



 文章讲述了在模型训练中,如何根据CSV文件将图像数据集按类别归类到不同文件夹,并创建一个包含每个图像文件路径和标签的文本文件的过程。使用Python代码实现了这一操作,涉及文件操作和目录结构的调整。
文章讲述了在模型训练中,如何根据CSV文件将图像数据集按类别归类到不同文件夹,并创建一个包含每个图像文件路径和标签的文本文件的过程。使用Python代码实现了这一操作,涉及文件操作和目录结构的调整。
由于模型训练的需要,有时需要把图像数据集重新加标注,并把图像文件的地址及标签写到一个文本文件(*.txt)中。下面是我在准备数据集时遇到的问题及相应的解决方法。训练网络模型用到的数据集是ISIC2018,ISIC2019,有每一个数据集的GroundTruth *.csv文件。
问题:网络模型训练的需要,把每一类图像单独放到一个文件夹中,并生成一个存放所有图像文件位置,并且加有标签的文本文件。文本文件内容如下图所示:
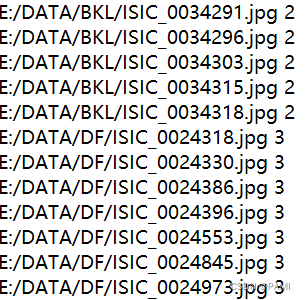
解决方法:
首先根据*.csv文件,把相同类别的文件放到一个文件夹中。结构如下图所示:
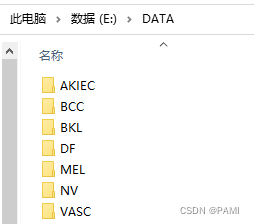
然后,采用下面代码,解决上述问题。
代码:
import os
rootDirectory = 'E:/DATA/' # 存放数据集的根目录,根据自己的实际情况来设定。
dirlist = os.listdir(rootDirectory) # 读出根目录下所有的文件和文件夹,提醒:最后除了文件夹不要有别的文件。
dirlist.sort()
print("打开或者建立DataSet_List.txt文件 ......")
DataList = open(rootDirectory + 'DataSet_List.txt', 'w+') # 打开或创建存放文件位置的*.txt文件。
print("为每一个图像加上标注,并写入DataSet_List.txt文件......")
label = -1
summ = 0
for directory in dirlist:
# # 如果根目录下有单独的文件,通过下面这一句可以跳过该文件,直接找到文件夹中的图像文件。
if os.path.isfile(rootDirectory + directory):
continue
# 读取每一个子文件夹中的图像文件
files = os.listdir(rootDirectory + directory)
files.sort()
label += 1
s = 0
for file in files:
# 对于每一个子文件夹中的图像文件,生成其文件位置,并加标注。
name = rootDirectory + directory + '/' + file + ' ' + str(int(label)) + '\n'
print(name)
DataList.write(name)
s += 1
print("上一类别图像共有{0}张。".format(s))
summ = summ + s
DataList.close()
print("关闭DataSet_List.txt文件。")
print("数据集共有图像"+str(int(summ))+"张,"+str(int(label+1))+"个类别。")
注意:
- 存放每一类图像的子文件夹中只能存放图像文件;
- 根目录下存放每一类图像的子文件夹;生成的*.txt文件可以放在根目录下,也可以放在自己指定的位置。

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









