






公告:老王的公众号改名啦,【互联网及大模型运维杂谈】是【互联网运维杂谈】的升级版!想通过该号让运维人一起拥抱变化,拥抱大模型和AI!
“Embedding”在字面上的翻译是“嵌入”,但在机器学习和自然语言处理的上下文中,我们更倾向于将其理解为一种“向量化”或“向量表示”的技术,这有助于更准确地描述其在这些领域中的应用和作用。
Embedding向量化
大模型 Embedding 的原理是将离散的数据转换为连续的向量,便于计算机理解和处理。以下是关于其工作原理、优势和应用的详细说明:
一、工作原理:
转换数据类型:将离散的文字信息(如单词)转换成连续的向量数据。
语义空间映射:语义相似的词汇在向量空间中位置相近,通过高维度捕捉语言的复杂性。例如,句子“猫追逐老鼠”和“小猫捕猎老鼠”在经过 Embedding 转换后,即使没有很多共同词汇,也能被计算机理解为相关。
向量表示:将离散信息(如单词、符号)转换为分布式连续值数据(向量)。
图像向量化:通过算法提取图像的关键特征点及其描述符,将这些特征转换为高维向量表示。在向量空间中,相似的图像具有相近的向量表示。
二、优势:
降低维度:将高维度数据映射到低维度空间,减少模型复杂度。
捕捉语义信息:能够捕捉到数据的语义信息,使语义上相近的词在向量空间中也相近。
适应性:通过数据驱动的方式学习,自动适应数据的特性,无需人工设计特征。
泛化能力:对于训练数据中未出现过的数据,仍能给出合理的表示。
三、Text Embedding 的应用:
信息检索:用于搜索、推荐、分类和聚类等。
构建知识问答系统:将用户问题和本地知识进行 Embedding,通过向量相似度实现召回。通过大模型对用户问题进行意图识别,并对原始答案加工整合。
语义检索:通过词向量来表示文本,捕捉到词汇之间的语义联系,在处理拼写错误、同义词、近义词等方面更具优势。
四、Embedding 的生成方法:
Word2Vec:通过上下文预测中心词(CBOW)或通过中心词预测上下文(Skip-gram)来学习词向量。
GloVe:基于共现矩阵(Co-occurrence Matrix),通过统计方法计算单词之间的关联性,然后通过奇异值分解(SVD)生成嵌入。
FastText:在 Word2Vec 的基础上添加了字符级别的 n-gram 特征,可以处理不规则和罕见单词。
五、向量数据库:
向量数据库用于存储和快速检索 Embedding 向量,常见的向量数据库包括 Pinecone, Milvus, Weaviate, Qdrant, Chroma 等。
Word2Vec词向量
词向量 Word2Vec 是一种流行的自然语言处理 (NLP) 工具,它通过将词汇表中的每个单词转换成一个独特的高维空间向量,使得这些词向量能够在数学上表示它们的语义关系。Word2Vec 从大量文本语料中以无监督方式学习语义知识,被广泛地应用于自然语言处理中。
Word2Vec 的作用和目的:
* 将语言中的词进行数学化,把一个词表示成一个向量。
* 生成词向量,通过词语的上下文信息来学习词语的向量表示。
* 能够将单词转化为向量来表示,这样词与词之间就可以定量的去度量他们之间的关系,挖掘词之间的联系。
* 可用于词语相似度计算、文本分类、词性标注、命名实体识别、机器翻译、文本生成等。
Word2Vec 的两种模型框架:
* CBOW (Continuous Bag of Words):通过上下文预测目标单词。例如,在“the cat sits on the”中,CBOW 使用“the”、“cat”、“sits”、“on”、“the”作为输入来预测“mat”这个词。CBOW 适合于数据集较小的情况。
* Skip-gram:用一个单词来预测上下文。例如,给定单词“sits”,模型将会尝试预测它周围的单词如“the”、“cat”、“on”、“the”¹。Skip-Gram 在大型语料中表现更好。
Word2Vec 的网络结构
Word2Vec 是轻量级的神经网络,其模型仅仅包括输入层、隐藏层和输出层。
* Simple CBOW Model:
* Input Layer:输入的 X 是单词的 one-hot representation。
* 输入层到隐藏层:通过权重矩阵 W 得到隐藏层的值。
* 隐藏层到输出层:也有一个权重矩阵 W',输出层向量 y 的每一个值,就是隐藏层的向量点乘权重向量 W' 的每一列。
* Output Layer:经过 softmax 函数,将输出向量中的每一个元素归一化到 0-1 之间的概率,概率最大的,就是预测的词。
* Skip-gram Model:通过输入一个词去预测多个词的概率。输入层到隐藏层的原理和 simple CBOW 一样,不同的是隐藏层到输出层,损失函数变成了 C 个词损失函数的总和,权重矩阵 W' 还是共享的。
Word2Vec 的优点:
* 模型简单,训练速度快。
* 训练中会考虑单词的上下文。
Word2Vec 的缺点:
* 上下文窗口较小,也没有使用全局的单词共现信息。
* 每个单词的词向量是固定的,无法解决一词多义的问题。
示例:
输入datadog单词(其实是个监控产品名),给出10个近似的词语预测!概率特征基本上与现实一致,该概率计算是由损失函数计算而来,后续章节会给出介绍。
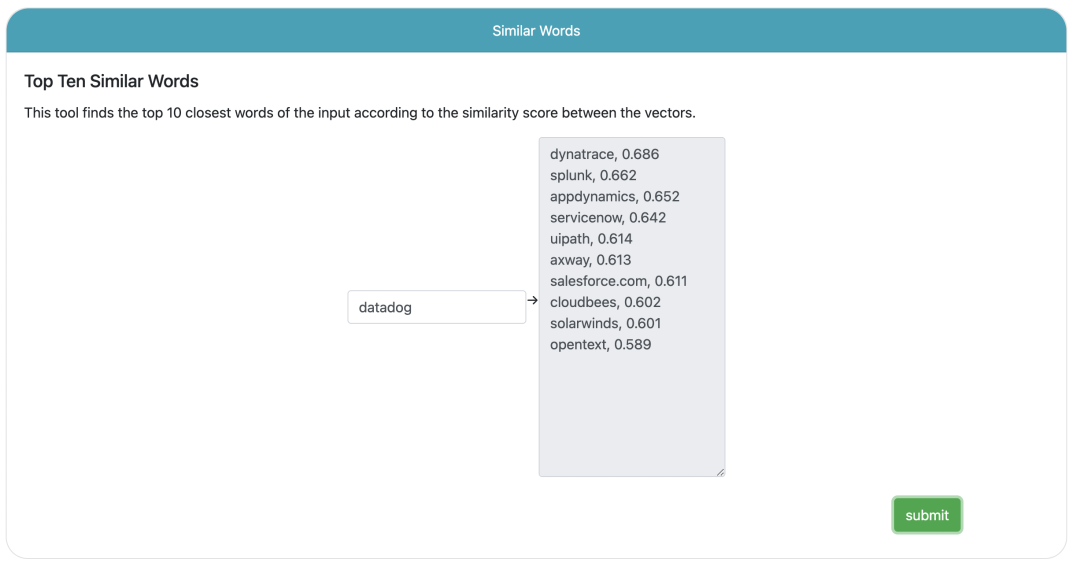
本篇文章背后有很多潜在的数学知识,大家有兴趣可以深入自己了解!
References:
[1] AI大模型之路第二篇: Word2Vec介绍 - 腾讯云 - https://cloud.tencent.com/developer/article/2410253
[2] 一文读懂:词向量Word2Vec - 知乎 - https://zhuanlan.zhihu.com/p/371147732


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









