







 本文介绍了如何通过Python调用OpenAI的ChatGPTAPI和GPT-3.5Turbo模型,展示了一种基于上下文提问的方法。GPT-3.5模型相比GPT-3成本更低且响应更快,支持在对话中记住历史信息。此外,文中提供了代码示例,帮助用户理解如何实现与AI的多轮对话,并分享了相关项目的链接和资源。
本文介绍了如何通过Python调用OpenAI的ChatGPTAPI和GPT-3.5Turbo模型,展示了一种基于上下文提问的方法。GPT-3.5模型相比GPT-3成本更低且响应更快,支持在对话中记住历史信息。此外,文中提供了代码示例,帮助用户理解如何实现与AI的多轮对话,并分享了相关项目的链接和资源。
作者:虚坏叔叔
博客:https://xuhss.com
早餐店不会开到晚上,想吃的人早就来了!😄
一、ChatGPT官方文档介绍:

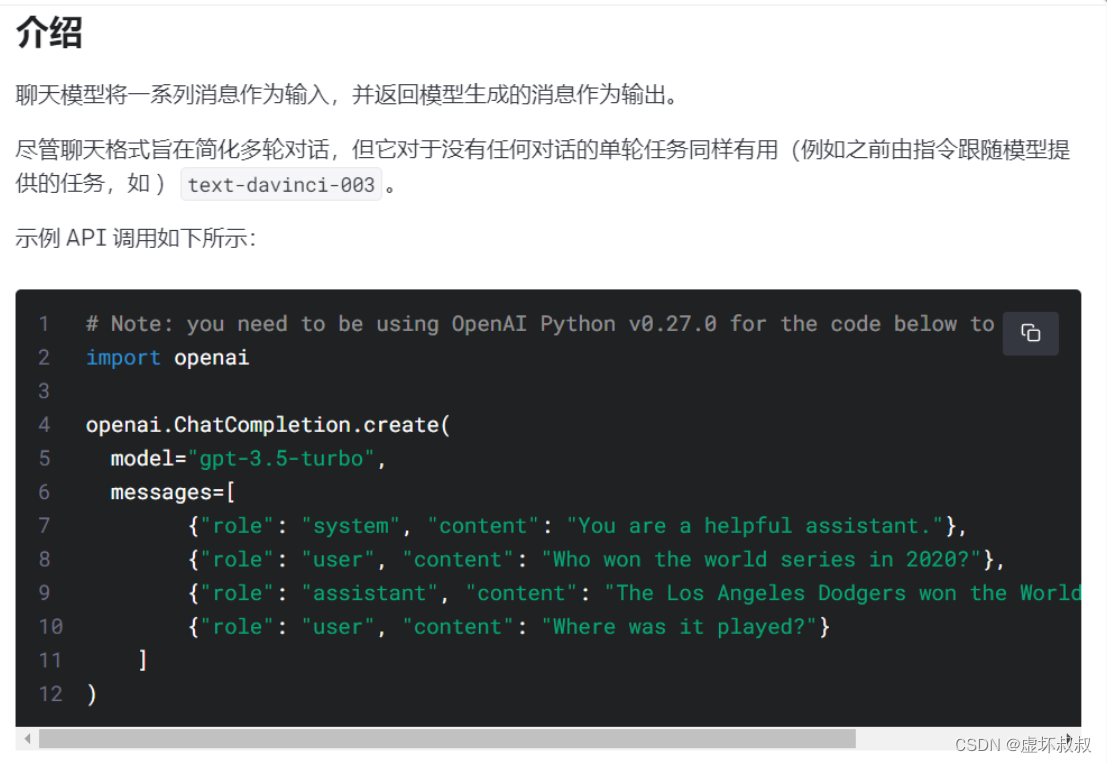
- ChatGPT API—0.002美元,1000个token。
- 比之前的GPT-3.0,成本直接降低了90%。
- Whisper API—0.001美元,10秒语音转录
- 基于gpt-3.5-turbo模型,在微软Azure上运行
- 大客户(每天超过4.5亿个token)选择专用实例更实惠
- 默认情况下,提交的数据不再用于AI训练
messages中的centent就是我们要提问的问题,可以看到chatgpt已经支持基于上一个问题进行提问了
二、Python调用具体方法:
1.升级openai模块

2.导入openai模块

3.Python调用gpt-3.5模型代码
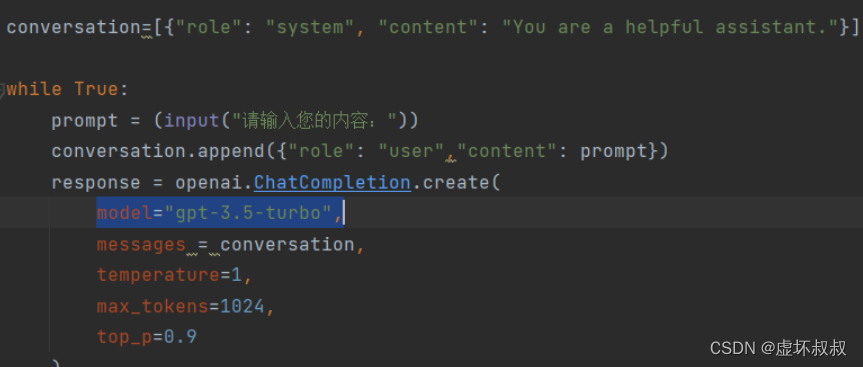
4.完整代码:让chatgpt基于上下文回答
import openai
openai.api_key = "填写你的openai key"
conversation=[{"role": "system", "content": "You are a helpful assistant."}]
while True:
prompt = (input("请输入您的内容:"))
conversation.append({"role": "user","content": prompt})
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages = conversation,
temperature=1,
max_tokens=2048,
top_p=0.9
)
conversation.append({"role": "assistant", "content": response['choices'][0]['message']['content']}) #将上一次会话信息返回给chatgpt
print("\n" + response['choices'][0]['message']['content'] + "\n") #打印答案
5.拓展:让chatgpt记忆第一句话,并基于上下文回答(推荐)
import openai
openai.api_key = "填写你的openai key"
conversation=[{"role": "system", "content": "You are a helpful assistant."}]
max_history_len = 5 #保存5个会话给chatgpt
first_message = None
while True:
prompt = (input("请输入您的内容:"))
if first_message is None:
first_message = prompt # 存储第一句话
conversation.append({"role": "user","content": prompt})
prompt_history = "\n".join([f"{i['role']}: {i['content']}" for i in conversation])
prompt = f"Conversation history:\n{first_message}\n{prompt_history}"
if len(conversation) > max_history_len:
conversation = conversation[-max_history_len:]
# 将第一句话添加到生成的 prompt 中
conversation.insert(0, {"role": "user", "content": first_message})
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages = conversation,
temperature=1,
max_tokens=1024,
n=1,
timeout=15,
stop=None,
top_p=0.9
)
conversation.append({"role": "assistant", "content": response['choices'][0]['message']['content']})
print("\n" + response['choices'][0]['message']['content'] + "\n")
三、GPT-3.5跟ChatGPT网页版用的都是同一个模型
1、GPT-3.5模型比GPT3更便宜
2、GPT-3.5模型比GPT3响应速度快了接近一倍多
3、GPT-3.5可以基于上一个问题来提问
4、GPT-3.5模型的答案更完美
总结
最后的最后
由本人水平所限,难免有错误以及不足之处, 屏幕前的靓仔靓女们 如有发现,恳请指出!
最后,谢谢你看到这里,谢谢你认真对待我的努力,希望这篇博客对你有所帮助!
你轻轻地点了个赞,那将在我的心里世界增添一颗明亮而耀眼的星!
💬 往期优质文章分享
- C++ QT结合FFmpeg实战开发视频播放器-01环境的安装和项目部署
- 解决QT问题:运行qmake:Project ERROR: Cannot run compiler ‘cl‘. Output:
- 解决安装QT后MSVC2015 64bit配置无编译器和调试器问题
- Qt中的套件提示no complier set in kit和no debugger,出现黄色感叹号问题解决(MSVC2017)
- Python+selenium 自动化 - 实现自动导入、上传外部文件(不弹出windows窗口)
🚀 优质教程分享 🚀
- 🎄如果感觉文章看完了不过瘾,可以来我的其他 专栏 看一下哦~
- 🎄比如以下几个专栏:Python实战微信订餐小程序、Python量化交易实战、C++ QT实战类项目 和 算法学习专栏
- 🎄可以学习更多的关于C++/Python的相关内容哦!直接点击下面颜色字体就可以跳转啦!
| 学习路线指引(点击解锁) | 知识定位 | 人群定位 |
|---|---|---|
| 🧡 Python实战微信订餐小程序 🧡 | 进阶级 | 本课程是python flask+微信小程序的完美结合,从项目搭建到腾讯云部署上线,打造一个全栈订餐系统。 |
| 💛Python量化交易实战 💛 | 入门级 | 手把手带你打造一个易扩展、更安全、效率更高的量化交易系统 |
| ❤️ C++ QT结合FFmpeg实战开发视频播放器❤️ | 难度偏高 | 分享学习QT成品的视频播放器源码,需要有扎实的C++知识! |
| 💚 游戏爱好者九万人社区💚 | 互助/吹水 | 九万人游戏爱好者社区,聊天互助,白嫖奖品 |
| 💙 Python零基础到入门 💙 | Python初学者 | 针对没有经过系统学习的小伙伴,核心目的就是让我们能够快速学习Python的知识以达到入门 |
🚀 资料白嫖,温馨提示 🚀
关注下面卡片即刻获取更多编程知识,包括各种语言学习资料,上千套PPT模板和各种游戏源码素材等等资料。更多内容可自行查看哦!



















 2257
2257

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











