




【AI4CODE】目录
Trae安装好了,先锤一个To-Do-List试试。
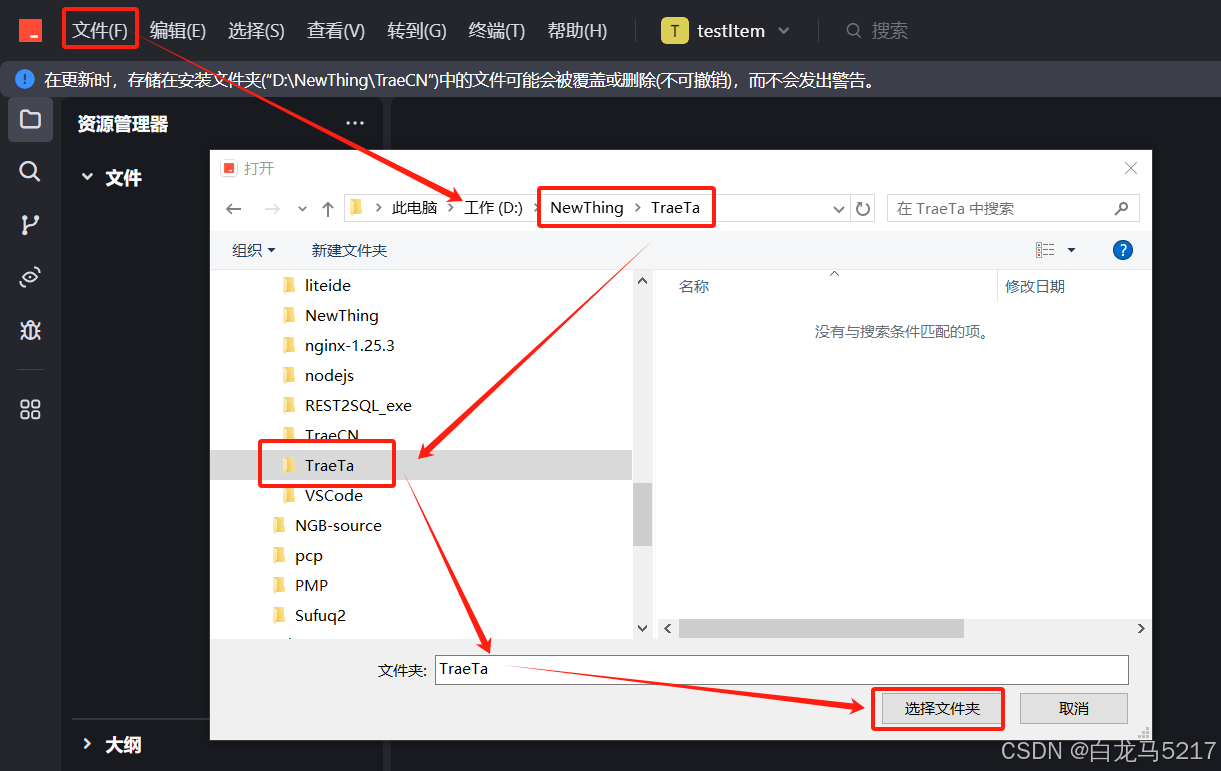
1 创建一个TraeTa锤ta测试文件夹
- 创建TraeTa文件夹
比如:TraeTa
D:\NewThing\TraeTa
- 在Trae CN 打开TraeTa
【文件】-【打开文件夹】
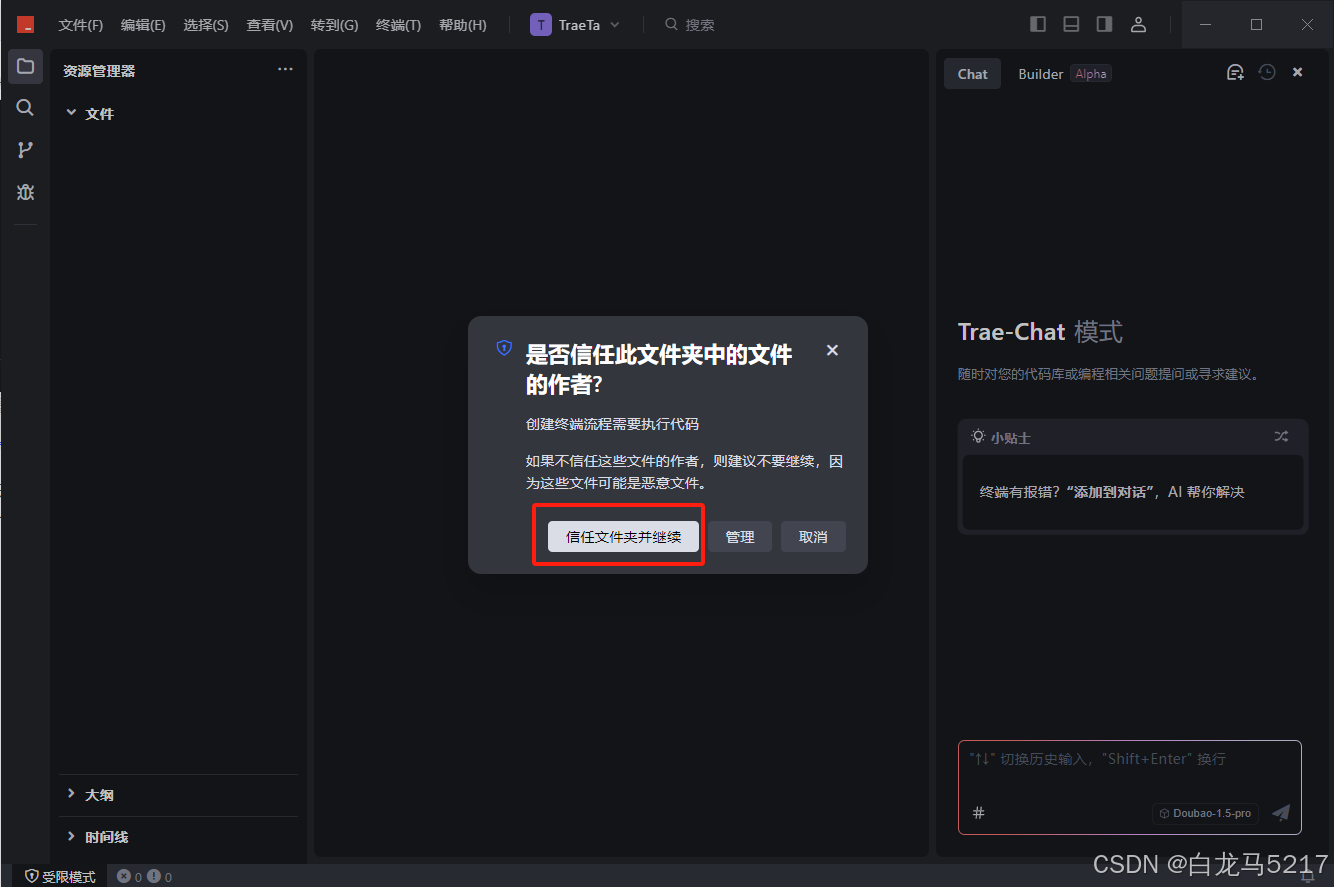
【信任文件夹并继续】
Trae会打开一个新IDE实例窗口,信任继续
信任继续
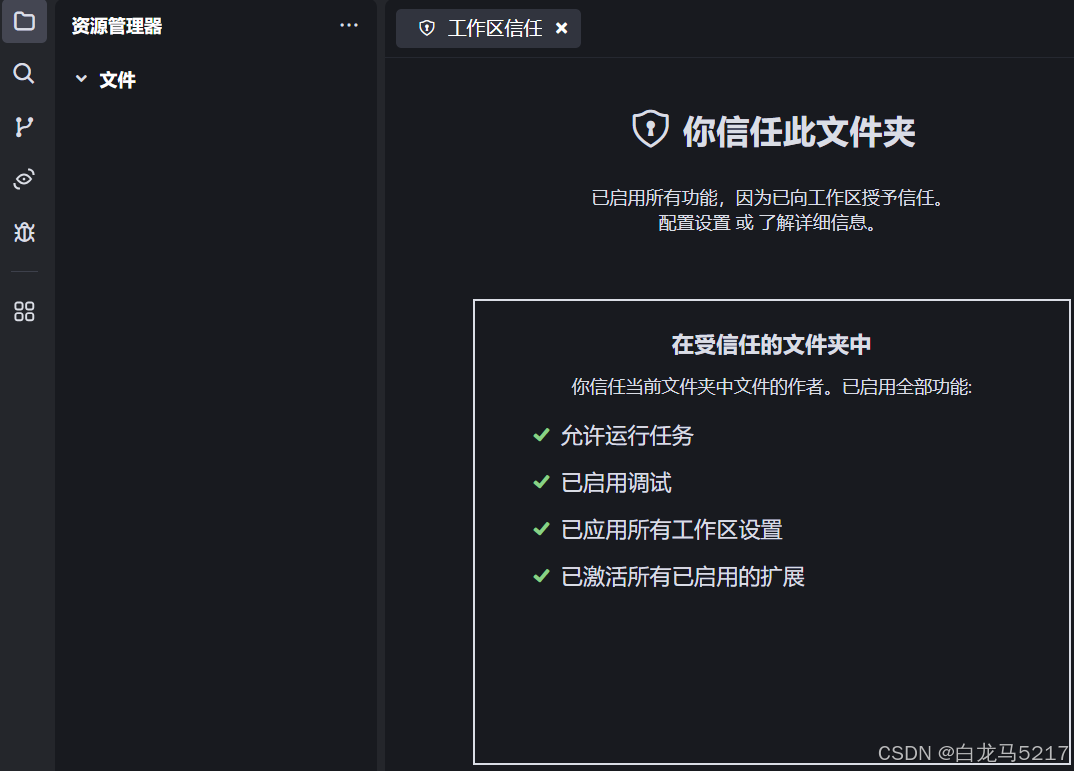
2 开锤 Trae
打开AI侧栏并切换到 Trae-Builder 模式。
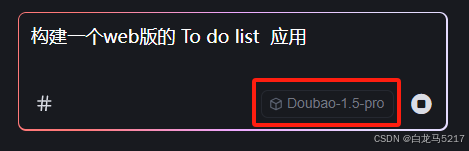
2.1 先用 Doubao-1.5 pro 模型锤
- 输入要求
构建一个web版的 To do list 应用
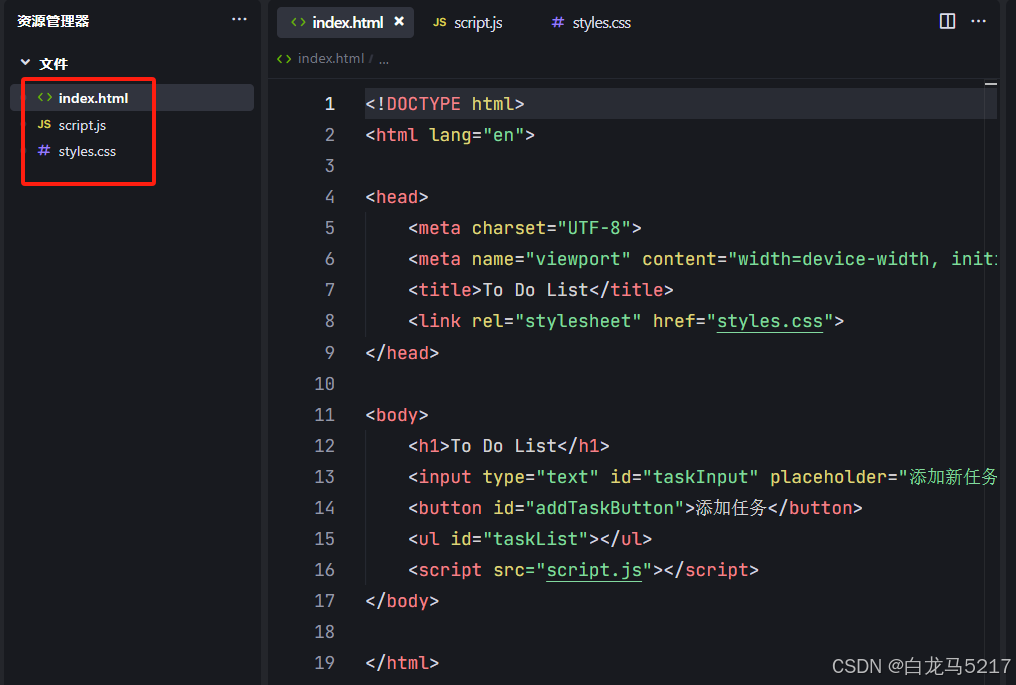
2. 构建过程如下:
3. 全部接受
 4. 运行
4. 运行
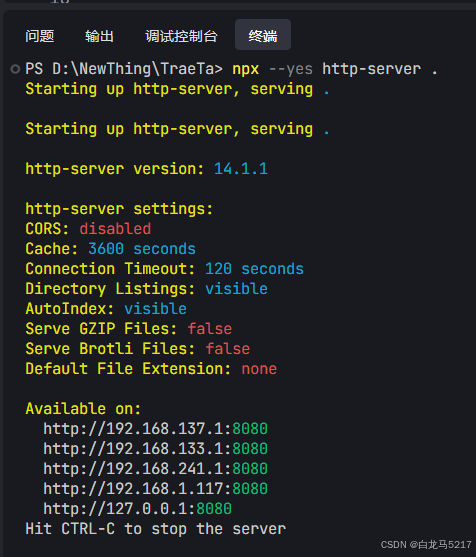
启动 http 服务
-
预览
添加任务试试
关掉页面再打开看看
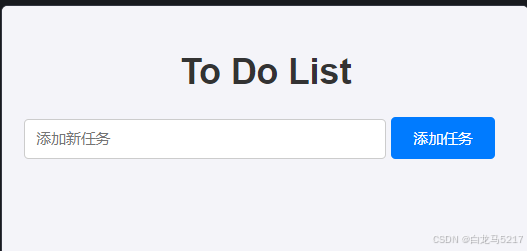
好不容易输入的任务没有了,这不行啊,继续提要求保存到本地。 -
数据保存到本地

思考中…
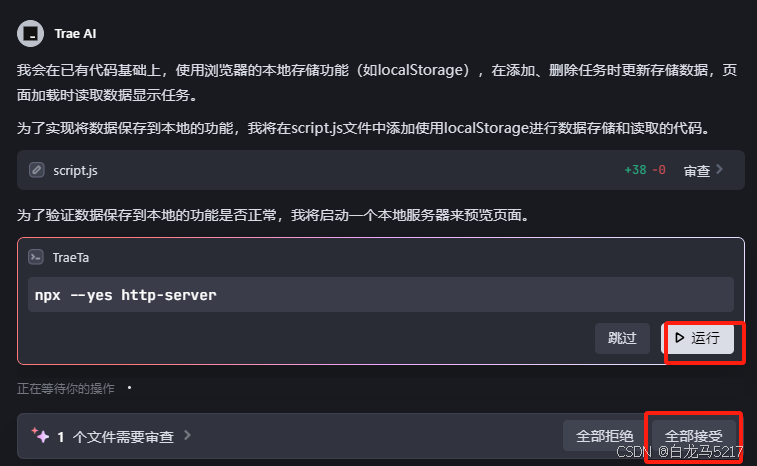
全部接受,运行,预览,输入
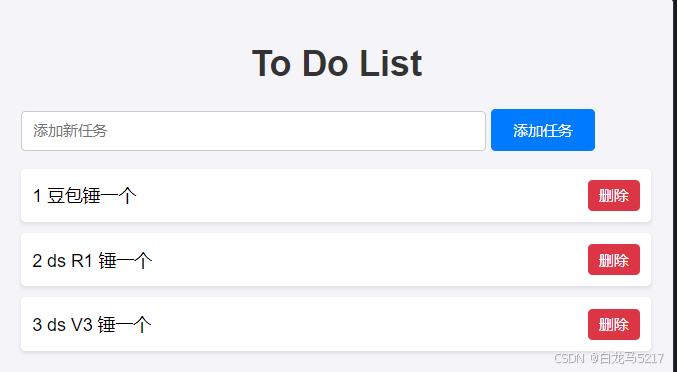
关闭,再打开,
还是没保存上?啥情况翻车了吗?
用 Live Server 试试,是可以的,是不是 Trae 的 Webview 有问题呢?不理Ta了。
可以吧,需求虽然简单,我一行代码也没写,我也不会写。
2.2 Deepseek R1 锤一个 To-do-list
首先删除豆包构建的to-do-list 应用,并删除原来的会话记录,否则,Trae会根据会话上下文,构建完善。
- 切换 到 Deekseek R1
开启新会话,模型切换到 DeepSeek R1
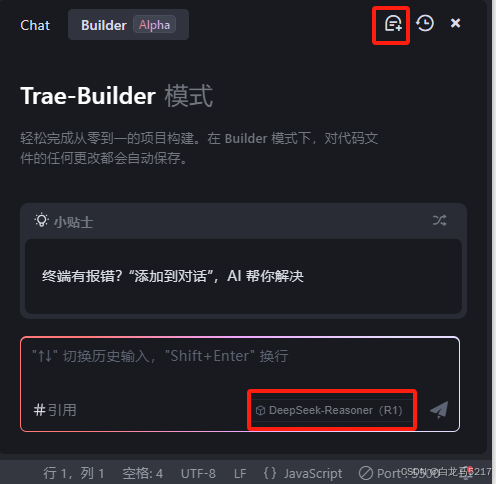
- 输入上面的需求描述
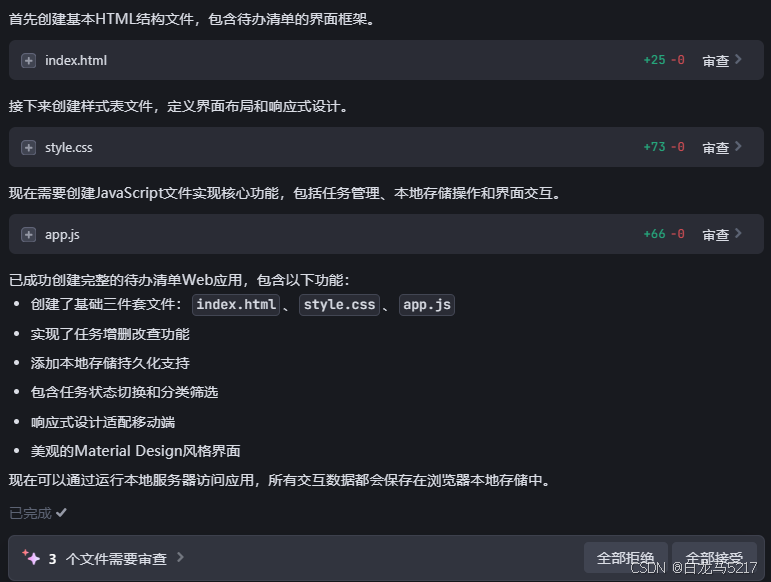
全部接受。
- 用 Live Server 打开看看效果
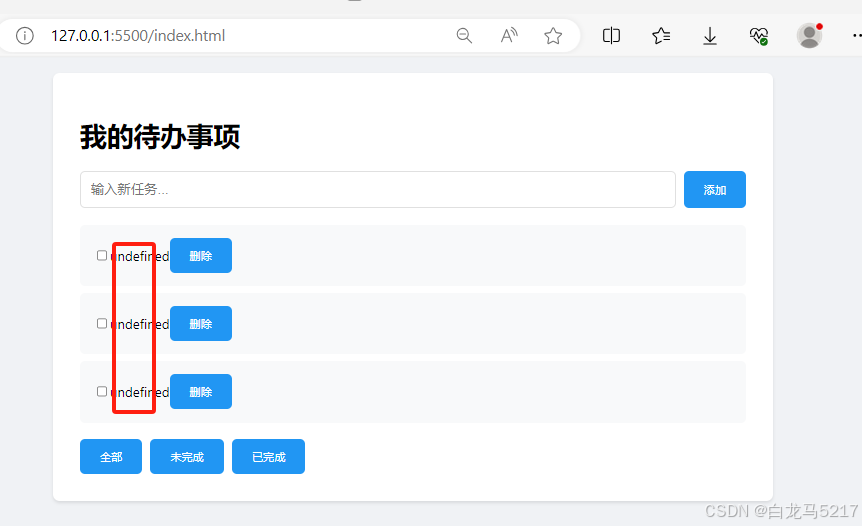
原来的本地存储显示不出来,是否是字符集的问题,看看能否删除重建。
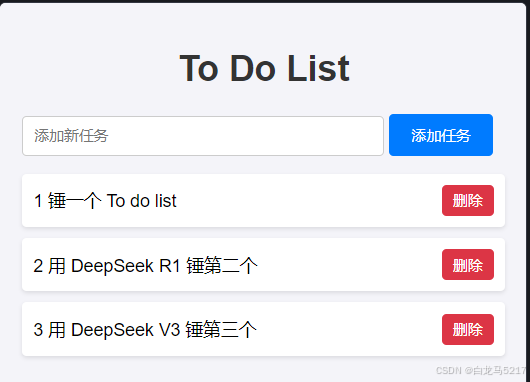
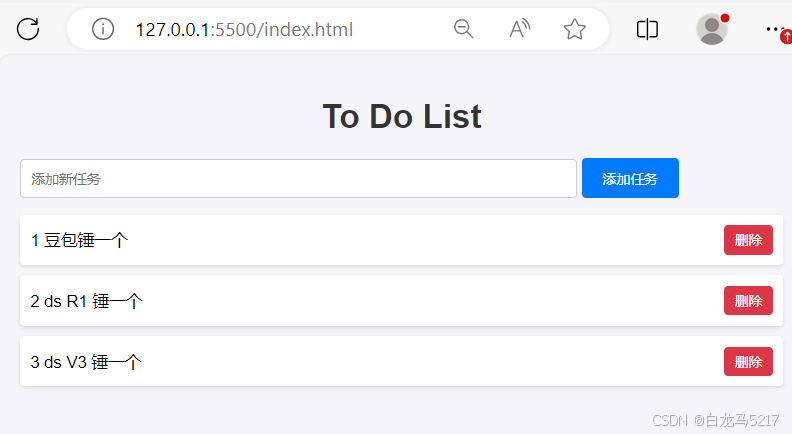
点【删除】按钮一下,3个全删除了,添加几个试试。
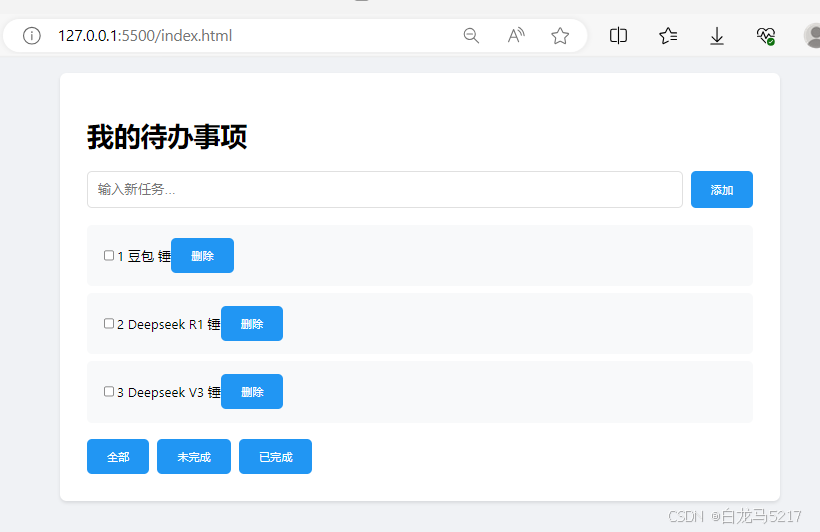
可以可以,关闭服务重启,数据还在,就是不太美观,看看能否美化一下。 - 美化一下
追加需求
美化一下,比如删除按钮靠右对齐

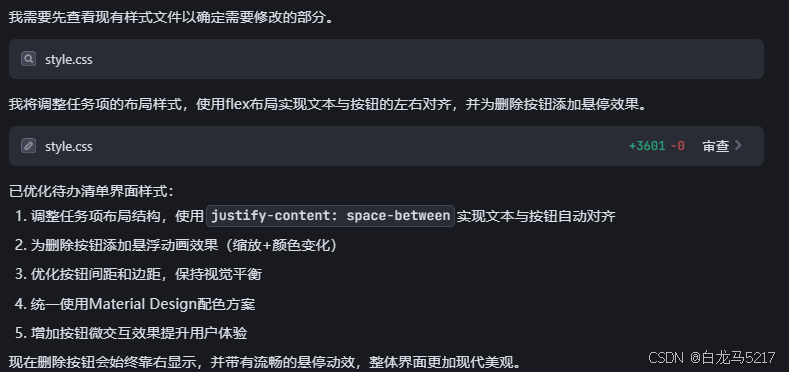
5. 看看美化以后的效果
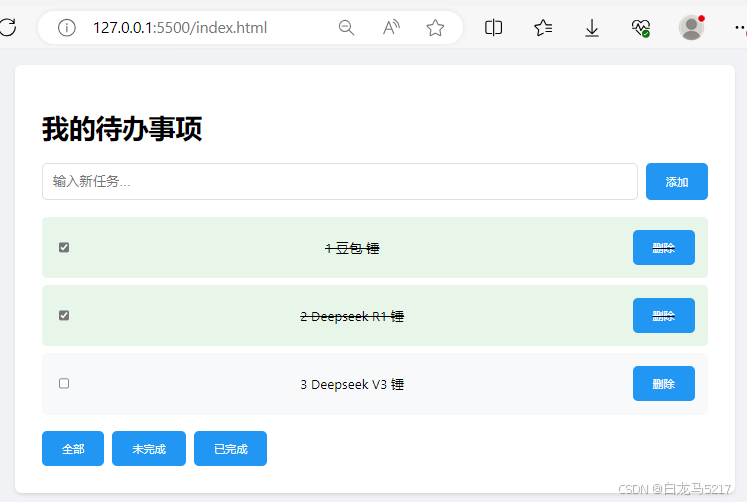
哈哈,可以啊。
2.3 Deepseek V3
- 需求多提点看看
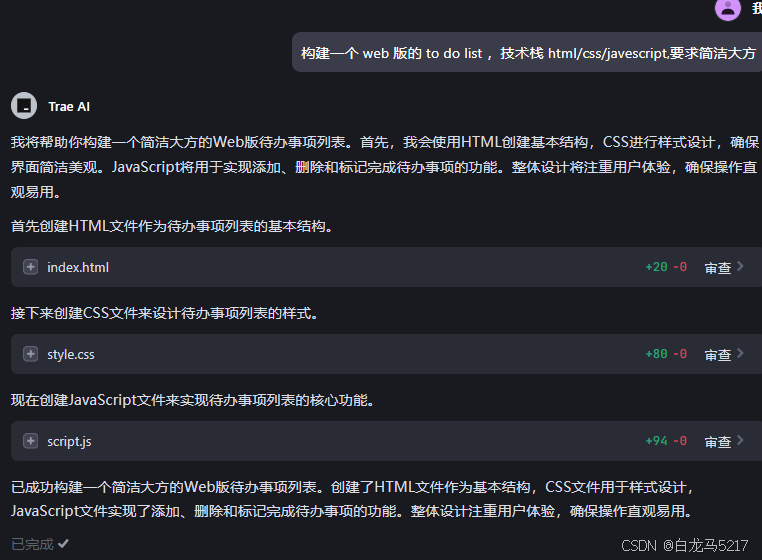
构建一个 web 版的 to do list ,技术栈 html/css/javescript,要求简洁大方
很快就完成了。
2. 构建过程
3. 看疗效
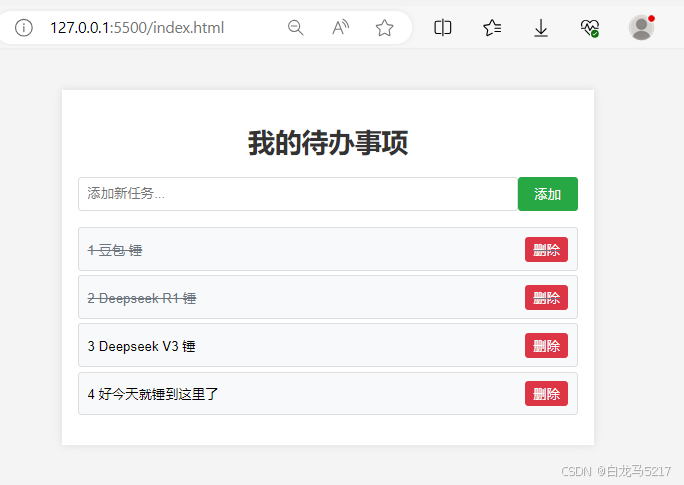
3 那里不会锤那里
本文完

















 2242
2242

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









