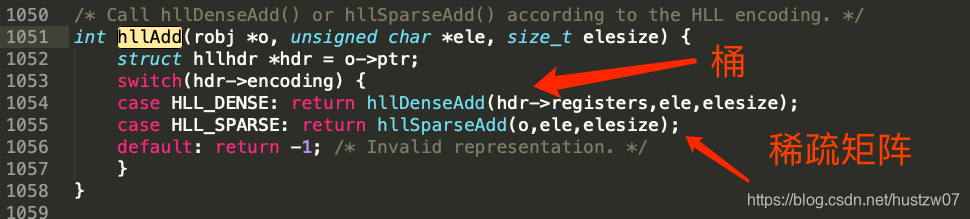
之后就是 hash 后计算前导0
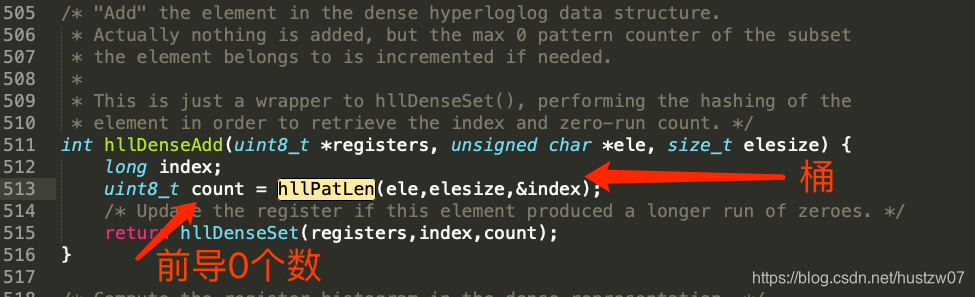
其hash 处理过程也简单:
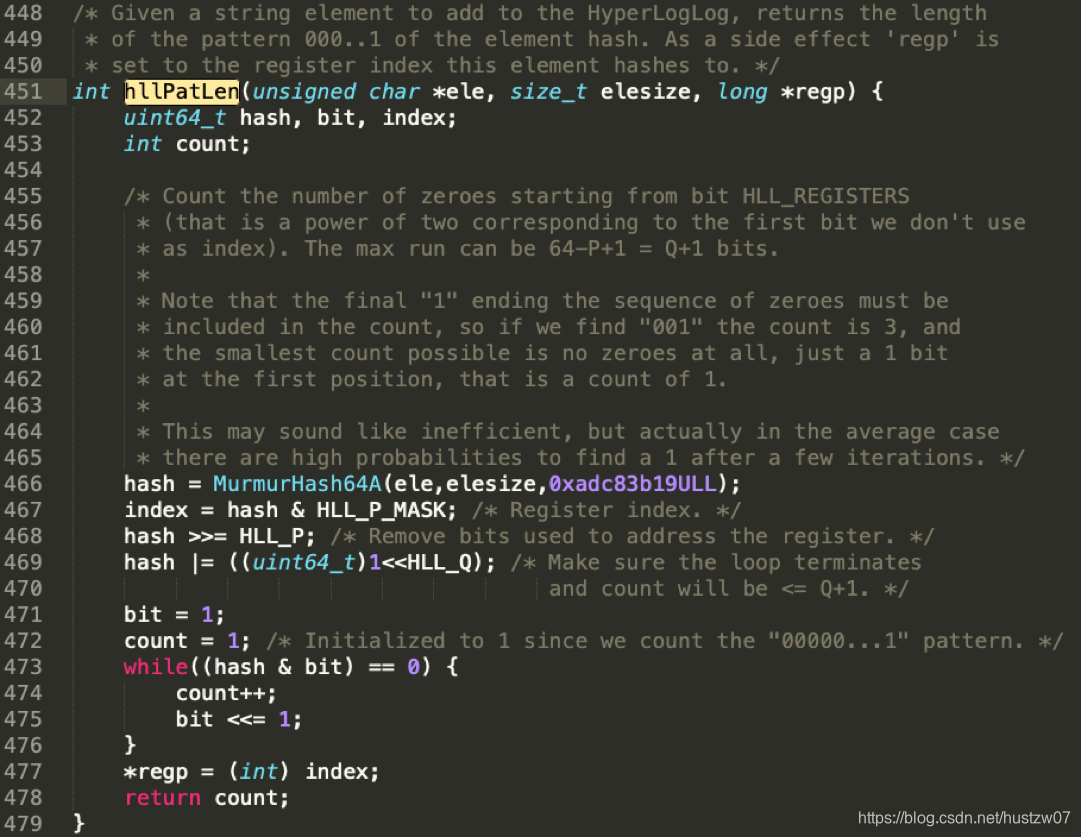
1.MurmurHash64A 成64位数字
2.hash & (1<<14)-1,即取最低14位算存哪个桶
3.hash的高48位,从右算0的个数。(注意 count 初始为1,说明多算了一个 1,即前导0串加1位1)
比如
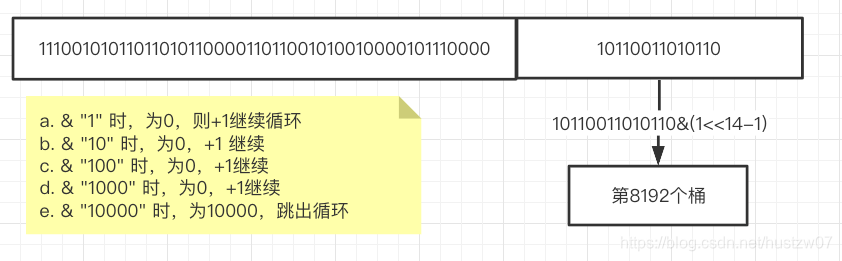
而桶的结构如下:
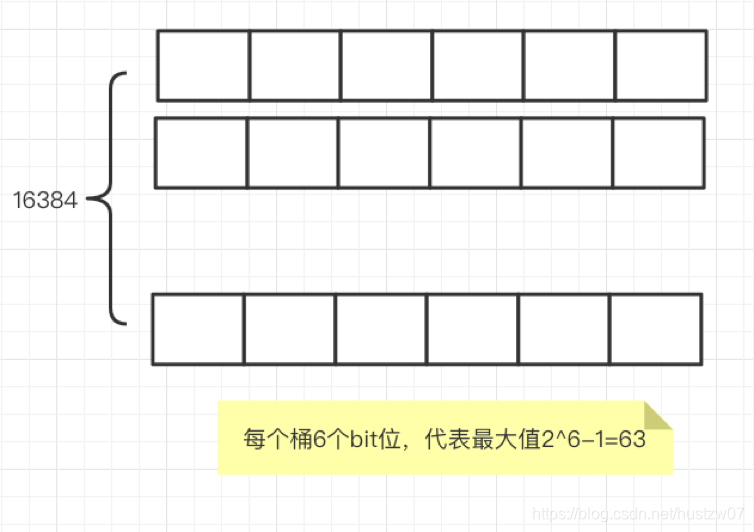
因为 hash的高位48位,最多只能48个0。因此6个 bit 位即可。
因此内存大小=16384 * 6 / 8 = 12 * 2^10 B = 12 KB

















 188
188

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









