




 本文探讨了一公司系统中查询效率低下问题,通过分析发现是由于笛卡尔积导致的数据量剧增。通过创建GroupID,AgreeID,FID的组合索引,查询时间从70秒降至合理水平,但仍留有优化空间。作者分享了解决过程和关键代码片段,强调了索引选择对查询效率的重要性。
本文探讨了一公司系统中查询效率低下问题,通过分析发现是由于笛卡尔积导致的数据量剧增。通过创建GroupID,AgreeID,FID的组合索引,查询时间从70秒降至合理水平,但仍留有优化空间。作者分享了解决过程和关键代码片段,强调了索引选择对查询效率的重要性。
背景:
公司的一个在用的系统,如果查询数据量很小很小勉强还可以用,但是数据量稍微多一点点就直接卡爆了,因为系统有Nginx来设置超时,业务人员在使用的时候发现如果是点击大一点的组织,系统就会卡住了,无法加载数据出来。
于是需要从数据库将数据查询出来,发现从数据库进行查询既然也是很慢,于是就将之前别人开发这个查询脚本拿出来解剖。通过分析发现查询很慢的原因是两个表在进行关联的时候进行了笛卡尔乘积计算,将一个五千多条的数据和九千多条的数据进行了乘积运算,数据直接跑到了四百多万。这个时候如果没有创建索引,那将会进行的是 全表扫描了,所以计算当然会慢很多。
解决办法是为关联的连个表创建索引,提高查询的效率。
原来的代码:
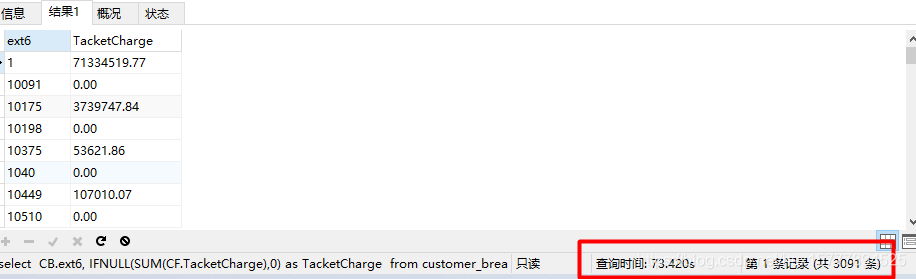
使用的是同样的代码,在没有创建组合索引的情况下,查询速度是70多秒,是我简化后截取的部分代码片段,原来系统里面的那个代码查询直接是600多秒,作为一个数据查看系统,这个是绝对无法忍受的。因此系统查询优化迫在眉睫。
优化前代码片段查询时间:
设计表创建组合索引:
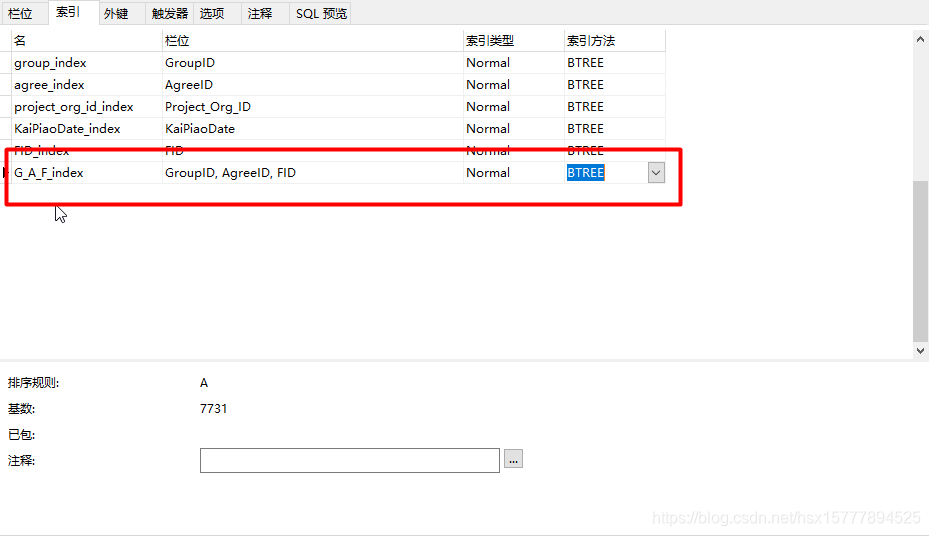
需要注意的是组合索引的使用要求:
因为我这个业务场景是需要关联多个表的,还有关联条件是必须存在的,所以创建的是组合索引,可以提高查询效率。
GroupID, AgreeID, FID
组合索引遵循最左匹配原则:
-
AgreeID,FID:这就相当于索引失效,没有走这个索引,你的查询和没有索引一样。
-
GroupID,FID:这种情况是相当于只是走了G
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1847
1847

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









