




 Redis集群采用16384个哈希槽,而非一致性哈希,原因在于心跳包携带槽配置时的效率考虑。16384个槽在2k空间内可压缩表示,且满足大多数集群规模需求。此外,介绍了Hash Tag机制,允许将相关键映射到同一槽,以优化数据分布,但也可能导致数据倾斜。
Redis集群采用16384个哈希槽,而非一致性哈希,原因在于心跳包携带槽配置时的效率考虑。16384个槽在2k空间内可压缩表示,且满足大多数集群规模需求。此外,介绍了Hash Tag机制,允许将相关键映射到同一槽,以优化数据分布,但也可能导致数据倾斜。
为什么哈希槽是16384
Redis 集群并没有使用一致性hash,而是引入了哈希槽的概念。 Redis 集群有16384个哈希槽,每个key通过CRC16校验后对16384取模来决定放置哪个槽,集群的每个节点负责一部分hash槽。 但为什么哈希槽的数量是16384(2^14)个呢?
- 在redis节点发送心跳包时需要把所有的槽放到这个心跳包里,以便让节点知道当前集群信息,16384=16k,在发送心跳包时使用bitmap压缩后是2k( 2 * 8 (8 bit) * 1024 (1k) = 2K ),也就是说使用2k的空间创建了16k的槽数。
github上作者给出的解释:https://github.com/antirez/redis/issues/2576
The reason is:
Normal heartbeat packets carry the full configuration of a node, that
can be replaced in an idempotent way with the old in order to update
an old config. This means they contain the slots configuration for a
node, in raw form, that uses 2k of space with16k slots, but would use
a prohibitive 8k of space using 65k slots. At the same time it is
unlikely that Redis Cluster would scale to more than 1000 mater nodes
because of other design tradeoffs.
So 16k was in the right range to ensure enough slots per master with a max of 1000 maters, but a small enough number to propagate the slot configuration as a raw bitmap easily. Note that in small clusters the bitmap would be hard to compress because when N is small the bitmap would have slots/N bits set that is a large percentage of bits set.、
关于Redis集群节点之间的通信机制,可以参考我的这篇博客:Redis第二十二讲 Redis高可用集群节点通信机制
每当有新的节点加入集群的时候,会发送cluster meet命令
假设要向A节点发送cluster meet命令,将B节点加入到A所在的集群,则A节点收到命令后,执行的操作如下:
-
A为B创建一个clusterNode结构,并将其添加到clusterState的nodes字典中
-
A向B发送MEET消息
-
B收到MEET消息后,会为A创建一个clusterNode结构,并将其添加到clusterState的nodes字典中
-
B回复A一个PONG消息
-
A收到B的PONG消息后,便知道B已经成功接收自己的MEET消息
-
然后,A向B返回一个PING消息
-
B收到A的PING消息后,便知道A已经成功接收自己的PONG消息,握手完成
-
之后,A通过Gossip协议将B的信息广播给集群内其他节点,其他节点也会与B握手;一段时间后,集群收敛,B成为集群内的一个普通节点
在握手成功后,两个节点之间会定期发送ping/pong消息,交换数据信息,如下图所示。
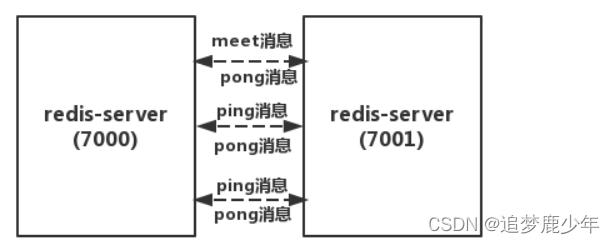
在这里,我们需要关注三个重点。
(1)交换什么数据信息
(2)数据信息究竟多大
(3)定期的频率什么样
- 到底在交换什么数据信息?
交换的数据信息,由消息体和消息头组成。
消息体无外乎是一些节点标识啊,IP啊,端口号啊,发送时间啊。这与本文关系不是太大,我不细说。
我们来看消息头,结构如下:
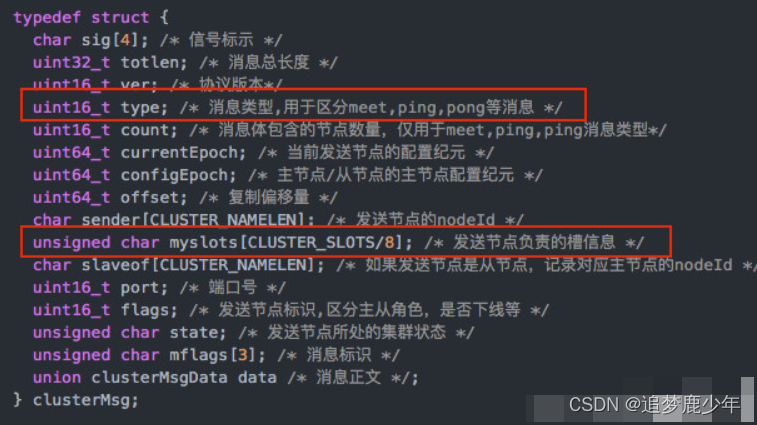
注意看红框的内容,type表示消息类型。
另外,消息头里面有个myslots的char数组,长度为16383/8,这其实是一个bitmap,每一个位代表一个槽,如果该位为1,表示这个槽是属于这个节点的。
-
到底数据信息究竟多大?
在消息头中,最占空间的是myslots[CLUSTER_SLOTS/8]。这块的大小是:
16384÷8÷1024=2kb
那在消息体中,会携带一定数量的其他节点信息用于交换。 -
那这个其他节点的信息,到底是几个节点的信息呢?
约为集群总节点数量的1/10,至少携带3个节点的信息。
这里的重点是:节点数量越多,消息体内容越大。
消息体大小是10个节点的状态信息约1kb。 -
那定期的频率是什么样的?
redis集群内节点,每秒都在发ping消息。规律如下
(1)每秒会随机选取5个节点,找出最久没有通信的节点发送ping消息
(2)每100毫秒(1秒10次)都会扫描本地节点列表,如果发现节点最近一次接受pong消息的时间大于cluster-node-timeout/2 则立刻发送ping消息
因此,每秒单节点发出ping消息数量为total=1+10*num(node.pong_received>cluster_node_timeout/2)
那大致带宽损耗如下所示,图片来自《Redis运维与实现》

为什么槽位是16384的回答
- 如果槽位为65536,发送心跳信息的消息头达8k,发送的心跳包过于庞大。
如上所述,在消息头中,最占空间的是myslots[CLUSTER_SLOTS/8]。
当槽位为65536时,这块的大小是:65536÷8÷1024=8kb
因为每秒钟,redis节点需要发送一定数量的ping消息作为心跳包,如果槽位为65536,这个ping消息的消息头太大了,浪费带宽。 - redis的集群主节点数量基本不可能超过1000个。
如上所述,集群节点越多,心跳包的消息体内携带的数据越多。如果节点过1000个,也会导致网络拥堵。因此redis作者,不建议redis cluster节点数量超过1000个。
那么,对于节点数在1000以内的redis cluster集群,16384个槽位够用了。没有必要拓展到65536个。 - 槽位越小,节点少的情况下,压缩比高
Redis主节点的配置信息中,它所负责的哈希槽是通过一张bitmap的形式来保存的,在传输过程中,会对bitmap进行压缩,但是如果bitmap的填充率slots / N很高的话(N表示节点数),bitmap的压缩率就很低。如果节点数很少,而哈希槽数量很多的话,bitmap的压缩率就很低。
ps:文件压缩率指的是,文件压缩前后的大小比。
综上所述,作者决定取16384个槽,不多不少,刚刚好!
hash tag
当我们提交了一批命令,往Redis中存储一批键,那么这些键一般会被映射到不同的slot,而不同的slot又可能在Redis Cluster中不同的节点上,这样就和的预期有点不同,有没有办法将这批键映射到同一个slot呢?
答案是可以的,可以通过使用hash tag来保证插入的一批数据映射到同一slot(槽点)。
hash tag用于redis集群中。其实现方式为在key中加个{},例如test{1}。使用hash tag后客户端在计算key的crc16时,只计算{}中数据。如果没使用hash tag,客户端会对整个key进行crc16计算;
-
优点
hash tag主要作用是将某一固定特征数据存储到一台实例上,避免逐个查询集群中实例。例如将用户信息与用户订单数量存储到一个实例用于后续展示统计。 -
缺点
可能会导致数据集中在一个实例中,造成数据倾斜,例如将用户1-10000的数据存储在一个实例中,注意不要把key的离散性变得非常差
为了实现哈希标签,哈希槽是用另一种不同的方式计算的。基本来说,如果一个键包含一个 “{…}” 这样的模式,只有 { 和 } 之间的字符串会被用来做哈希以获取哈希槽。但是由于可能出现多个 { 或 },计算的算法如下:
- 如果键包含一个 { 字符。那么在 { 的右边就会有一个 }。
- 在 { 和 } 之间会有一个或多个字符,第一个 } 一定是出现在第一个 { 之后。
然后不是直接计算键的哈希,只有在第一个 { 和它右边第一个 } 之间的内容会被用来计算哈希值。
例子:
-
比如这两个键 {user1000}.following 和 {user1000}.followers 会被哈希到同一个哈希槽里,因为只有 user1000 这个子串会被用来计算哈希值。
-
对于 foo{}{bar} 这个键,整个键都会被用来计算哈希值,因为第一个出现的 { 和它右边第一个出现的 } 之间没有任何字符。
-
对于 foo{bar}{zap} 这个键,用来计算哈希值的是 bar 这个子串,因为算法会在第一次有效或无效(比如中间没有任何字节)地匹配到 { 和 } 的时候停止。
按照这个算法,如果一个键是以 {} 开头的话,那么就当作整个键会被用来计算哈希值。当使用二进制数据做为键名称的时候,这是非常有用的。


















 4809
4809

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











