




 本文详细介绍了Redis中zset的数据结构,包括使用ziplist的条件,以及当元素数量增多时转为skiplist的机制。zset结合了字典与跳表的优点,提供高效查找和范围操作。存储过程中,根据元素数量和大小决定使用ziplist还是skiplist,并解释了添加元素时的处理流程。
本文详细介绍了Redis中zset的数据结构,包括使用ziplist的条件,以及当元素数量增多时转为skiplist的机制。zset结合了字典与跳表的优点,提供高效查找和范围操作。存储过程中,根据元素数量和大小决定使用ziplist还是skiplist,并解释了添加元素时的处理流程。
zset
zset中的每个元素包含数据本身和一个对应的分数(score)。ZSet 为有序的,自动去重的集合数据类型,ZSet 数据结构底层实现为 ziplist+或跳表(skiplist) ,zset的数据本身不允许重复,但是score允许重复。
使用ziplist的条件
- 有序集合保存的元素数量小于128个
- 有序集合保存的所有元素的长度小于64字节
这两个数值是可以通过redis.conf的zset-max-ziplist-entries 和 zset-max-ziplist-value选项 进行修改。
zset-max-ziplist-entries 128 // 元素个数超过128 ,将用skiplist编码
zset-max-ziplist-value 64 // 单个元素大小超过 64 byte, 将用 skiplist编码
数据少时,并且每个元素要么是小整数要么是长度较小的字符串时使用ziplist.
ziplist占用连续内存,每项元素都是(数据+score)的方式连续存储,按照score从小到大排序。ziplist为了节省内存,每个元素占用的空间可以不同,对于大的数据(long long),就多用一些字节来存储,而对于小的数据(short),就少用一些字节来存储。因此查找的时候需要按顺序遍历。ziplist省内存但是查找效率低。
当ziplist作为zset的底层存储结构时候,每个集合元素使用两个紧挨在一起的压缩列表节点来保存,第一个节点保存元素的成员,第二个元素保存元素的分值。
关于ziplist数据结构,可以参考我之前在list底层结构实现里的文章:Redis第六讲 Redis之List底层数据结构实现
zset数据结构
数据多时,使用字典+跳表:跳表是基于一条有序单链表构造的,通过构建索引提高查找效率,空间换时间,查找方式是从最上面的链表层层往下查找,最后在最底层的链表找到对应的节点:
typedef struct zset{
zskiplist *zsl; //跳跃表 按分值排序成员 用于支持平均复杂度为 O(log N) 的按分值定位成员操作以及范围操作
dict *dice; //字典 键为成员,值为分值 用于支持 O(1) 复杂度的按成员取分值操作
} zset;
当skiplist作为zset的底层存储结构的时候,使用skiplist按序保存元素及分值,使用dict来保存元素和分值的映射关系。
skiplist作为zset的存储结构,整体存储结构如下图,核心点主要是包括一个dict对象和一个skiplist对象。dict保存key/value,key为元素,value为分值;skiplist保存的有序的元素列表,每个元素包括元素和分值。两种数据结构下的元素指向相同的位置。
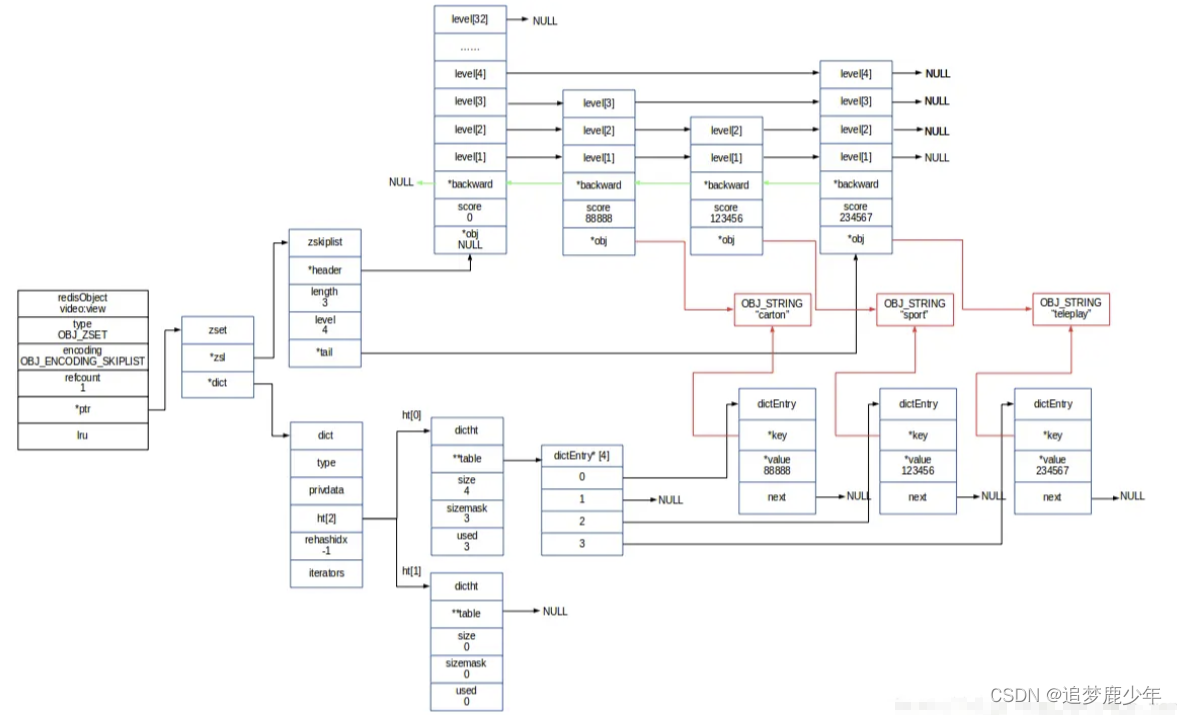
skiplist
zset包括dict和zskiplist两个数据结构,其中dict的保存key/value,便于通过key(元素)获取score(分值)。zskiplist保存有序的元素列表,便于执行range之类的命令。
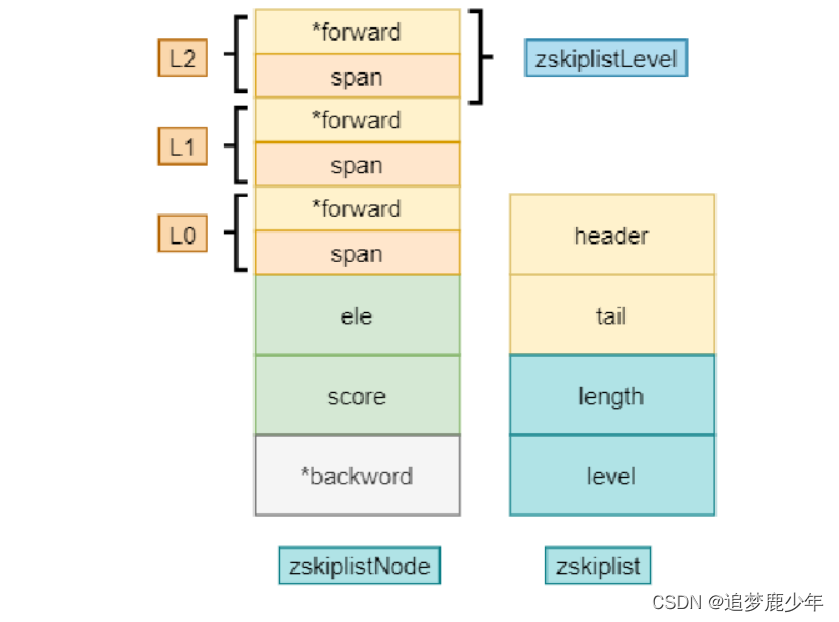
zskiplist作为skiplist的数据结构,包括指向头尾的header和tail指针,其中level保存的是skiplist的最大的层数。
/*
* 跳跃表
*/
typedef struct zskiplist {
struct zskiplistNode *header, *tail;// 表头节点和表尾节
unsigned long length; // 表中节点的数量
int level; // 表中层数最大的节点的层数
} zskiplist;
skiplist跳跃列表中每个节点的数据格式,每个节点有保存数据的robj指针,分值score字段,后退指针backward便于回溯,zskiplistLevel的数组保存跳跃列表每层的指针。
/*
* 跳跃表节点
*/
typedef struct zskiplistNode {
robj *obj; // 成员对象
double score; // 分值
struct zskiplistNode *backward; // 后退指针
struct zskiplistLevel { // 层
struct zskiplistNode *forward; // 前进指针
unsigned int span; // 跨度
} level[];
} zskiplistNode;
其实有序集合单独使用字典或跳跃表其中一种数据结构都可以实现,但是这里使用两种数据结构组合起来,原因是假如我们单独使用 字典,虽然能以 O(1) 的时间复杂度查找成员的分值,但是因为字典是以无序的方式来保存集合元素,所以每次进行范围操作的时候都要进行排序;假如我们单独使用跳跃表来实现,虽然能执行范围操作,但是查找操作有 O(1)的复杂度变为了O(logN)。因此Redis使用了两种数据结构来共同实现有序集合。
// 创建zset 数据结构: 字典 + 跳表
robj *createZsetObject(void) {
zset *zs = zmalloc(sizeof(*zs));
robj *o;
// dict用来查询数据到分数的对应关系, 如 zscore 就可以直接根据 元素拿到分值
zs->dict = dictCreate(&zsetDictType,NULL);
// skiplist用来根据分数查询数据(可能是范围查找)
zs->zsl = zslCreate();
// 设置对象类型
o = createObject(OBJ_ZSET,zs);
// 设置编码类型
o->encoding = OBJ_ENCODING_SKIPLIST;
return o;
}
zset存储过程
zset的添加过程我们以zadd的操作作为例子进行分析,整个过程如下:
- 解析参数得到每个元素及其对应的分值
- 查找key对应的zset是否存在不存在则创建
- 如果存储格式是ziplist,那么在执行添加的过程中我们需要区分元素存在和不存在两种情况,存在情况下先删除后添加;不存在情况下则添加并且需要考虑元素的长度是否超出限制或实际已有的元素个数是否超过最大限制进而决定是否转为skiplist对象。
- 如果存储格式是skiplist,那么在执行添加的过程中我们需要区分元素存在和不存在两种情况,存在的情况下先删除后添加,不存在情况下那么就直接添加,在skiplist当中添加完以后我们同时需要更新dict的对象
void zaddGenericCommand(redisClient *c, int incr) {
static char *nanerr = "resulting score is not a number (NaN)";
robj *key = c->argv[1];
robj *ele;
robj *zobj;
robj *curobj;
double score = 0, *scores = NULL, curscore = 0.0;
int j, elements = (c->argc-2)/2;
int added = 0, updated = 0;
// 输入的 score - member 参数必须是成对出现的
if (c->argc % 2) {
addReply(c,shared.syntaxerr);
return;
}
// 取出所有输入的 score 分值
scores = zmalloc(sizeof(double)*elements);
for (j = 0; j < elements; j++) {
if (getDoubleFromObjectOrReply(c,c->argv[2+j*2],&scores[j],NULL)
!= REDIS_OK) goto cleanup;
}
// 取出有序集合对象
zobj = lookupKeyWrite(c->db,key);
if (zobj == NULL) {
// 有序集合不存在,创建新有序集合
if (server.zset_max_ziplist_entries == 0 ||
server.zset_max_ziplist_value < sdslen(c->argv[3]->ptr))
{
zobj = createZsetObject();
} else {
zobj = createZsetZiplistObject();
}
// 关联对象到数据库
dbAdd(c->db,key,zobj);
} else {
// 对象存在,检查类型
if (zobj->type != REDIS_ZSET) {
addReply(c,shared.wrongtypeerr);
goto cleanup;
}
}
// 处理所有元素
for (j = 0; j < elements; j++) {
score = scores[j];
// 有序集合为 ziplist 编码
if (zobj->encoding == REDIS_ENCODING_ZIPLIST) {
unsigned char *eptr;
// 查找成员
ele = c->argv[3+j*2];
if ((eptr = zzlFind(zobj->ptr,ele,&curscore)) != NULL) {
// 成员已存在
// ZINCRYBY 命令时使用
if (incr) {
score += curscore;
if (isnan(score)) {
addReplyError(c,nanerr);
goto cleanup;
}
}
// 执行 ZINCRYBY 命令时,
// 或者用户通过 ZADD 修改成员的分值时执行
if (score != curscore) {
// 删除已有元素
zobj->ptr = zzlDelete(zobj->ptr,eptr);
// 重新插入元素
zobj->ptr = zzlInsert(zobj->ptr,ele,score);
// 计数器
server.dirty++;
updated++;
}
} else {
// 元素不存在,直接添加
zobj->ptr = zzlInsert(zobj->ptr,ele,score);
// 查看元素的数量,
// 看是否需要将 ZIPLIST 编码转换为有序集合
if (zzlLength(zobj->ptr) > server.zset_max_ziplist_entries)
zsetConvert(zobj,REDIS_ENCODING_SKIPLIST);
// 查看新添加元素的长度
// 看是否需要将 ZIPLIST 编码转换为有序集合
if (sdslen(ele->ptr) > server.zset_max_ziplist_value)
zsetConvert(zobj,REDIS_ENCODING_SKIPLIST);
server.dirty++;
added++;
}
// 有序集合为 SKIPLIST 编码
} else if (zobj->encoding == REDIS_ENCODING_SKIPLIST) {
zset *zs = zobj->ptr;
zskiplistNode *znode;
dictEntry *de;
// 编码对象
ele = c->argv[3+j*2] = tryObjectEncoding(c->argv[3+j*2]);
// 查看成员是否存在
de = dictFind(zs->dict,ele);
if (de != NULL) {
// 成员存在
// 取出成员
curobj = dictGetKey(de);
// 取出分值
curscore = *(double*)dictGetVal(de);
// ZINCRYBY 时执行
if (incr) {
score += curscore;
if (isnan(score)) {
addReplyError(c,nanerr);
goto cleanup;
}
}
// 执行 ZINCRYBY 命令时,
// 或者用户通过 ZADD 修改成员的分值时执行
if (score != curscore) {
// 删除原有元素
redisAssertWithInfo(c,curobj,zslDelete(zs->zsl,curscore,curobj));
// 重新插入元素
znode = zslInsert(zs->zsl,score,curobj);
incrRefCount(curobj); /* Re-inserted in skiplist. */
// 更新字典的分值指针
dictGetVal(de) = &znode->score; /* Update score ptr. */
server.dirty++;
updated++;
}
} else {
// 元素不存在,直接添加到跳跃表
znode = zslInsert(zs->zsl,score,ele);
incrRefCount(ele); /* Inserted in skiplist. */
// 将元素关联到字典
redisAssertWithInfo(c,NULL,dictAdd(zs->dict,ele,&znode->score) == DICT_OK);
incrRefCount(ele); /* Added to dictionary. */
server.dirty++;
added++;
}
} else {
redisPanic("Unknown sorted set encoding");
}
}
if (incr) /* ZINCRBY */
addReplyDouble(c,score);
else /* ZADD */
addReplyLongLong(c,added);
cleanup:
zfree(scores);
if (added || updated) {
signalModifiedKey(c->db,key);
notifyKeyspaceEvent(REDIS_NOTIFY_ZSET,
incr ? "zincr" : "zadd", key, c->db->id);
}
}


















 858
858

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











