




 本文介绍了数据库事务的特征,包括原子性、一致性、隔离性和持久性,并探讨了事务并发可能导致的脏读、幻读和不可重复读问题。文章详细讲解了事务隔离级别及其对数据一致性的解决方案,如读未提交、读已提交、可重复读和序列化。重点阐述了MVCC(多版本并发控制)的概念,解释了其在InnoDB中的实现,以及如何通过ReadView和undo日志保证读一致性。MVCC通过生成数据快照避免锁定,从而提高并发性能。
本文介绍了数据库事务的特征,包括原子性、一致性、隔离性和持久性,并探讨了事务并发可能导致的脏读、幻读和不可重复读问题。文章详细讲解了事务隔离级别及其对数据一致性的解决方案,如读未提交、读已提交、可重复读和序列化。重点阐述了MVCC(多版本并发控制)的概念,解释了其在InnoDB中的实现,以及如何通过ReadView和undo日志保证读一致性。MVCC通过生成数据快照避免锁定,从而提高并发性能。
1、事务的特征以及事务并发造成的问题
2、事务读取一致性问题的解决方案
3、举例浅谈mvcc的原理
事务的特征以及事务并发造成的问题:
什么是事务:
定义:事务是数据库管理系统(DBMS)执行过程中的一个逻辑单位,由一个有限的数据库操作序列构成。
个人理解:通俗点说就是Navicat中打开的一个查询页面,就是一个事务,执行查询要么全部成功,要么全部失败。严谨点就是,mysql事务是一组原子性的SQL查询,或者说一个独立的工作单元,事务内的语句,要么全部执行成功,要么全部执行失败。它是一个逻辑单位,整体不能分割。
事务的典型场景:
一般来说数据库的事务类似类似代码中多线程。遇到有关数据变动操作时,在代码中使用事务注解,开启事务,实现拦截。再具体些的场景好比订单系统中操作,订单,物流的信息都需要在一个事务中完成,以免造成数据由多条请求操作,导致数据不准确。
支持事务的搜索引擎:
(1)InnoDB,由于其支持事务,所以也是默认搜索引擎
(2)NDB,支持集群的搜索引擎
事务的四大特性:
l 原子性(Atomicity) [ˌætəˈmɪsɪti] undo log
l 一致性(Consistent) [kənˈsɪstənt]
l 隔离性(Isolation) [ˌaɪsəˈleɪʃn]
事务如何开启与关闭:
事务读取一致性问题的解决方案:
参考http://www.contrib.andrew.cmu.edu/~shadow/sql/sql1992.txt,网页中中搜 "_iso",其中p1,p2,p3问题就是这三个问题:

详细来看下这三个问题:
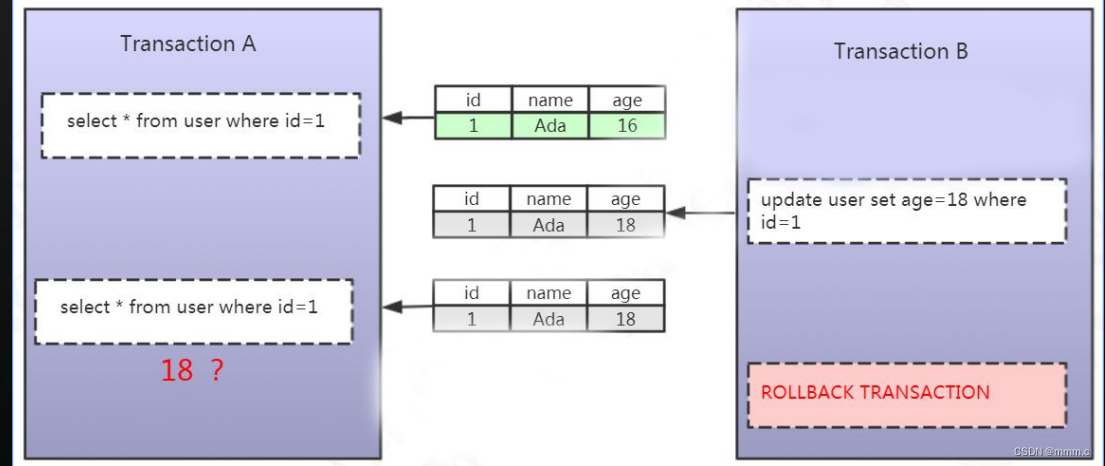
脏读:就是一个事务读到另一个事务没有提交的数据。事务B修改了一个数据,但未提交,事务A读到了事务B未提交的更新结果,事务A读到的就是脏数据。如下图示意
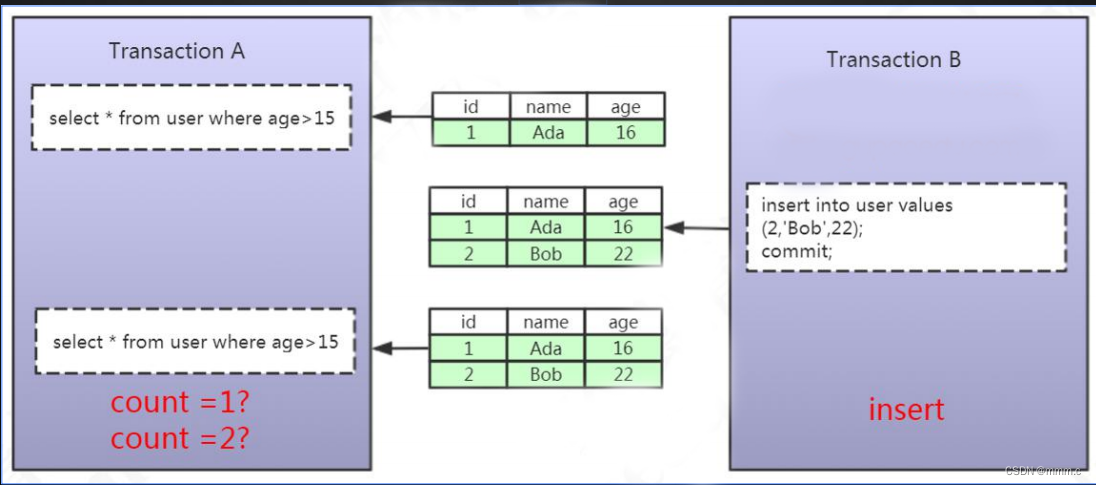
幻读:就是一个事务读到另一个事务新增加并提交的数据(insert)。在同一个事务中,对于同一组数据读取到的结果不一致。比如,事务B新增了一条记录,事务A 在 事务B提交前后各执行了一次查询操作,发现后一次比前一次多了一条记录。幻读出现的原因就是由于事务并发新增记录而导致的。(仅限更新和删除操作)如下图示意
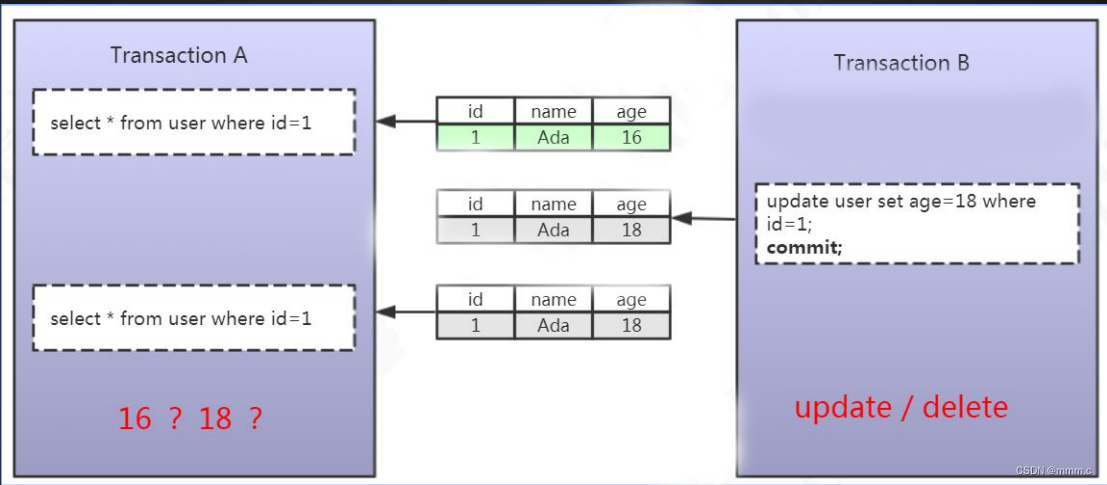
不可重复读: 就是一个事务读到另一个事务修改后并提交的数据(update)。在同一个事务中,对于同一组数据读取到的结果不一致。比如,事务A 在 事务B 提交前读到的结果,和在 事务B 提交后读到的结果可能不同。不可重复读出现的原因就是由于事务并发修改记录而导致的。读取了其他事务提交的数据(仅限插入操作)如下图示意
事务并发三大问题都是数据库读一致性问题,由数据库提供的事务隔离机制来解决。
由此可以引入事务隔离级别这个概念:
事务的隔离级别有四种,从低到高分别是:读未提交、读已提交、可重复读、序列化。
读未提交: Read Uncommitted,顾名思义,就是一个事务可以读取另一个未提交事务的数据。最低级别,它存在4个常见问题(脏读、不可重复读、幻读、丢失更新)。
读已提交: Read Committed,顾名思义,就是一个事务要等另一个事务提交后才能读取数据。 它解决了脏读问题,存在3个常见问题(不可重复读、幻读、丢失更新)。
可重复读: Repeatable Read,就是在开始读取数据(事务开启)时,不再允许修改操作 。它解决了脏读和不可重复读,还存在2个常见问题(幻读、丢失更新)。
序列化: Serializable,序列化,或串行化。就是将每个事务按一定的顺序去执行,它将隔离问题全部解决,但是这种事务隔离级别效率低下,比较耗数据库性能,一般不使用。
越高的隔离级别,能解决的数据一致性问题越多,但同时也会带来性能损耗、降低并发性。
还是上面那个网站中,贴出了事务隔离机制对数据一致性三大问题的解决程度:
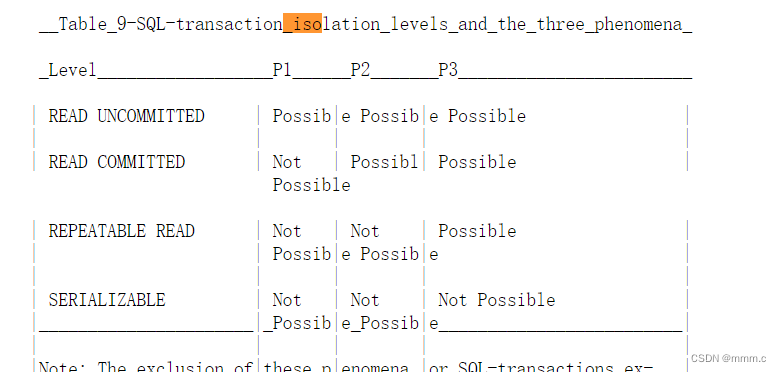
翻译过来看下具体说了什么:
上述的事务隔离级别对解决事务并发三大问题的效果如下表,可能就是未解决,不可能就是已解决。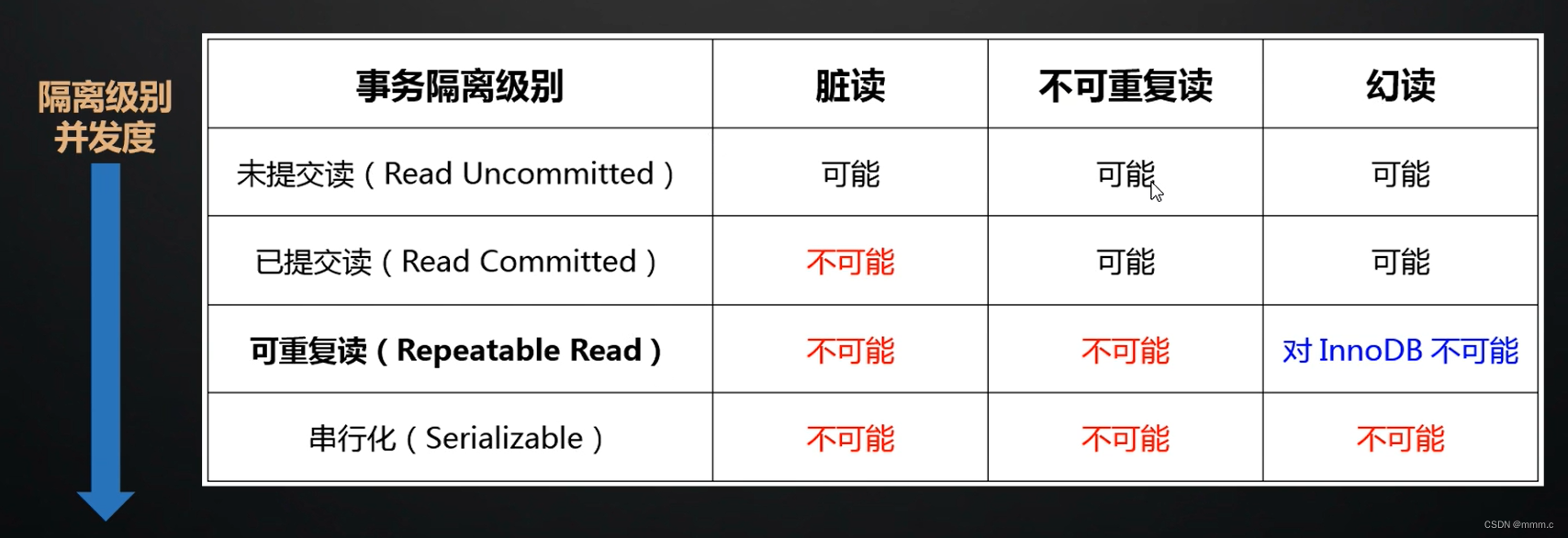
查看会话隔离级别(5.0以上版本):select @@tx_isolation;
查看会话隔离级别(8.0以上版本):select @@transaction_isolation;

InnoDB的mvcc(Multi-Version Concurrency Control)逻辑:
暂时放下lbcc,我们来看看MVCC。
MVCC 的目的就是多版本并发控制,在数据库中的实现,就是为了解决读写冲突,它的实现原理主要是依赖记录中的 3个隐式字段,undo日志 ,Read View 来实现的。

在这里插入图片描述DB_ROW_ID 是数据库默认为该行记录生成的唯一隐式主键,DB_TRX_ID 是当前操作该记录的事务 ID ,而 DB_ROLL_PTR 是一个回滚指针,用于配合 undo日志,指向上一个旧版本 。
1.上面说到,mvcc是为数据生成一个readView,快照,我们可以理解为一个备份,这些插入更新删除等操作出来的备份存放在undolog日志中,以后每次访问都是来针对这个备份。
2.具体实现时依据一条规则:只能查找创建时间小于等于当前事务ID的数据,和删除时间大于当前事务ID的行(或未删除)
举例来看:
我有一条数据,id:1,name:吴彦祖。DB_TRX_ID版本为null
| id | name | DB_TRX_ID | DB_ROLL_PTR | 原始数据 |
| 1 | 吴彦祖 | null | null |
这时我开启一个事务,执行select语句,就叫这个过程为:看看我是谁,结果是:id:1,name:吴彦祖。但是DB_TRX_ID版本变为了1.
| id | name | DB_TRX_ID | DB_ROLL_PTR | 我开启一个事务查看 |
| 1 | 吴彦祖 | 1 | null |
这是又有一个事务在我查看事务后开启,执行了一条更新语句,更新结果如下,同时DB_TRX_ID版本变为了2,这时执行“看看我是谁”,结果不变还是吴彦祖,原因就是遵循上面的展示规则:只能查找创建时间小于等于当前事务ID的数据,和删除时间大于当前事务ID的行(或未删除)
| 版本变味了 | name | DB_TRX_ID | DB_ROLL_PTR | 另一个事务开启了一个更新name操作 |
| 1 | mmm.c | 2 | null |
这是又有一个事务开启了删除操作,将这条字段整个删掉了,这时DB_ROLL_PTR变为了4,但是这时执行“看看我是谁”,结果不变还是吴彦祖,原因还是:只能查找创建时间小于等于当前事务ID的数据,和删除时间大于当前事务ID的行(或未删除)。
| id | name | DB_TRX_ID | DB_ROLL_PTR | 另一个事务开启了一个删除操作 |
| 1 | mmm.c | 3 | 4 |
所以说,在开启一个事务后,mvcc帮助我们模拟锁定了这个表,这个事务之后的一切操作都与这个事务无关。在Mysql中,Read Committed 和Read Repeatable Read隔离级别的一个非常大的区别就是它们生成ReadView的时机不同。在Read Committed中每次查询都会生成一个实时的ReadView,做到保证每次提交后的数据是处于当前的可见状态。而RepeaTable Read中,在当前事务第一次查询时生成当前的ReadView,并且当前的ReadView会一直沿用到当前事务提交,以此来保证可重复度(RepeaTable Read)。
这就是mvcc通过多版本的机制来实现数据库读一致性的解决方案。
个人学习笔记,欢迎大佬指正交流。

















 174万+
174万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









