




https://www.cnblogs.com/sudochen/p/16292447.html
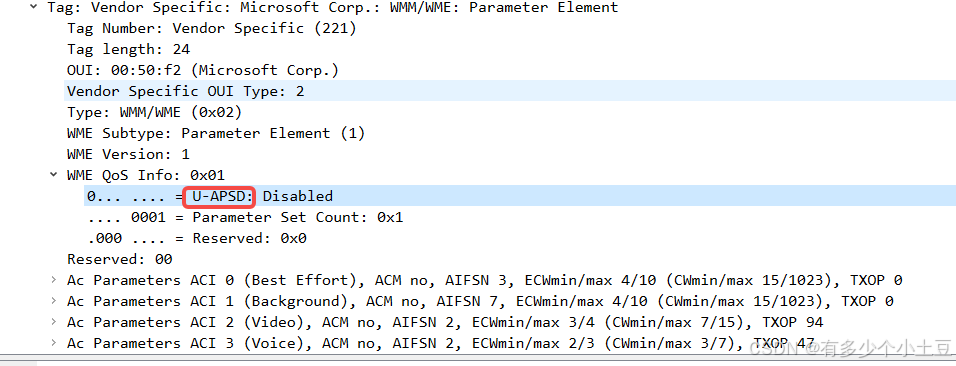
Beacon-> Tagged Parameter-> WMM/WME -> WME Qos Info -> U-APSD等于1才支持
https://www.cnblogs.com/sudochen/p/16292447.html
Beacon-> Tagged Parameter-> WMM/WME -> WME Qos Info -> U-APSD等于1才支持
 4127
2万+
4127
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























