



 本文详细介绍了Ceph RGW的数据同步流程,包括全量同步和增量同步的过程,并对比了亚马逊云中Bucket的跨区域备份机制。还提供了S3命令同步及文件复制的具体用法。
本文详细介绍了Ceph RGW的数据同步流程,包括全量同步和增量同步的过程,并对比了亚马逊云中Bucket的跨区域备份机制。还提供了S3命令同步及文件复制的具体用法。
1. c创建bucket à(元数据是否同步到对端?)—>disableà(已同步的元数据是否还在)—>写数据(数据是否同步到对端)àenable(刚才写入的数据是否同步到对端了)àdisable(写入的数据还在对端?)
结果:rados ls -p second.rgw.meta --namespace root 两端可以看到由新建的bucket信息—>再次执行命令两端可以看到由新建的bucket信息-à写入的数据没有同步到对端,在对端bucket list看不到写入的文件且bucket stats的usage是空的à刚才写的数据同步到对端了且bucket list/stats正常à数据还在对端且bucket list/stats正常
2. 2个线程用于sync : BucketsSyncThread ,UserSyncThread
rgw data sync同步过程:
full sync(per shard):
1. 依次处理这个shard里的bucket:
(1)读出bucket的marker
(2)同步每个object,对于同步失败的object会被记录在replica log,之后会尝试sync
(3)同步完成后把bucket_name,bucket_marker,需要重试sync的object列表存入目的ceph的replica log里
2. 这个shard里的bucket都处理完后:
(1) 把shard_num,需要重试sync的bucket列表更新到目的ceph的replica log里
incremental sync:
1. 查看replica log里的各个datalog shard找到需要重试sync的bucket,获取bucket 当前marker
2. 通过读取datalog shard找到有变化的bucket
3. 依次处理各个bucket:
(1) 从replica log中需要重试sync的object
(2) 读取bucket的bilog ,起点是replica log读出的marker
(3) 开始同步object
(4) 更新已经同步了的最新marker和需要再次尝试sync的object列表到replica log
4. 各个bucket处理完成后:
(1) 生成新marker并把需要再次尝试sync的bucket列表更新到replica log
1. 亚马逊云:bucket跨区域备份:
(1) 源/目标bucket开启versioning
(2) 对源bucket全部备份或者选择备份指定前缀的文件
(3) 目标bucket必须由可以访问源的对象列表权限
(4) 可在目标bucket上设置lifecycle来管理删除旧版本
(5) 只能在不同的region里使用(对应12版本的zonegroup?)
(6) 可监视源bucket上的对象变化,因此只能备份新文件,需要复制已有对象可使用copy功能
2. S3同一个集群内的bucket 复制(桶名后面要加/)
s3cmd sync s3://from/this/bucket/ s3://to/this/bucket/
s3cmd sync -r -v --dry-run --delete-removed s3://cos-test-private-bucket/./
s3cmd sync -r -v --dry-run --delete-removed ./ s3://ft-cos-test-private-bucket/
aws s3 sync s3://mybucket s3://backup-mybucket
3. 把bucket1的文件拷贝到bucket2中
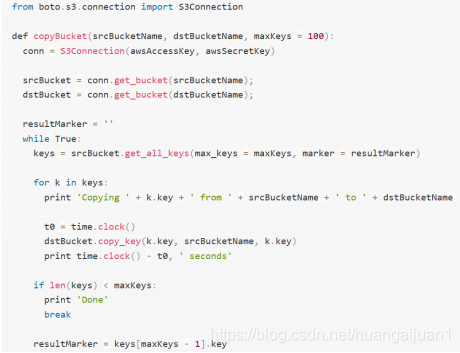
1. 同步/home/sen/tmp 文件到bucket里(只同步有差异的文件):
s3cmd sync /home/sen/tmp s3://slboat/tmp
加 "--dry-run"参数后,仅列出需要同步的项目,不实际进行同步
加 " --delete-removed"参数后,会在bucket里删除本地不存在的文件
加 " --skip-existing"参数后,不进行MD5校验,bucket里直接跳过本地已存在的文件
为了保持保留文件属性,如日期/时间等使用 -p 或 -preserve 参数
排除、包含规则(--exclude 、--include)
ch

















 2486
2486

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









