




1. HDFS
1.1 特性
- 支持超大文件
- 检测和快速应对硬件故障
- 流式数据访问
- 简化的一致性模型
- 低延迟数据访问
- 大量潇的文件
- 多用户写入、修改文件
1.2 体系结构
- namenode: 分布式文件系统中的管理者,负责管理文件系统命名空间,集群配置和数据块复制。
- datanode: 文件存储的基本单元,以数据块的形式保存HDFS中文件的内容和数据块的数据校验信息
- 客户端和namenode,datanode通信,访问HDFS文件系统。
1.2.1 数据块
数据分块存储,默认大小64MB。
好处:
- 存比磁盘大的文件
- 简化了存储子系统
- 方便容错,有利于数据复制。
1.2.2 namenode 和 secondarynamenode
namenode 维护文件系统的文件目录树,文件/目录的元信息和文件的数据块索引。
secondarynamenode配合namenode,提供了检查点机制。namenode发生故障时,减少停机时间并降低namenode元数据丢失的风险,不支持故障自动恢复。
1.2.3 datanode
- 向namenode报告
- 接收namenode的指令
1.3 HDFS主要流程
1.3.1 客户端到nanenode的文件与目录操作
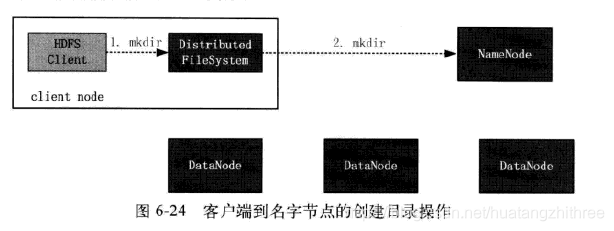
创建子目录
删除子目录
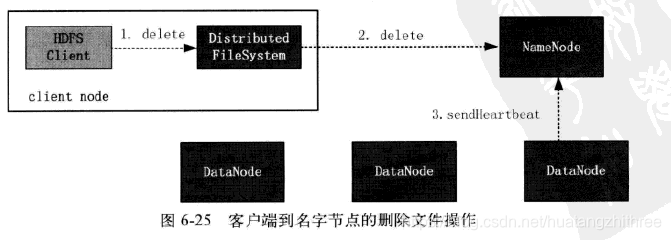
- 客户端发送删除指令给namenode之后,namenode并不会删除而是做标记
- datanode 发送心跳时,才会把删除指令发送给相应的datanode
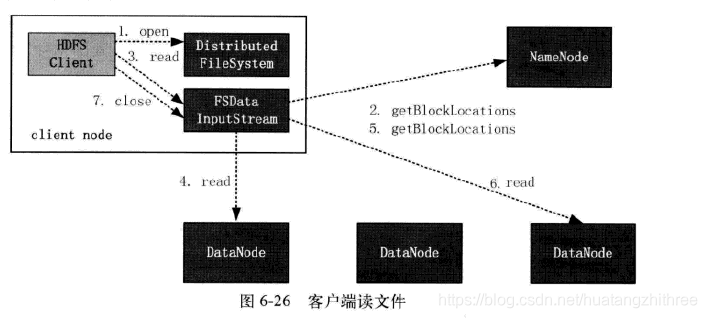
1.3.2 客户端读文件
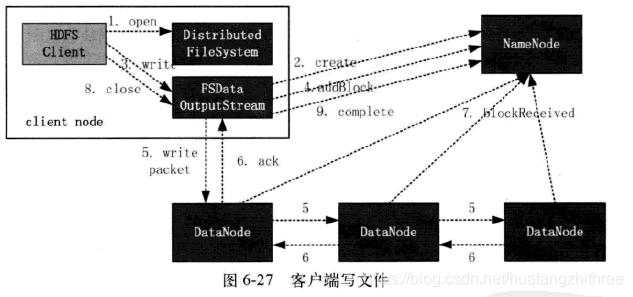
1.3.3 客户端写文件
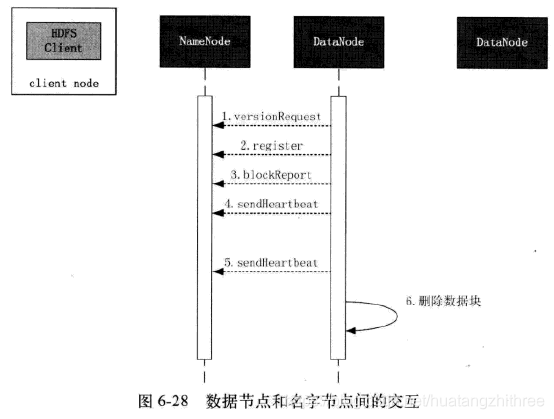
1.3.4 数据节点的启动和心跳
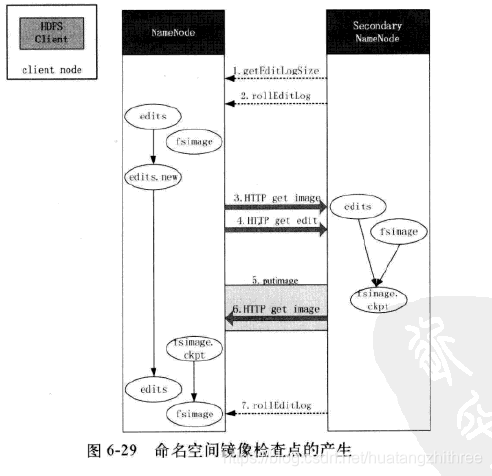
1.3.5 secondarynamenode 合并元数据

















 4032
4032

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









