




 本文详细介绍了Zookeeper集群中Leader选举的过程,包括集群启动时及Leader断连后的选举流程,并解释了投票选举的具体规则。
本文详细介绍了Zookeeper集群中Leader选举的过程,包括集群启动时及Leader断连后的选举流程,并解释了投票选举的具体规则。
学习过Zookeeper的伙伴们都知道,Zookeeper在集群启动以及崩溃恢复时都会进行投票选举Leader结点,来确定集群中服务器的职责。
在集群启动过程中的 Leader 选举过程(算法)与 Leader 断连后的 Leader 选举过程稍微有一些区别,基本相同。
投票选举流程
在开始讲解Zookeeper投票选举机制之前,先看下选举中的几个状态:
zk 集群中的每一台主机,在不同的阶段会处于不同的状态。每一台主机具有四种状态。
LOOKING FOLLOWING OBSERVING LEADING
Zookeeper投票选举的流程图大致如下:
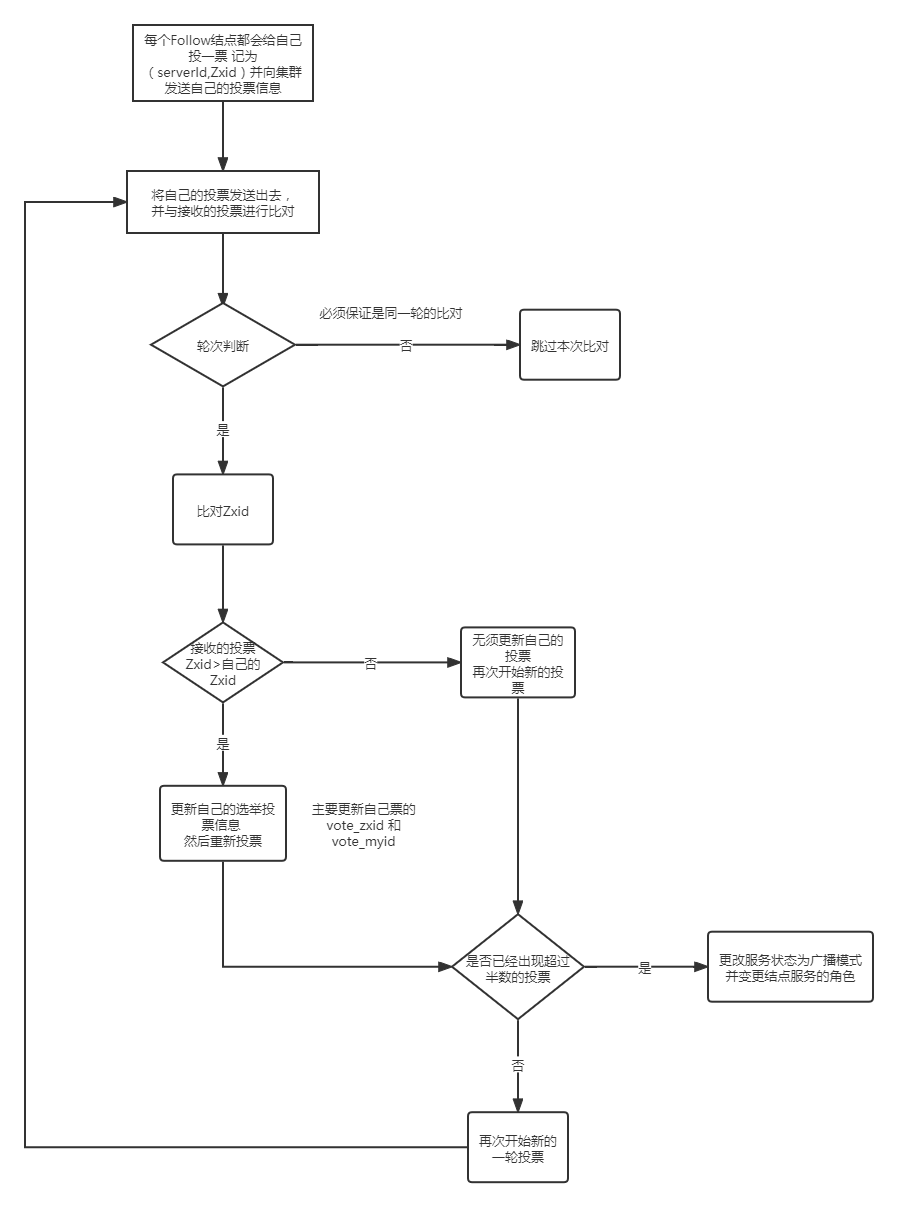
集群启动时的投票选举
若进行 Leader 选举,则至少需要两台主机,这里以三台主机组成的集群为例。 在集群初始化阶段,当第一台服务器 Server1 启动时,其会给自己投票,然后发布自己的投票结果。投票包含所推举的服务器的 myid 和 ZXID,使用(myid, ZXID)来表示,此时 Server1 的投票为(1, 0)。由于其它机器还没有启动所以它收不到反馈信息,Server1 的状态一直属于 Looking,即属于非服务状态
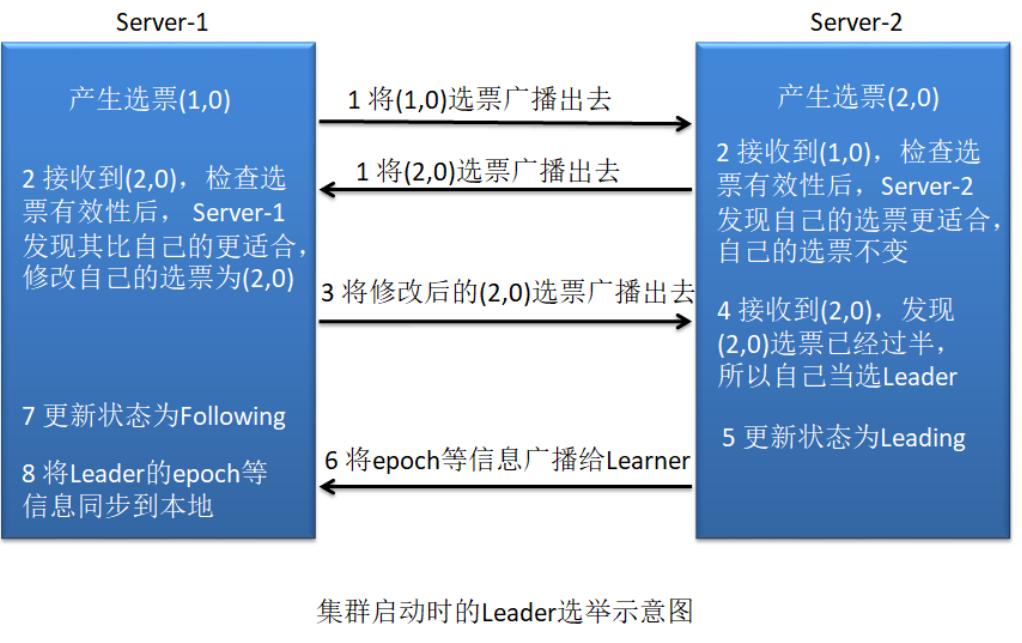
当第二台服务器 Server2 启动时,此时两台机器可以相互通信,每台机器都试图找到Leader,选举过程如下:
(1) 每个 Server 发出一个投票。此时 Server1 的投票为(1, 0),Server2 的投票为(2, 0),然后各自将这个投票发给集群中其他机器。
(2) 接受来自各个服务器的投票。集群的每个服务器收到投票后,首先判断该投票的有效性,如检查是否是本轮投票、是否来自 LOOKING 状态的服务器。
(3) 处理投票。针对每一个投票,服务器都需要将别人的投票和自己的投票进行 PK,PK规则如下:
优先检查 ZXID。ZXID 比较大的服务器优先作为 Leader。
如果 ZXID 相同,那么就比较 myid。myid 较大的服务器作为 Leader 服务器。
对于 Server1 而言,它的投票是(1, 0),接收 Server2 的投票为(2, 0)。其首先会比较两者 的 ZXID,均为 0,再比较 myid,此时 Server2 的 myid 最大,于是 Server1 更新自己的投票为 (2, 0),然后重新投票。对于 Server2 而言,其无须更新自己的投票,只是再次向集群中所有 主机发出上一次投票信息即可。
(4) 统计投票。每次投票后,服务器都会统计投票信息,判断是否已经有过半机器接受到 相同的投票信息。对于 Server1、Server2 而言,都统计出集群中已经有两台主机接受了(2, 0) 的投票信息,此时便认为已经选出了新的 Leader,即 Server2。
(5) 改变服务器状态。一旦确定了 Leader,每个服务器就会更新自己的状态,如果是 Follower,那么就变更为 FOLLOWING,如果是 Leader,就变更为 LEADING。
(6) 添加主机。在新的 Leader 选举出来后 Server3 启动,其想发出新一轮的选举。但由于 当前集群中各个主机的状态并不是 LOOKING,而是各司其职的正常服务,所以其只能是以 Follower 的身份加入到集群中。
断连后的 Leader 选举
在 Zookeeper 运行期间,Leader 与非 Leader 服务器各司其职,即便当有非 Leader 服务器宕机或新加入时也不会影响 Leader。但是若 Leader 服务器挂了,那么整个集群将暂停对外服务,进入新一轮的 Leader 选举,其过程和启动时期的 Leader 选举过程基本一致。
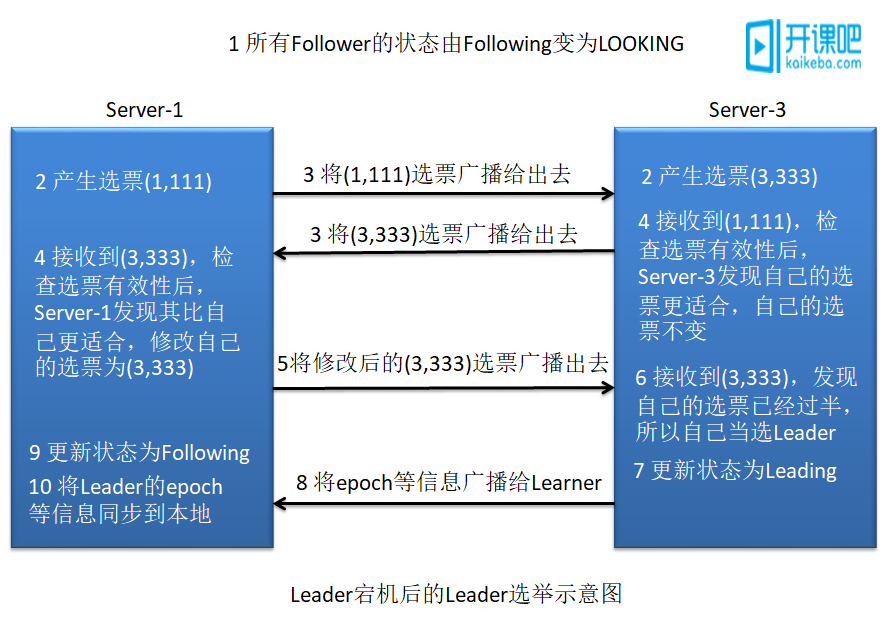
假设正在运行的有 Server1、Server2、Server3 三台服务器,当前 Leader 是 Server2,若 某一时刻 Server2 挂了,此时便开始新一轮的 Leader 选举了。选举过程如下:
(1) 变更状态。Leader 挂后,余下的非 Observer 服务器都会将自己的服务器状态由FOLLOWING 变更为 LOOKING,然后开始进入 Leader 选举过程。
(2) 每个 Server 会发出一个投票,仍然会首先投自己。不过,在运行期间每个服务器上 的 ZXID 可能是不同,此时假定 Server1 的 ZXID 为 111,Server3 的 ZXID 为 333;在第一轮投 票中,Server1 和 Server3 都会投自己,产生投票(1, 111),(3, 333),然后各自将投票发送给 集群中所有机器。
(3) 接收来自各个服务器的投票。与启动时过程相同。集群的每个服务器收到投票后, 首先判断该投票的有效性,如检查是否是本轮投票、是否来自 LOOKING 状态的服务器。
(4) 处理投票。与启动时过程相同。针对每一个投票,服务器都需要将别人的投票和自 己的投票进行 PK。对于 Server1 而言,它的投票是(1, 111),接收 Server3 的投票为(3, 333)。 其首先会比较两者的 ZXID,Server3 投票的 zxid 为 333 大于 Server1 投票的 zxid 的 111,于是 Server1 更新自己的投票为(3, 333),然后重新投票。对于 Server3 而言,其无须更新自己的投 票,只是再次向集群中所有主机发出上一次投票信息即可。
(5) 统计投票。与启动时过程相同。对于 Server1、Server2 而言,都统计出集群中已经 有两台主机接受了(3, 333)的投票信息,此时便认为已经选出了新的 Leader,即 Server3。
(6) 改变服务器的状态。与启动时过程相同。一旦确定了 Leader,每个服务器就会更新 自己的状态。Server1 变更为 FOLLOWING,Server3 变更为 LEADING。


















 2480
2480

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











