




本文为记录零生课程学习内容期间相关个人理解,将从以下9个问题逐个展开描述协程。
1、为什么会有协程?
2、协程的实现过程,原语操作(有哪些原语操作)
3、协程如何定义?
4、调度器是什么,调度器如何定义?
5、调度器的执行策略?
6、如何与Posix API做到一致?
7、协程的多核模式?
8、协程的性能如何测试?
一、为什么会有协程?
如果读者网上检索过协程,各文章大部分皆有这句话来描述协程——"协程是一种用户级的轻量级线程"。其中个人的理解有两个点:1、用户级。2、轻量级线程。那么为什么既然已经有了线程还要再来一个“轻量级线程”——协程呢?
个人的理解对于线程而言,线程在Linux系统视角之下与进程并“无区别”,对于Linux进程调度而言是根据task_struct结构体进行调度。而进程和线程在Linux视角下都是task_struct,而他们最大的不同点,个人认为是内存空间。对于进程而言他拥有自己独立的内存空间,而线程共享父进程的内存空间。所以多线程可以利用这一特性可以更方便地榨干整体计算机硬件的性能。但是这仅仅是与进程相对比而言线程拥有开销更小等等好处。
那么既然线程相比进程开销更小,那么在高并发场景下的服务器设计中,总体来说服务端的处理效率主要受两部分影响:1、服务端处理客户端的网络IO处理。2、具体请求的业务逻辑处理。其中第二部分业务逻辑的处理,对于具体业务有对应的处理方案。这部分不足以在此抽象出一种比较合理的情况。但是第一部分是服务端的共性且是服务端无可避免的一部分任务。
而有前文相关TCP、UDP等技术的介绍,了解对于网络IO而言,大概流程是应用程序通过recv/send、recvfrom/sendto等获取网卡中的网络数据。这部分的效率相比CPU的计算效率或者内存操作的效率这就差出了数量级。如果采取同步IO的方式,CPU就要等待网络IO完成才可继续执行后续的代码段,而这部分时间就浪费了进程的CPU时间片。
对于这个问题可以采取异步IO的方式来解决。对比两端代码:第一部分是同步方式,第二部分是利用线程池实现异步。
int handle(int sockfd) {
recv(sockfd, rbuffer, length, 0);
parser_proto(rbuffer, length);
send(sockfd, sbuffer, length, 0);
}
int thread_cb(int sockfd) {
// 此函数是在线程池创建的线程中运行。
// 与handle不在一个线程上下文中运行
recv(sockfd, rbuffer, length, 0);
parser_proto(rbuffer, length);
send(sockfd, sbuffer, length, 0);
}
int handle(int sockfd) {
//此函数在主线程 main_thread 中运行
//在此处之前,确保线程池已经启动。
push_thread(sockfd, thread_cb); //将sockfd放到其他线程中运行。
}上述同步IO是学习过程中比较常见的IO处理方式,第二部分异步IO是通过线程池实现异步操作。具体思路就是:主进程通过IO多路复用获取到就绪IO事件结合,然后在处理每个IO时无外乎两种(不讨论意外情况):读/写。主进程通过之前新建的”一堆“线程,将这个耗时的IO处理工作交给线程池中的线程去做,然后主进程继续处理后续的待处理IO事件集合。此时当线程处理IO事件完成后会返回处理结果,这样就实现了异步IO。
这样处理确实提高整体的处理效率,但是当有成千上百个连接时是不是就需要创建成千上百个线程。这就造成非常大的开销。生产环境更不可能以这种方式处理。但是对于线程的开销这部分工作是由操作系统做的,用户层无法干预,但是用户层可以仿照进程的思想创造一个类似进程的东西——”协程“。
综上,个人理解对于协程的诞生,核心的驱动力是因为在高并发场景下CPU的计算速度与外部设备IO速度的差异驱动产生的。协程的作用就是为了弥补线程的开销大,并实现高效的异步IO操作,以解决CPU的计算速度与外部设备IO速度的差异导致CPU时间片被浪费这一问题。所以对于协程而言他是”一种用户级的轻量级线程“应该就可以理解了。用户级——可以由用户层定义,避免像线程那样大的开销。轻量级线程——实现异步IO操作。当然除此之外也有其他的好处:降低高并发编程的复杂度,以同步的编程方式,实现异步的性能。这也是一个非常好的优点。
二、协程的实现过程,原语操作(有哪些原语操作)
上文将协程描述为:”一种用户级的轻量级线程“。因此对于协程的实现过程也可以类比线程进行实现。其中就包括了协程需要实现的原语操作。
对于线程,有操作系统基础的话可以大概描述出来。首先它拥有当前状态,这个状态包含初始,运行,阻塞,等待,超时等待,终止这六种。所以对于协程我们也要对应有这几种状态。针对这几种状态描述协程的大概实现过程。
一个协程对应一个IO句柄(第一部分描述过,协程主要是为了解决IO和CPU速度差异问题)。以网络通信为例,一个socketfd被创建时,应该创建一个协程与其对应,也就是初始化。然后由CPU进行调度,但是CPU是线程层面的概念,所以需要实现一个拥有调度功能的“玩意”——调度器。协程被创建后会进入就绪队列(类比线程)。然后轮到他之后会开始运行,也就是运行态。然后对于线程而言,他不一定会进入阻塞态,因为他的处理工作中不一定包含阻塞事件。但是协程必然对应一个socketfd,所以协程大概率会进入阻塞态。类比线程,当线程阻塞之后他会进入阻塞队列,然后CPU时间片交给后续的线程/进程使用。协程也是同理,对于协程处理这个socketfd过程中,如果这个句柄的IO事件并未准备就绪就需要让这个协程交出当前的CPU使用权,但是这是通过应用层实现的,在真正的CPU角度仍然是创建协程的进程在使用CPU。这里就对应协程的共有的原语操作——yield(让出)。当他让出后,此时的CPU使用权交给谁呢?应该是调度器,因为调度器维护了一堆协程,应该交付给调度器来决定后续让那个协程工作。这里就对应协程另一个共有的原语操作——resume(恢复)。新运行的协程的执行流程就和上一个一样了,不再赘述。那么之前的那个协程呢,类比线程,一个线程等待的阻塞事件就绪后就会重新进入就绪队列等待调度。此时协程也一样,不过对于应用层而言协程等待的阻塞事件如何感知呢?这里就可以使用epoll,这里附上一段代码,最初本人看到时理解起来也是比较“抽象”。
epoll_ctl(epfd, EPOLL_CTL_DEL, sockfd, NULL);
recv(sockfd, buffer, length, 0);
//parser_proto(buffer, length);
send(sockfd, buffer, length, 0);
epoll_ctl(epfd, EPOLL_CTL_ADD, sockfd, NULL);这里先将这个事件从epoll中删除,然后recv,send系统调用,也就是业务逻辑的处理。然后又将其加入到epoll中。这里理解需要结合整体协程执行的上下文来理解。一个协程对应的IO事件,是否应该让出CPU使用,应该看这个IO事件是否准备就绪,所以在epoll_del 之前他应该是已经准备就绪的了,这样才不会浪费阻塞的时间。所以此时从epoll中删除这个事件能够保证 sockfd 只在一个上下文中能够操作IO。然后开始执行IO事件,执行完成后,后续就应该等待下次IO事件的到来,就需要重新加入epoll也就是epoll_add。对应实现代码如下:
// 创建协程recv接口
ssize_t nty_recv(int fd, void *buf, size_t len, int flags) {
struct epoll_event ev;
ev.events = POLLIN | POLLERR | POLLHUP;
ev.data.fd = fd;
//加入epoll,然后yield
nty_epoll_inner(&ev, 1, 1);
//resume
ssize_t ret = recv(fd, buf, len, flags);
return ret;
}
// 加入epoll,更改状态,加入wait集合,然后yield与resume
static int nty_epoll_inner(struct epoll_event *ev, int ev_num, int timeout) {
nty_schedule * sched = nty_coroutine_get_sched();
nty_coroutine *co = sched->curr_thread;
int i;
for (i = 0; i < ev_num; i++) {
epoll_ctl(sched->epfd, EPOLL_CTL_ADD, ev->data.fd, ev);
co->events = ev->events;
//加入wait集合,添加wait状态
nty_schedule_sched_wait(co, ev->data.fd, ev->events, timeout);
}
//yield
nty_coroutine_yield(co);
for (i = 0; i < ev_num; i++) {
epoll_ctl(sched->epfd, EPOLL_CTL_DEL, ev->data.fd, ev);
//移除wait集合,移除wait状态
nty_schedule_desched_wait(ev->data.fd);
}
return ev_num;
}上述内容大概描述了协程的实现流程。其中包含两个关键原语操作:yield和resume。对应多个协程的原语操作如下图:
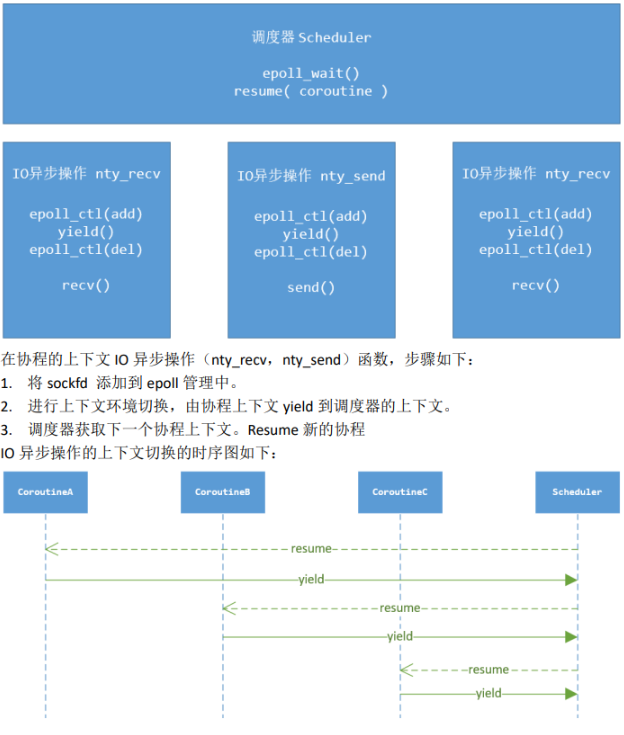
理解了yield和resume后,对于这两个原语的实现也是重点。其中两个动作都是在切换CPU执行的上下文内容。
其中有三种实现方式:
1、setjmp/longjmp
2、ucontext
3、汇编代码实现切换
这里的理解我认为汇编代码比较好理解,因为更贴近进程/线程切换的理解方式。对于进程的切换主要是对CPU寄存器中的当前内容进行保存(保存当前进程上下文)然后写入后续需要运行进程的上下文内容。也就是写入要运行协程相关内容到CPU寄存器。这里可以继续钻研其中各个寄存器的作用。本文不再赘述。附上代码:
//寄存器 cpu上下文
typedef struct _nty_cpu_ctx {
void *rsp;//栈顶
void *rbp;//栈底
void *eip;//CPU通过EIP寄存器读取即将要执行的指令
void *edi;
void *esi;
void *rbx;
void *r1;
void *r2;
void *r3;
void *r4;
void *r5;
} nty_cpu_ctx;
//new_ctx[%rdi]:即将运行协程的上下文寄存器列表; cur_ctx[%rsi]:正在运行协程的上下文寄存器列表
int _switch(nty_cpu_ctx *new_ctx, nty_cpu_ctx *cur_ctx);
//默认x86_64
__asm__(
" .text \n"
" .p2align 4,,15 \n"
".globl _switch \n"
".globl __switch \n"
"_switch: \n"
"__switch: \n"
" movq %rsp, 0(%rsi) # save stack_pointer \n"
" movq %rbp, 8(%rsi) # save frame_pointer \n"
" movq (%rsp), %rax # save insn_pointer \n"
" movq %rax, 16(%rsi) # save eip \n"
" movq %rbx, 24(%rsi) # save rbx,r12-r15 \n"
" movq %r12, 32(%rsi) \n"
" movq %r13, 40(%rsi) \n"
" movq %r14, 48(%rsi) \n"
" movq %r15, 56(%rsi) \n"
" movq 56(%rdi), %r15 \n"
" movq 48(%rdi), %r14 \n"
" movq 40(%rdi), %r13 \n"
" movq 32(%rdi), %r12 \n"
" movq 24(%rdi), %rbx # restore rbx,r12-r15 \n"
" movq 8(%rdi), %rbp # restore frame_pointer \n"
" movq 0(%rdi), %rsp # restore stack_pointer \n"
" movq 16(%rdi), %rax # restore insn_pointer \n"
" movq %rax, (%rsp) \n"
" ret \n"
);三、协程如何定义?
理解了上文,就能大概了解协程这个东西应该拥有哪些变量,也就是如何定义。其中就包括:状态,状态对应的结构(就绪队列,等待队列,超时等待队列),socketfd,CPU上下文,所属调度器(由谁调度),栈等。对应的实现代码如下:
typedef struct _nty_coroutine {
nty_cpu_ctx ctx;
proc_coroutine func;
void *arg;
size_t stack_size;
nty_coroutine_status status;
nty_schedule *sched;
uint64_t birth;
uint64_t id;
void *stack;
RB_ENTRY(_nty_coroutine) sleep_node;
RB_ENTRY(_nty_coroutine) wait_node;
TAILQ_ENTRY(_nty_coroutine) ready_next;
} nty_coroutine;四、调度器是什么,调度器如何定义?
对应调度器应该包括:当前执行协程及其上下文,栈,协程各状态对应的数据结构,epoll句柄,锁(多核场景中多线程场景需要用到)等。对应代码如下:
typedef struct _nty_schedule {
uint64_t birth;
nty_cpu_ctx ctx;
struct _nty_coroutine *curr_thread;
int page_size;
int poller_fd;
int eventfd;
struct epoll_event eventlist[NTY_CO_MAX_EVENTS];
int nevents;
int num_new_events;
nty_coroutine_queue ready;
nty_coroutine_rbtree_sleep sleeping;
nty_coroutine_rbtree_wait waiting;
} nty_schedule;五、调度器的执行策略?
对于调度器的执行策略,可以理解为协程应该如何被调度?即调度器维护的保存协程状态的数据结构中保存的各个协程如何被消费?
其中有两种方案,一种是生产者消费者模式,另一种多状态运行。
5.1 生产者消费者模式
逻辑代码如下:
while (1) {
//遍历睡眠集合,将满足条件的加入到ready
nty_coroutine *expired = NULL;
while ((expired = sleep_tree_expired(sched)) != ) {
TAILQ_ADD(&sched->ready, expired);
}
//遍历等待集合,将满足添加的加入到ready
nty_coroutine *wait = NULL;
int nready = epoll_wait(sched->epfd, events, EVENT_MAX, 1);
for (i = 0;i < nready;i ++) {
wait = wait_tree_search(events[i].data.fd);
TAILQ_ADD(&sched->ready, wait);
}
// 使用resume回复ready的协程运行权
while (!TAILQ_EMPTY(&sched->ready)) {
nty_coroutine *ready = TAILQ_POP(sched->ready);
resume(ready);
}
}这种模式可以理解为:将等待集合和睡眠集合中满足条件的协程放入就绪队列中,最后由就绪队列统一调度。这种更像CPU的调度方式。各种状态先转换为就绪态然后由就绪态转换为运行态,逐个消费就绪队列中的协程。
5.2 多状态运行
逻辑代码如下:
while (1) {
//遍历睡眠集合,使用resume恢复expired的协程运行权
nty_coroutine *expired = NULL;
while ((expired = sleep_tree_expired(sched)) != ) {
resume(expired);
}
//遍历等待集合,使用resume恢复wait的协程运行权
nty_coroutine *wait = NULL;
int nready = epoll_wait(sched->epfd, events, EVENT_MAX, 1);
for (i = 0;i < nready;i ++) {
wait = wait_tree_search(events[i].data.fd);
resume(wait);
}
// 使用resume恢复ready的协程运行权
while (!TAILQ_EMPTY(sched->ready)) {
nty_coroutine *ready = TAILQ_POP(sched->ready);
resume(ready);
}
}这种模式可理解为:直接遍历每个结合,满足执行条件的直接resume,开始执行。也就是可以从多个状态直接转换为运行态。
六、如何与Posix API做到一致?
这个问题,猛地看会感到有点抽象,为啥要和Posix API做到一致?这里的作用,个人理解更多的是方便上层程序调用。也就是方便后续编程。毕竟协程作为一个应用层用户自行封装的代码库,作为一个底层组件,对于上层业务使用人员来说,编程开发使用体验是非常重要的一部分。对于异步IO的实现对于上层调用者来说应该是透明的,他应该感知不到。或者没有太大感触。这里的话可以结合上文对于协程的理解来考虑。
首先我们确定一点,要封装成异步IO,异步IO的封装前提应该是这个API操作是会产生阻塞的。否则根本不会阻塞的API操作就没有异步的必要,如果封装成异步的不就是脱裤子放屁了么....所以针对网络编程而言以下函数是需要封装的:
accept()
connect()
recv()
read()
send()
write()
recvfrom()
sendto()大概封装思路为:利用epoll的事件响应能力,当就绪后被resume后,执行epoll_del,开始处理IO事件。当产生阻塞事件需要让出前执行epoll_add,然后yield让出。代码思路如下:
epoll_ctl(epfd, EPOLL_CTL_ADD, sockfd, NULL);
yield()
epoll_ctl(epfd, EPOLL_CTL_DEL, sockfd, NULL);
recv(sockfd, buffer, length, 0);但是还有另外一种情况,就是如果需要实现协程的应用为mysql或者redis等时,这种方法就不太方便了。因为其实现的源码是使用的底层Posix API,除非你去提前修改mysql client的客户端源码,将其替换为协程实现对应的Posix API。否则上面的方式就不管用了。此时可以利用hook技术。
hook提供了两个接口;1. dlsym()是针对系统的,系统原始的api。2. dlopen()是针对第三方的库。感兴趣的可以继续深入了解dlsym的hook技术实现。
大概的hook机制个人理解为:hook机制提供了hook点,这个hook点在当前场景下就是像accept()调用,recv()调用等。可以在这个hook点注册一个对应的函数,注册完成后,当系统调用执行调用到这个hook点对应的函数后,会执行用户注册的hook函数,此时我们就可以在这个hook函数中实现异步IO操作。对于mysql/redis而言,他们的一系列接口当调用recv时,他不会直接调用系统底层提供的recv,而是被系统拦截到这个调用请求然后转而执行用户定义的函数,后续就可以执行异步的API操作了。
七、协程的多核模式?
对于协程的多核模式,可以理解为多个进程/多个线程中应用协程。
这里就涉及到第一部分说的线程和进程的区别了。他们的内存空间是不同的。自然而言对于多进程而言,协程与单进程/单线程使用方式一样。因为多进程是由底层操作系统提供了天然的隔离性。相互之间互不影响。而多进程他们的内存空间是共享的,此时对于共享数据的使用就需要加锁。
八、协程的性能如何测试?
协程的性能可以参考reactor百万并发测试思路。一个socketfd对应一个协程。测试协程在网络编程场景下的并发量、吞吐量等数据。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









