




是什么
Flink的前身是以构建下一代大数据分析平台为目标的大学科研项目Stratosphere。其于2014年4月被捐赠给Apache软件基金会作为孵化项目,并于同年年底升级为Apache的顶级项目。
Flink是基于实时流处理的一个组件。数据流可以分为无界流和有界流。无界流(DataStream)只有开始而没有结束,比如,外汇市场的不间断交易、服务器日志的持续生成等是无界流;而统计电商网站某个注册用户一周的交易量、生成某个用户每月的话费清单等是有界流(DataSet),它定义了开始节点和结束节点,并且这中间的数据是有序的。处理有界流也被称为批处理(Batch Processing)。
Flink系统架构图:
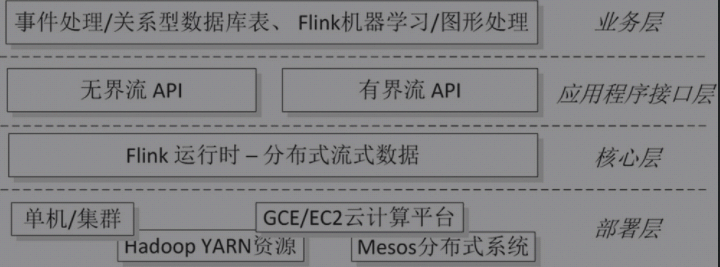
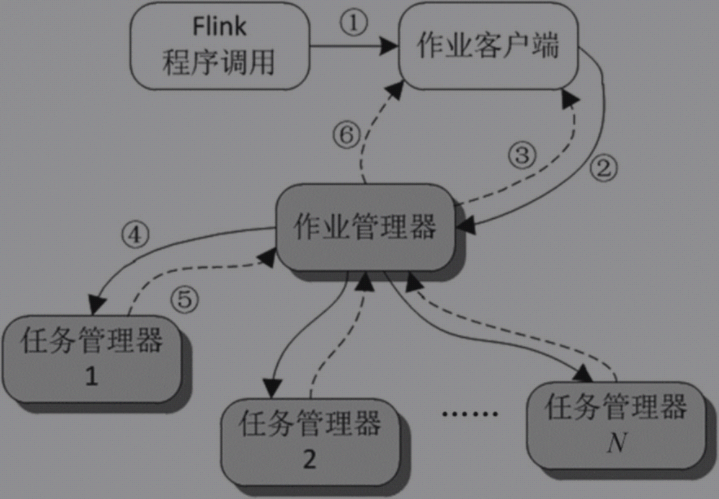
Flink核心层执行过程层
Spark是基于内存运算的分布式处理框架,也可以处理流式数据,而且Spark比Flink出名得早。Spark操作流式数据时是把无界流划分成多个固定时间窗的有界流来处理的;而Flink则正相反,它把有界流作为无界流的特例来处理。因此,Flink是一个更加“彻底”的流处理组件。
安装
一、单节点安装:所谓单节点指的是作业管理器和任务管理器运行在同一台机器上
- 官网下载最新版本的安装包http://flink.apache.org/
- 把tgz文件下载并解压缩到master机器中的/home/hadoop/bigdata/flink/
- 配置环境变量
export FLINK_HOME=/home/hadoop/bigdata/flink
export PATH=$FLINK_HOME/bin:$PATH
- 同时需要配置HADOOP和YARN_CONF_DIR的配置如下
export HADOOP_CONF_DIR=/home/hadoop/bigdata/hadoop/etc/hadoop
export YARN_CONF_DIR=/home/hadoop/bigdata/hadoop/etc/hadoop
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 917
917

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









