




- 第1章 对大型语言模型的介绍
- 第2章 分词和嵌入
- 第3章 解析大型语言模型的内部机制
- 第4章 文本分类
- 第5章 文本聚类与主题建模
- 第6章 提示工程
- 第7章 高级文本生成技术与工具
- 第9章 多模态大语言模型
- 第10章 构建文本嵌入模型
- 第11章 面向分类任务的表示模型微调
- 第12章 微调生成模型
搜索是首批得到行业广泛采用的语言模型应用之一。在具有开创性的论文《BERT:面向语言理解的深度双向变换器预训练》(2018年)发布数月后,谷歌宣布将BERT应用于Google Search,并称这代表了"搜索历史上最大的飞跃之一"。微软必应也不甘示弱,表示"从今年四月开始,我们通过大型变换器模型实现了必应用户过去一年中体验到的最大质量提升"。
这充分证明了这些模型的强大功能和实用价值。它们的加入瞬间显著提升了全球数十亿人依赖的某些最成熟、维护完善的系统。其带来的能力被称为语义搜索,实现了基于含义而非单纯关键词匹配的搜索方式。
在另一条发展路径上,文本生成模型的快速普及使许多用户开始向模型提问并期待获得事实性答案。虽然这些模型能够流利自信地进行回答,但其输出并不总是正确或最新的。这种现象被称为模型的"幻觉",而减少此类问题的主要方法之一就是构建能够检索相关信息并将其提供给大语言模型(LLM)的系统,从而辅助生成更符合事实的答案。这种方法即检索增强生成(RAG),现已成为大语言模型最受欢迎的应用场景之一。
语义搜索与检索增强生成概述
关于如何最佳利用语言模型进行搜索,已有大量研究。这些模型主要分为三大类:密集检索(dense retrieval)、重排序(reranking)和检索增强生成(RAG)。以下是对这三类模型的概述,本章后续内容将对此展开详细阐述:
密集检索
密集检索系统基于嵌入(embeddings)概念——这一概念在前几章中已有所涉及——将搜索问题转化为查找经过嵌入向量处理的查询语句(在查询和文档均被转换为嵌入向量后)的最近邻文本。如图8-1所示,密集检索通过接收搜索查询、查阅文本库并输出一组相关结果来实现这一过程。
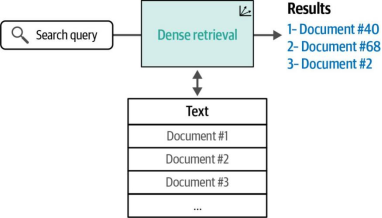
图8-1. 密集检索是语义搜索的核心方法之一,其原理是通过文本嵌入(text embeddings)的相似度来实现相关结果的检索
搜索系统通常由多个步骤组成的流水线构成。重排序语言模型是其中一个环节,其任务是对查询结果子集的相关性进行评分,并根据这些评分调整结果的排序顺序。如图8-2所示,重排序器与稠密检索的不同之处在于它需要额外输入:即搜索流程前一步骤产生的结果集
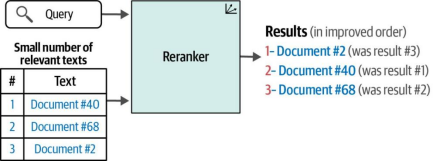
图8-2. 重排器(Rerankers)作为语义搜索的第二种关键类型,接收一个搜索查询和一组结果,并按相关性重新排序,通常会显著提升结果的质量
RAG
大型语言模型(LLM)文本生成能力的提升催生了一种新型搜索系统,这类系统包含一个能根据查询生成答案的模型。图8-3展示了此类生成式搜索系统的示例。
生成式搜索属于更广泛系统类别的一个子类,这类系统更合适的名称是RAG系统(检索增强生成系统)。RAG系统是整合了搜索功能的文本生成系统,其目的是减少模型生成内容的“幻觉”(即不真实或错误信息)、提高事实准确性,和/或将生成模型的输出锚定在特定数据集上。
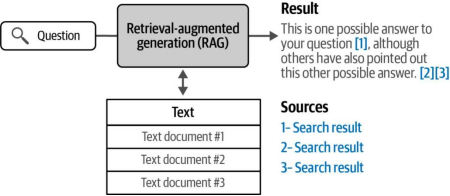
图8-3. RAG系统会生成针对问题的答案,并(最好)引用其信息来源
本章的其余部分将更详细地讨论这三种类型的系统。虽然这些是主要类别,但它们并不是搜索领域中大型语言模型(LLM)的全部应用。
基于语言模型的语义搜索
现在让我们更详细地探讨可以提升语言模型搜索能力的主要系统类别。我们将从密集检索开始,然后依次讨论重排序和检索增强生成(RAG)。
密集检索
回想一下,嵌入(embeddings)技术能将文本转化为数值表示。这些数值可以视为空间中的点(如图8-4所示)。距离相近的点表示它们对应的文本具有相似性。例如在这个案例中,文本1和文本2彼此更为相似(因为它们的点距离较近),而文本3则差异较大(因其对应的点距离更远)。
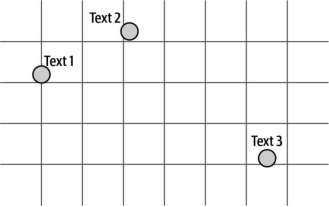
图8-4. 嵌入的直观解释:每个文本表示为一个点,语义相近的文本在空间中彼此靠近
这是用于构建搜索系统的特性。在这种情况下,当用户输入搜索查询时,我们会对该查询进行嵌入处理,从而将其投影到与文本库相同的向量空间中。随后,我们只需在该空间中找到与该查询最接近的文档,这些文档即为搜索结果(图8-5)。
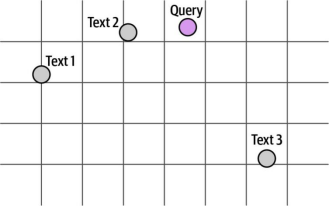
图8-5. 密集检索依赖于搜索查询与其相关结果在向量空间中距离较近的特性
根据图8-5中的距离判断,"文本2"是该查询的最佳结果,其次是"文本1"。但这里可能产生两个疑问:
• 是否应该返回"文本3"作为结果?这需要系统设计者自行决定。有时设置相似度得分的最大阈值来过滤无关结果是必要的(特别是在语料库中没有相关结果时)
• 查询与其最佳结果是否总是语义相似?并非总是如此。这就是为什么需要通过问答对训练语言模型来提升检索效果的原因。第10章将详细解释这一过程。
图8-6展示了文档分块(chunking)的处理过程:先将文档切分成多个块,然后对每个块生成嵌入向量(embedding),这些向量将被存储在向量数据库中以备检索。
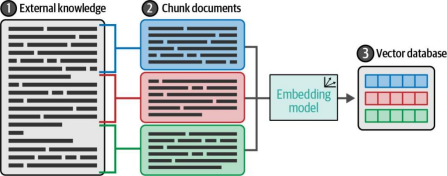
图8-6. 将外部知识库转换为向量数据库后,可通过该向量数据库查询与原知识库相关的信息
密集检索示例
让我们通过使用 Cohere 在维基百科上搜索电影《星际穿越》的页面,来看一个密集检索的示例。在这个示例中,我们将完成以下步骤:
1.获取希望可搜索的文本,并进行轻量处理以将其分块为句子。
2.对句子进行嵌入(生成向量)。
3.构建搜索索引。
4.执行搜索并查看结果。
通过访问 https://oreil.ly/GxrQ1 注册以获取你的 Cohere API 密钥。将密钥粘贴到以下代码中。运行本示例无需支付任何费用。
让我们导入所需的库:
import cohere
import numpy as np
import pandas as pd
from tqdm import tqdm
# Paste your API key here. Remember to not share publicly
api_key = ''
# Create and retrieve a Cohere API key from os.cohere.ai
co = cohere.Client(api_key)text = """
Interstellar is a 2014 epic science fiction film co-written, directed, and pro
duced by Christopher Nolan.
It stars Matthew McConaughey, Anne Hathaway, Jessica Chastain, Bill Irwin,
Ellen Burstyn, Matt Damon, and Michael Caine.
Set in a dystopian future where humanity is struggling to survive, the film
follows a group of astronauts who travel through a wormhole near Saturn in
search of a new home for mankind.
Brothers Christopher and Jonathan Nolan wrote the screenplay, which had its
origins in a script Jonathan developed in 2007.
Caltech theoretical physicist and 2017 Nobel laureate in Physics[4] Kip Thorne
was an executive producer, acted as a scientific consultant, and wrote a tie-in
book, The Science of Interstellar.
Cinematographer Hoyte van Hoytema shot it on 35 mm movie film in the Panavision
anamorphic format and IMAX 70 mm.
Principal photography began in late 2013 and took place in Alberta, Iceland,
and Los Angeles.
Interstellar uses extensive practical and miniature effects and the company
Double Negative created additional digital effects.
Interstellar premiered on October 26, 2014, in Los Angeles.
In the United States, it was first released on film stock, expanding to venues
using digital projectors.
The film had a worldwide gross over $677 million (and $773 million with subse
quent re-releases), making it the tenth-highest grossing film of 2014.
It received acclaim for its performances, direction, screenplay, musical score,
visual effects, ambition, themes, and emotional weight.
It has also received praise from many astronomers for its scientific accuracy
and portrayal of theoretical astrophysics. Since its premiere, Interstellar
gained a cult following,[5] and now is regarded by many sci-fi experts as one
of the best science-fiction films of all time.
Interstellar was nominated for five awards at the 87th Academy Awards, winning
Best Visual Effects, and received numerous other accolades"""
# Split into a list of sentences
texts = text.split(' .' )
# Clean up to remove empty spaces and new lines
texts = [t.strip(' \n' ) for t in texts]对文本块进行嵌入。现在我们将对文本进行嵌入处理。我们会将它们发送至Cohere API,每个文本都会返回一个向量:
# Get the embeddings
response = co.embed(
texts=texts,
input_type="search_document",
).embeddings
embeds = np.array(response)
print(embeds.shape)这会输出 (15, 4096),表示我们有15个向量,每个向量大小为4096。
构建搜索索引。在搜索之前,我们需要构建一个搜索索引。索引用于存储嵌入向量,并经过优化,即使有大量数据点也能快速检索最近邻:
import faiss
dim = embeds.shape[1]
index = faiss.IndexFlatL2(dim)
print(index.is_trained)
index.add(np.float32(embeds))使用索引进行检索。现在我们可以使用任意查询来搜索数据集。只需将查询文本转换为嵌入向量并提交给索引,它就会从维基百科文章中检索最相似的句子。
定义我们的搜索函数:
def search(query, number_of_results=3):
# 1. Get the query's embedding
query_embed = co.embed(texts=[query],
input_type="search_query",).embeddings[0]
# 2. Retrieve the nearest neighbors
distances , similar_item_ids = index.search(np.float32([query_embed]), num
ber_of_results)
# 3. Format the results
texts_np = np.array(texts) # Convert texts list to numpy for easier indexing
results = pd.DataFrame(data={'texts' : texts_np[similar_item_ids[0]],
'distance' : distances[0]})
# 4. Print and return the results
print(f"Query:'{query}' \nNearest neighbors:")
return results现在可以输入查询并搜索文本了!
query = "how precise was the science"
results = search(query)
results这将产生如下输出:
| texts | distance | |
| 0 | It has also received praise from many astronomers for its scientific accuracy and portrayal of theoretical astrophysics | 10757.379883 |
| 1 | Caltech theoretical physicist and 2017 Nobel laureate in Physics[4] Kip Thorne was an executive producer, acted as a scientific consultant, and wrote a tie-in book, The Science of Interstellar | 11566.131836 |
| 2 | Interstellar uses extensive practical and miniature effects and the company Double Negative created additional digital effects | 11922.833008 |
第一个结果与查询的距离最近,因此是最相似的。查看该结果后,发现它完美地回答了问题。注意,如果我们仅使用关键词搜索,这种情况就不可能发生,因为排名第一的结果并未包含查询中的相同关键词。
实际上,我们可以通过定义一个关键词搜索函数来比较两者的差异,从而验证这一点。我们将使用BM25算法(一种领先的词汇搜索方法)来进行验证。这些代码片段的源代码可参考这个笔记本:
from rank_bm25 import BM25Okapi
from sklearn.feature_extraction import _stop_words
import string
def bm25_tokenizer(text):
tokenized_doc = []
for token in text.lower().split():
token = token.strip(string.punctuation)
if len(token) > 0 and token not in _stop_words.ENGLISH_STOP_WORDS:
tokenized_doc.append(token)
return tokenized_doc
tokenized_corpus = []
for passage in tqdm(texts):
tokenized_corpus.append(bm25_tokenizer(passage))
bm25 = BM25Okapi(tokenized_corpus)
def keyword_search(query, top_k=3, num_candidates=15):
print("Input question:", query)
##### BM25 search (lexical search) #####
bm25_scores = bm25.get_scores(bm25_tokenizer(query))
top_n = np.argpartition(bm25_scores, -num_candidates)[-num_candidates:]
bm25_hits = [{'corpus_id' : idx, 'score' : bm25_scores[idx]} for idx in top_n]
bm25_hits = sorted(bm25_hits, key=lambda x: x['score'], reverse=True)
print(f"Top-3 lexical search (BM25) hits")
for hit in bm25_hits[0:top_k]:
print("\t{:.3f}\t{}".format(hit['score'], texts[hit['corpus_id']].replace("\n", " ")))现在,当我们使用相同的查询进行搜索时,通过密集检索得到的结果集与此前有所不同。
keyword_search(query = "how precise was the science") 结果:
Input question: how precise was the science
Top-3 lexical search (BM25) hits
1.789 Interstellar is a 2014 epic science fiction film co-written, direc-
ted, and produced by Christopher Nolan
1.373 Caltech theoretical physicist and 2017 Nobel laureate in Phys-
ics[4] Kip Thorne was an executive producer, acted as a scientific consultant,
and wrote a tie-in book, The Science of Interstellar
0.000 It stars Matthew McConaughey, Anne Hathaway, Jessica Chastain,
Bill Irwin, Ellen Burstyn, Matt Damon, and Michael Caine
需要注意的是,首个结果虽然与查询词"science"(科学)共享关键词,但并未真正回答问题。在下一节中,我们将探讨如何通过添加重排器(reranker)来改进这个搜索系统。但在此之前,我们需要先完整认识密集检索技术——既要了解其注意事项,也要掌握将文本拆分为块(text chunks)的具体方法。
密集检索的注意事项
了解密集检索的某些局限性及其应对方法十分必要。例如,当文本内容不包含答案时会出现什么情况?此时系统仍会返回结果及其对应的向量距离(distances)。例如:
| texts | distance | |
| 0 | The film had a worldwide gross over $677 million (and $773 million with subsequent re-releases), making it the tenth-highest grossing film of 2014 | 1.298275 |
| 1 | It has also received praise from many astronomers for its scientific accuracy and portrayal of theoretical astrophysics | 1.324389 |
| 2 | Cinematographer Hoyte van Hoytema shot it on 35 mm movie film in the Panavision anamorphic format and IMAX 70 mm | 1.328375 |
在这种情况下,一种可行的启发式方法是设置阈值——例如,将最大相关距离作为阈值。许多搜索系统会向用户提供他们所能获取的最佳信息,然后由用户自行判断其是否相关。
追踪用户是否点击了某个结果(以及是否对该结果满意)这一信息,有助于改进未来的搜索引擎版本。
密集检索的另一个局限性在于,当用户想要查找特定短语的精确匹配时,这种方法并不适用。这种情况下,关键词匹配反而更为有效。这也解释了为何建议采用混合搜索(即同时结合语义搜索和关键词搜索),而非单纯依赖密集检索。
此外,密集检索系统在训练领域之外的场景中表现往往欠佳。例如,若在互联网和维基百科数据上训练了一个检索模型,却将其部署到法律文本领域(且训练集中缺乏足够的法律数据),该模型在法律领域的检索效果将大打折扣。
最后需要指出的是,上述案例中的每个句子仅包含单一信息点,而我们所展示的查询也专门针对这些信息点。那么,如果问题需要跨多个句子才能回答呢?这引出了密集检索系统设计中的一个关键参数:如何对长文本进行分块处理?以及为何需要进行分块?
对长文本进行分块处理
Transformer语言模型的一个主要限制是其上下文窗口大小,这意味着无法直接向模型输入超过其支持词数或令牌数的超长文本。那么,如何对长文本进行嵌入(embedding)呢?
可行的方法有多种,图8-7展示了两种方案:为单个文档生成一个向量 或 为单个文档生成多个向量。

图8-7虽然可以为整个文档创建单一向量,但对于较长文档而言,将其分割为较小区块并生成独立嵌入效果更佳
每个文档一个向量。在这种方法中,我们使用单个向量来表征整个文档。具体实现方式包括:
• 仅对文档的代表性部分进行嵌入,忽略其余文本。这可能意味着只嵌入标题或文档开头部分。这种方式便于快速构建演示系统,但会导致大量信息未被索引因而不可搜索。对于开头部分能概括主旨的文档(如维基百科条目)可能效果尚可,但对于实际系统显然不够理想,因为大量信息会丢失在索引之外。
• 将文档分块嵌入后聚合。通常采用对分块向量取平均的方式进行聚合。这种方法的主要缺陷在于会产生高度压缩的向量,导致文档信息的大量丢失。虽然能满足某些信息需求,但对于需要定位文章中特定信息点的检索场景(这种情况下独立概念向量会有更好表现)则显得不足。
每个文档多个向量。该方法将文档分割为更小的单元进行嵌入,我们的搜索索引将基于这些文本单元向量而非整个文档向量构建。如图8-8所示,展示了多种可能的文本分块策略。
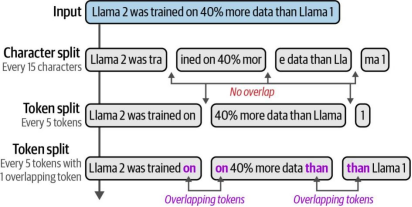
图8-8. 几种分块方法及其对输入文本的影响。使用重叠分块尤为重要,可避免上下文缺失
分块方法更为有效,因为它能全面覆盖文本内容,并且向量往往能够捕捉文本中的单个概念。这使得搜索索引更具表现力。图8-9展示了多种可能的方法。

图8-9. 文档分块以进行嵌入的多种可能方式
对长文本进行分块的最佳方式取决于系统预期处理的文本类型和查询请求。常用方法包括:
• 按句子分块。这种方法的问题在于粒度可能过细,导致生成的向量无法充分捕捉上下文信息
• 按段落分块。当文本由简短段落构成时效果最佳。若段落较长,可采用每3-8个句子为一个分块
• 考虑到某些分块的语义高度依赖周边文本,可通过以下方式融入上下文:
—在分块中加入文档标题
—在分块中加入前文后文内容。这种方式可实现分块间的内容交叠,使相邻分块共享部分周边文本(如图8-10所示)
随着该领域的发展,预计会出现更多创新的分块策略——其中某些方法甚至可能利用大型语言模型动态地将文本切分为有意义的分块单元。

图8-10 将文本分割为重叠块是保留不同片段周围更多上下文的一种策略。
最近邻搜索与向量数据库
如图8-11所示,在查询经过向量化处理后,我们需要从文本库中找到与其最接近的向量。寻找最近邻最直接的方法是计算查询向量与文本库之间的距离。如果你的文本库中有数千到数万个向量,使用NumPy即可轻松实现这一目标,这种方法仍是合理的选择。
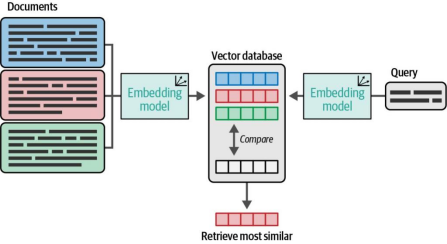
图8-11 正如我们在第3章中所见,我们可以通过比较嵌入(embeddings)来快速找到与查询最相似的文档
当向量规模扩展至数百万量级时,优化的检索方案需依赖近似最近邻搜索库(如Annoy或FAISS)。这类工具可在毫秒级内从海量索引中完成检索,部分方案通过GPU加速计算或将索引分布至机器集群,从而实现对超大规模数据的高效处理。
另一类向量检索系统是专门的向量数据库(如Weaviate或Pinecone)。相较于基础方案,向量数据库支持动态增删向量而无需重建索引,并提供更丰富的搜索定制功能——不仅限于基于向量距离的匹配,还可通过属性过滤、多模态条件组合等方式实现复杂查询需求。
对密集检索任务优化嵌入模型
正如我们在第4章关于文本分类的讨论中所提到的,可以通过微调(fine-tuning)来提升大语言模型(LLM)在特定任务上的性能。类似地,在检索任务中,我们需要优化的是文本嵌入(text embeddings),而非单纯的词元嵌入(token embeddings)。微调的过程需要构建由查询(queries)和相关结果(relevant results)组成的训练数据。
以数据集中的句子“《星际穿越》于2014年10月26日在洛杉矶首映”为例,以下两个查询与该句子高度相关:
相关查询1:“《星际穿越》的上映日期”
相关查询2:“《星际穿越》何时首映?”
微调的目标是让这些查询的嵌入向量与结果句子的嵌入向量在语义空间中更加接近。同时,还需要引入与该句子不相关的负例查询(negative examples),例如:
不相关查询:“《星际穿越》演员阵容”
通过上述示例,我们构建了三组对比:两组正例(相关查询与结果)和一组负例(不相关查询与结果)。如图8-12所示,在微调之前,这三个查询与结果文档的嵌入距离可能是相同的。这并非牵强,因为它们都围绕《星际穿越》展开,未体现语义差异。微调的目的正是通过优化嵌入空间,让模型区分相关与不相关查询的语义距离。
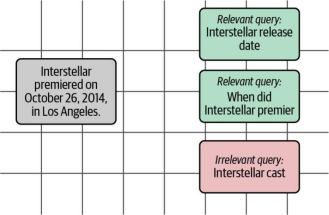
图8-12. 在微调之前,相关与不相关查询的嵌入向量可能都接近于某个特定文档。
微调步骤旨在使相关查询更接近文档,同时使不相关查询远离文档。我们可以在图8-13中看到这种效果。
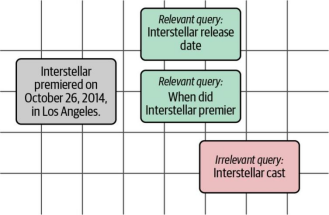
图8-13. 在微调过程中,文本嵌入模型通过结合我们在数据集中定义相关性的方式(通过提供相关和不相关文档的示例来体现),在执行此搜索任务时表现得更为出色
重排序
许多组织已经构建了自己的搜索系统。对于这些组织而言,将语言模型作为搜索流程中的最终步骤来集成是一种更便捷的方式。这一步骤的任务是根据与搜索查询的相关性对搜索结果进行重新排序。仅需这一环节就能显著提升搜索质量,实际上微软必应(Microsoft Bing)正是通过添加此类技术,利用类BERT模型实现了搜索效果的改进。图8-14展示了一个作为两阶段搜索系统中第二阶段的重排搜索系统架构。.
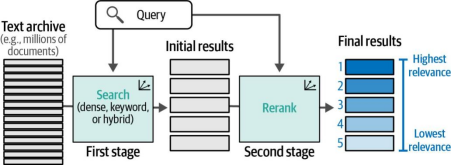
图8-14. LLM重排器作为搜索流程的一部分运行,其目标是根据相关性对多个入围的搜索结果进行重新排序
重排序示例
重排序器(reranker)接收搜索查询和若干搜索结果,并返回这些文档的最优排序顺序,使得与查询最相关的文档排在前列。Cohere 的 Rerank 端点提供了一种简单的使用首个重排序器的方式。我们只需向其传入查询和文本,即可直接获取结果,无需进行训练或调优。
query = "how precise was the science"
results = co.rerank(query=query, documents=texts, top_n=3, return_docu
ments=True)
results.results我们可以打印这些结果:
for idx, result in enumerate(results.results):
print(idx, result.relevance_score , result.document.text) Output:0 0.1698185 It has also received praise from many astronomers for its scien-
tific accuracy and portrayal of theoretical astrophysics
1 0.07004896 The film had a worldwide gross over $677 million (and $773 mil-
lion with subsequent re-releases), making it the tenth-highest grossing film
of 2014
2 0.0043994132 Caltech theoretical physicist and 2017 Nobel laureate in Phys-
ics[4] Kip Thorne was an executive producer, acted as a scientific consultant,
and wrote a tie-in book, The Science of Interstellar
这表明重排器对第一个结果的置信度要高得多,为其分配了0.16的相关性得分,而其他结果的相关性得分则低得多。在这个基础示例中,我们向重排器传递了全部15篇文档。但在实际场景中,索引库通常包含数千甚至数百万条目,此时我们需要先筛选出约100或1000个候选结果,再将这些候选提交给重排器进行精排。这种初步筛选步骤被称为搜索流程的第一阶段。
第一阶段的检索器可以采用关键词搜索、密集检索,或者更优的混合检索方案(同时结合两种方法)。我们可以通过改造之前的示例来观察:在关键词搜索系统中引入重排器后性能提升的效果。具体来说,我们可以优化关键词搜索函数,使其先通过关键词检索获取前10个结果,再使用重排模型从中优选出前3个结果:
def keyword_and_reranking_search(query, top_k=3, num_candidates=10):
print("Input question:", query)
##### BM25 search (lexical search) #####
bm25_scores = bm25.get_scores(bm25_tokenizer(query))
top_n = np.argpartition(bm25_scores, -num_candidates)[-num_candidates:]
bm25_hits = [{'corpus_id' : idx, 'score' : bm25_scores[idx]} for idx in top_n]
bm25_hits = sorted(bm25_hits, key=lambda x: x['score'], reverse=True)
print(f"Top-3 lexical search (BM25) hits")
for hit in bm25_hits[0:top_k]:
print("\t{:.3f}\t{}".format(hit['score'], texts[hit['corpus_id']].replace("\n", " ")))
#Add re-ranking
docs = [texts[hit['corpus_id']] for hit in bm25_hits]
print(f"\nTop-3 hits by rank-API ({len(bm25_hits)} BM25 hits re-ranked)")
results = co.rerank(query=query, documents=docs, top_n=top_k, return_documents=True)
# print(results.results)
for hit in results.results:
# print(hit)
print("\t{:.3f}\t{}".format(hit.relevance_score, hit.document.text.replace("\n", " ")))现在我们可以发送查询,检查关键词搜索的结果,接着让关键词搜索筛选出前10个结果(即初步筛选后的候选集),最后将这些结果传递给重排器进行精细排序:
keyword_and_reranking_search(query = "how precise was the science")结果:
Input question: how precise was the science
Top-3 lexical search (BM25) hits
1.789 Interstellar is a 2014 epic science fiction film co-written, directed,
and produced by Christopher Nolan
1.373 Caltech theoretical physicist and 2017 Nobel laureate in Physics[4] Kip
Thorne was an executive producer, acted as a scientific consultant, and wrote
a tie-in book, The Science of Interstellar
0.000 Interstellar uses extensive practical and miniature effects and the com-
pany Double Negative created additional digital effects
Top-3 hits by rank-API (10 BM25 hits re-ranked)
0.004 Caltech theoretical physicist and 2017 Nobel laureate in Physics[4] Kip
Thorne was an executive producer, acted as a scientific consultant, and wrote
a tie-in book, The Science of Interstellar
0.004 Set in a dystopian future where humanity is struggling to survive, the
film follows a group of astronauts who travel through a wormhole near Saturn
in search of a new home for mankind
0.003 Brothers Christopher and Jonathan Nolan wrote the screenplay, which had
its origins in a script Jonathan developed in 2007
我们观察到,关键词搜索仅对包含部分关键词的两条结果赋予了分数。在第二组结果中,重排器会合理地将第二条结果提升为该查询最相关的结果。虽然这只是展示效果的简单示例,但实际应用中这种处理流程能显著提升搜索质量。在MIRACL这样的多语言基准测试中,重排器可使性能从36.5提升至62.8(以nDCG@10作为衡量标准,关于评估方法的详细说明将在本章后文展开)。
利用Sentence Transformers库进行开源检索与重排序
若希望在本机搭建本地检索与重排序系统,可使用Sentence Transformers开源库。安装说明请参考文档:https://oreil.ly/jJOhV。具体实施方法及代码示例可查阅该库文档中的"检索与重排序"(Retrieve & Re-Rank)章节。
重排模型的工作原理
构建LLM搜索重排器的一种流行方法是:将查询词和每个搜索结果同时输入作为交叉编码器的LLM模型。这意味着查询词和候选结果会同时呈现给模型,使模型能够在给出相关性评分前同时"观察"这两段文本(如图8-15所示)。所有文档会以批次形式同时处理,但每个文档与查询的相关性评估是独立进行的。这些评分将决定搜索结果的重新排序顺序。这种方法在题为《基于BERT的多阶段文档排序》的论文中有详细描述,有时也被称为monoBERT方法。
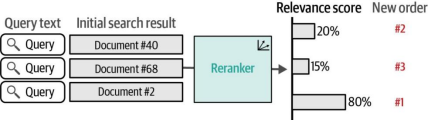
图8-15. 重排器通过同时分析文档和查询内容,为每个文档分配相关性得分。
将搜索表述为相关性评分本质上归结为一个分类问题。根据这些输入,模型会输出一个0到1之间的分数,其中0表示不相关,1表示高度相关。这应该与您在第4章中接触过的分类讨论内容相似。
若想深入了解大型语言模型在搜索领域的应用发展,强烈推荐阅读《Pretrained Transformers for Text Ranking: BERT and Beyond》一书,该著作详细梳理了此类模型截至2021年的演进历程。(注:原文"tanking"疑似为"ranking"笔误,此处已修正)
检索评估指标
语义搜索通过信息检索(IR)领域的指标进行评估。下面我们讨论其中一个常用指标:平均精度均值(Mean Average Precision, MAP)。
评估搜索系统需要三个核心组件:文本档案库、一组查询(queries),以及相关性判断标注(用于指示每个查询对应的相关文档)。这些组件可参考图8-16。
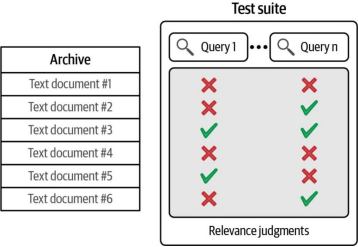
图8-16. 为了评估搜索引擎,我们需要一个包含查询和相关性判断标注的测试套件,这些标注用于指示归档文档中哪些文档与每个查询相关
通过这个测试套件,我们可以开始探索搜索引擎的评估方法。让我们从一个简单示例入手:假设我们向两个不同的搜索引擎提交同一个查询请求(查询1),并获得两组结果集(如图8-17所示)。假设我们将结果数量限制为三个。
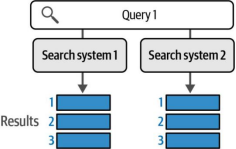
图8-17. 为了比较两个搜索系统,我们将测试集中的同一查询同时发送给这两个系统,并查看它们返回的前几个结果。
为了判断哪个系统更优,我们需要参考该查询的相关性评估结果。图8-18展示了返回结果中哪些被判定为相关。
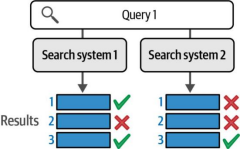
图8-18. 通过观察测试集中的相关性判断结果,我们可以看出系统1的表现优于系统2
这清楚展示了系统1优于系统2的典型案例。直观的做法可能是简单地统计每个系统检索到的相关结果数量:系统1在三次检索中正确命中两次,而系统2仅正确一次。但如果遇到像图8-19这样的情况呢?此时两个系统仍然各从三次检索中正确命中一个相关结果,但这些结果所处的排名位置却不同。
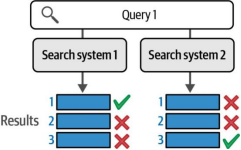
图8-19. 我们需要一个评分系统,当系统1将相关结果排在高位时(即使两个系统在各自前三项结果中都只检索到一个相关结果),该系统能因此获得更高分数
在这种情况下,我们可以直观判断系统1优于系统2,因为首位(最重要位置)的结果是正确的。但我们如何用数值或分数来衡量这个结果的优越程度?平均精度均值(Mean Average Precision)正是一种能够量化这种差异的评估指标。
在这种情况下分配数值分数的一种常用方法是平均精度(average precision)。该方法对系统1针对该查询的返回结果评分为1,而对系统2的评分则为0.3。因此,我们首先需要了解如何通过计算平均精度来评估单组结果,然后再学习如何通过聚合所有测试用例中的查询结果来系统性地评估整个系统的性能。
对单个查询进行平均精度评分
为了对搜索系统进行评分,我们可以专注于对相关文档进行评分。让我们从一个在测试集中仅有一个相关文档的查询开始分析。
第一个示例很简单:搜索系统将相关结果(针对此查询唯一可用的结果)放在了首位。这使得系统获得了完美的1.0分。图8-20展示了这一计算过程:查看第一个位置时,存在一个相关结果,因此位置1处的精度为1.0(计算方式为位置1处的相关结果数量除以当前查看的位置数)。
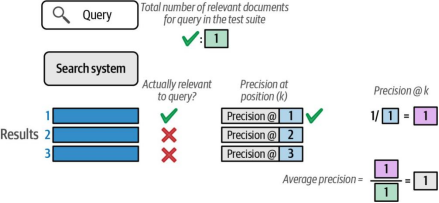
图8-20. 要计算平均精度均值(MAP),我们首先从位置1开始计算每个位置的准确率。
由于我们仅对相关文档进行评分,因此可以忽略非相关文档的得分并在此停止计算。然而,如果系统实际上将唯一的相关结果放在第三位,这会如何影响得分呢?图8-21展示了这种情况会导致惩罚。
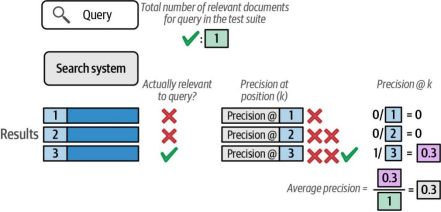
图8-21. 如果系统将不相关文档排在相关文档之前,其精确率得分将受到惩罚。
现在让我们观察包含多个相关文档的查询案例。图8-22展示了这种场景下的计算过程,并说明了平均计算是如何发挥作用的。
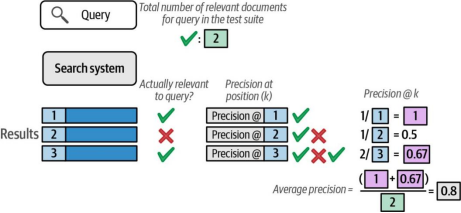
图8-22. 当文档包含多个相关文档时,其平均精度需要综合考量所有相关文档在前k个结果中的精度表现
通过平均平均精度评估多查询场景
在理解了k精度和平均精度的概念后,我们可以将这些知识扩展到能够对测试集内所有查询进行系统评分的指标——平均平均精度(Mean Average Precision, MAP)。如图8-23所示,该指标通过对每个查询的平均精度值取均值计算得出。
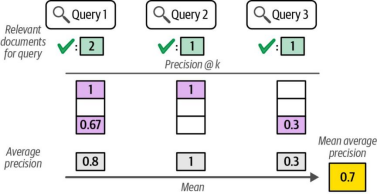
图8-23. 平均精度均值(MAP)通过计算系统在测试集中每个查询的平均精度得分,并对这些得分取平均值,最终生成一个可用于比较不同搜索系统的统一指标
你可能会疑惑为何同一操作既被称为“均值”(mean)又被称为“平均”(average)。这可能是出于语言习惯的选择——MAP(Mean Average Precision)的缩写比“平均平均精度”更简洁易记。
现在,我们有了一个可用来对比不同系统的统一指标。若想深入了解评估指标,可参考Christopher D. Manning、Prabhakar Raghavan和Hinrich Schütze所著《信息检索导论》(剑桥大学出版社)中“信息检索评估”一章。
除平均精度均值外,搜索系统常用的另一指标是归一化折损累计增益(nDCG)。该指标的特点在于,它允许文档相关性不为二元对立(相关/不相关),且在测试集和评分机制中,一个文档可以被标注为比另一个文档“更相关”。这使得nDCG能更细致地反映搜索结果的质量差异。
检索增强生成(RAG)
大语言模型(LLMs)的广泛应用使人们开始向其提问并期待获得基于事实的答案。尽管这些模型能正确回答某些问题,但它们也会自信地给出许多错误答案。为解决这一问题,行业主流方法采用了论文《检索增强生成在知识密集型自然语言处理任务中的应用》(2020年)提出的RAG技术,如图8-24所示。
1 Patrick Lewis et al. “Retrieval-augmented generation for knowledge-intensive NLP tasks.” Advances in Neural Information Processing Systems 33 (2020): 9459–9474.
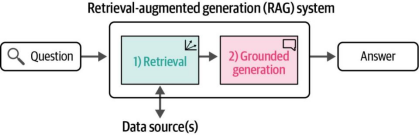
图8-24 基本RAG流程由搜索步骤和基于检索的生成步骤组成,其中大语言模型(LLM)会同时接收用户问题和搜索步骤检索到的信息作为提示
RAG系统集成了搜索与生成双重能力。相较于纯生成式系统,其改进体现在两个方面:一是减少模型幻觉现象,二是提升输出事实准确性。该系统支持"用我的数据对话"应用场景——用户与公司可借助内部数据或特定数据源(例如书籍)对大语言模型进行事实锚定。这一理念也延伸到了搜索系统领域,目前越来越多的搜索引擎开始整合大语言模型,用于总结搜索结果或回答用户提问,典型代表包括Perplexity、Microsoft Bing AI和Google Gemini等。
从搜索到RAG
现在让我们将搜索系统转换为RAG系统。具体方法是在搜索流程的末端添加一个大语言模型(LLM)。我们将问题与排名最高的检索文档一起提供给LLM,并要求它基于搜索结果提供的上下文回答问题。图8-25展示了这一过程的示例。
这一生成步骤被称为基于上下文的生成(grounded generation),因为我们为LLM提供的检索相关信息为其建立了特定的上下文,使LLM能够聚焦于我们感兴趣的领域。若继续之前的嵌入搜索(embeddings search)示例,图8-26展示了在搜索完成后,基于上下文的生成如何衔接整个流程。
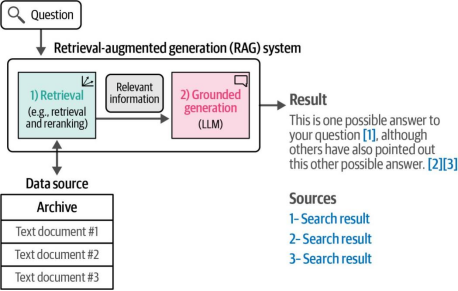
图8-25. 生成式搜索在搜索流程末端通过引用来源(由搜索系统前序步骤返回)来生成答案和摘要
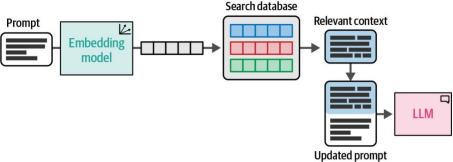
图8-26. 通过比较嵌入向量间的相似性,找到与输入提示最相关的信息。该信息将被补充至提示词中,再输入大语言模型处理
示例:使用大语言模型 API 进行基于知识生成
让我们看看如何在搜索结果后添加一个基于知识生成的步骤,构建首个检索增强生成(RAG)系统。在此示例中,我们将使用 Cohere 托管的大语言模型(该模型基于本章前面讨论的搜索系统)。我们将通过嵌入搜索检索相关度最高的文档,然后将这些文档与问题一起传递给 co.chat 端点,从而生成基于知识的答案:
query = "income generated"
# 1- Retrieval
# We'll use embedding search. But ideally we'd do hybrid
results = search(query)
# 2- Grounded Generation
docs_dict = [{'text' : text} for text in results['texts']]
response = co.chat(
message = query,
documents=docs_dict
)
print(response.text)结果:
The film generated a worldwide gross of over $677 million, or $773 million
with subsequent re-releases.
我们高亮显示了部分文本,因为模型指出这些文本片段的来源是我们传入的第一个文档:
citations=[ChatCitation(start=21, end=36, text='worldwide gross', docu-
ment_ids=['doc_0']), ChatCitation(start=40, end=57, text='over $677 million',
document_ids=['doc_0']), ChatCitation(start=62, end=103, text='$773 million
with subsequent re-releases.', document_ids=['doc_0'])]
documents=[{'id': 'doc_0', 'text': 'The film had a worldwide gross over $677
million (and $773 million with subsequent re-releases), making it the tenth-
highest grossing film of 2014'}]
示例:使用本地模型实现RAG
现在,让我们尝试用本地模型复现这一基本功能。虽然我们将无法进行跨度引用(span citations),且较小的本地模型在性能上也不及更大的托管模型,但这有助于演示整个流程。首先,我们将从下载量化模型开始.
加载生成模型
我们首先下载模型:
!wget https://huggingface.co/microsoft/Phi-3-mini-4k-instruct-gguf/resolve/main/
通过llama.cpp、llama-cpp-python和LangChain,我们加载文本生成模型:
from langchain import LlamaCpp
# Make sure the model path is correct for your system!
llm = LlamaCpp(
model_path="Phi-3-mini-4k-instruct-fp16.gguf",
n_gpu_layers=-1,
max_tokens=500,
n_ctx=2048,
seed=42,
verbose=False
)加载嵌入模型
现在,让我们加载一个嵌入语言模型。在这个示例中,我们将选择 BAAI/bge-small-en-v1.5 模型。截至本文撰写时,该模型在 MTEB(大规模多任务嵌入基准)排行榜上名列前茅,且模型体积相对较小。
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
# Embedding model for converting text to numerical representations
embedding_model = HuggingFaceEmbeddings(
model_name='thenlper/gte-small'
)from langchain.vectorstores import FAISS
# Create a local vector database
db = FAISS.from_texts(texts, embedding_model)检索增强生成(RAG)提示模板
提示模板在RAG流程中扮演着关键角色。它是我们向大型语言模型(LLM)传递相关文档的核心环节。为此,我们将创建一个名为context的额外输入变量,用于向LLM提供检索到的文档:
from langchain import PromptTemplate
# Create a prompt template
template = """<|user| >
Relevant information:
{context}
Provide a concise answer the following question using the relevant information
provided above:
{question}<|end| >
<|assistant| >"""
prompt = PromptTemplate(
template=template,
input_variables=["context", "question"]
)
from langchain.chains import RetrievalQA
# RAG pipeline
rag = RetrievalQA.from_chain_type(
llm=llm,
chain_type='stuff' ,
retriever=db.as_retriever(),
chain_type_kwargs={
"prompt": prompt
},
verbose=True
)现在我们准备好调用模型并提问了:
rag.invoke('Income generated')
结果:
The Income generated by the film in 2014 was over $677 million worldwide.
This made it the tenth-highest grossing film of that year. It should be noted,
however, this figure includes both initial ticket sales as well as any subse-
quent re-releases. With these additional releases, total earnings surged to
approximately $773 million. The release format transitioned from traditional
film stock projection in theaters to digital projectors once it was expanded
to various venues in the United States. This shift might have contributed
to wider audience reach and potentially higher grossing figures over time.
However, specific data on how this affected total earnings isn't provided in
the information above.
一如既往,我们可以通过调整提示词来控制模型的生成结果(例如答案长度和语气)。
高级RAG技术
还有几种方法可以提升检索增强生成(RAG)系统的性能,其中部分技术将在下文展开说明。
查询重写
如果RAG系统是一个聊天机器人,当用户问题过于冗长或需要引用对话中之前的上下文时,上述简单的RAG实现在搜索步骤中可能会遇到困难。这就是为什么使用大语言模型(LLM)将原始查询重写为更利于检索步骤获取正确信息的查询是个好主意。例如:
User Question: “We have an essay due tomorrow. We have to write about some animal.
I love penguins. I could write about them. But I could also write about dolphins. Are they animals? Maybe. Let’s do dolphins. Where do they live for example?”
应重写为:
Query: “Where do dolphins live”
这种重写行为可以通过提示词(或API调用)实现。例如,Cohere的API为co.chat提供了专门的查询重写模式。
多查询RAG
下一步改进是将查询重写扩展为支持多查询搜索——当回答特定问题需要多个查询时。例如:
User Question: “Compare the financial results of Nvidia in 2020 vs. 2023”
可能找到一份包含两年数据的文档,但更稳妥的做法是生成两个独立查询:
Query 1: “Nvidia 2020 financial results”
Query 2: “Nvidia 2023 financial results”
然后将两个查询的Top结果合并,提供给模型进行基于事实的生成。一个额外优化是让查询重写器具备判断能力:若无需搜索即可直接生成可靠答案,则跳过检索步骤。
多跳检索增强生成(Multi-hop RAG)
对于更复杂的问题,可能需要通过多次连续的查询来回答。例如:
User Question: “Who are the largest car manufacturers in 2023? Do they each make EVs or not?”
要回答这个问题,系统必须首先搜索:
Step 1, Query 1: “largest car manufacturers 2023”
在获取这些信息(结果为丰田、大众和现代)后,它应当提出后续追问:
Step 2, Query 1: “Toyota Motor Corporation electric vehicles”
Step 2, Query 2: “Volkswagen AG electric vehicles”
Step 2, Query 3: “Hyundai Motor Company electric vehicles”
查询路由
另一个增强功能是让模型具备搜索多个数据源的能力。例如,我们可以指定:当模型收到关于人力资源的问题时,应该搜索公司的人力信息系统(如Notion);而如果是关于客户数据的问题,则应搜索客户关系管理(CRM)系统(如Salesforce)。
智能体式检索增强生成(Agentic RAG)
通过前文的增强功能列表,可以看出我们逐步将更多责任委托给大语言模型(LLM),使其解决愈发复杂的问题。这依赖于LLM评估所需信息需求的能力,以及其利用多数据源的能力。这种LLM的新特性使其越来越接近能对现实世界采取行动的智能体。此时数据源也可以被抽象为工具——例如我们不仅能够搜索Notion,理论上还应能向Notion写入内容。
并非所有LLM都具备前文所述的RAG能力。在本文撰写时,可能只有最大规模的托管模型才能尝试实现此类行为。值得庆幸的是,Cohere公司的Command R+模型在此类任务中表现卓越,并且也开放了其开放权重版本供使用。
RAG评估
目前,如何评估RAG模型仍在持续探索中。一篇值得参考的论文是《Evaluating verifiability in generative search engines》(2023),该研究通过人工评估对不同的生成式搜索引擎进行了测试2。
它从四个维度评估结果:
流畅度
生成的文本是否流畅且连贯。
感知实用性
生成的答案是否有帮助且信息丰富。
引用召回率
关于外部世界的生成陈述中,完全由其引用支持的比例。
引用精确率
生成的引用中,支持其关联陈述的比例。
尽管人工评估始终是首选,但也有一些方法尝试通过让能力强大的大型语言模型(LLM)作为评判者(称为LLM-as-a-judge),对不同生成内容按上述维度打分来实现自动化评估。Ragas 是一款专门实现此功能的软件库。它还计算其他一些实用指标,例如:
忠实度
答案是否与提供的上下文一致。
答案相关性
答案与问题的相关程度。
Ragas的官方文档网站提供了关于如何实际计算这些指标的详细公式说明。
2 Nelson F. Liu, Tianyi Zhang, and Percy Liang. “Evaluating verifiability in generative search engines.” arXiv preprint arXiv:2304.09848 (2023).
总结
在本章中,我们探讨了如何利用语言模型改进现有搜索系统,甚至将其作为新搜索系统的核心。具体方法包括:
密集检索(Dense Retrieval):通过文本嵌入(text embeddings)的相似性实现检索。这类系统会将搜索查询和文档分别编码为嵌入向量,并返回与查询向量最接近的文档。
重排序器(Rerankers):如monoBERT等系统,通过分析查询与候选结果的相关性,对初步筛选的结果进行重新排序。这类模型会为每个文档生成相关性评分,并根据评分优化最终结果排名。
检索增强生成(RAG):在搜索流程末端引入生成式大语言模型(LLM),基于检索到的文档生成答案,并标注引用来源。
我们还讨论了搜索系统的评估方法之一——平均精度均值(Mean Average Precision, MAP),它通过测试集查询及其已知相关性来量化系统性能。然而,评估RAG系统需要多维指标(如忠实度、流畅度等),这些指标可通过人工或LLM作为评判工具来完成。
下一章将探讨如何使语言模型具备多模态能力,使其不仅能处理文本,还能理解图像等多元信息。


















 6535
6535

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











