




 文章详细阐述了C语言中指针的概念,包括空指针(NULL)的定义与使用,二级指针的存储和类型,以及数组指针的模型和内存大小。此外,还讨论了字符数组、字符串常量的区别,函数的形参与实参,以及局部变量和全局变量的生命周期。文章提到了Linux中的man手册用于查询函数用法,介绍了函数命名规范,以及结构体、共用体、枚举、宏定义和typedef别定义等C语言高级特性。
文章详细阐述了C语言中指针的概念,包括空指针(NULL)的定义与使用,二级指针的存储和类型,以及数组指针的模型和内存大小。此外,还讨论了字符数组、字符串常量的区别,函数的形参与实参,以及局部变量和全局变量的生命周期。文章提到了Linux中的man手册用于查询函数用法,介绍了函数命名规范,以及结构体、共用体、枚举、宏定义和typedef别定义等C语言高级特性。
一级指针:空指针
NULL -->空指针
int *p ; //指针变量p的地址是随机地址
//未初始的指针叫做野指针,他是很危险
指针的零值:
#define NULL (void *)0x0
int *p = NULL; //NULL是空指针
//所以指针定义后如果未初始化,就赋值为NULL,比较安全
*p = 100; //通用指针是不能解引用,执行会报错
gec@ubuntu:/mnt/hgfs/GZ2162期/C语言/07/code$ ./a.out
Segmentation fault (core dumped) -->段错误,非法访问(没有权限访问)内存
二、二级指针
1、概念:指针变量用来存储变量内存地址
一级指针存储除了指针变量之外变量的地址
二级指针存储一级指针变量地址
int a =10;
a-->类型为:int
&a-->类型为:int *
int *p = &a;
p -->类型为:int *
&p -->类型为:int **
int **q = &p;
q -->类型为:int **
&q -->类型为:int ***
2、定义模型
一级指针变量类型 *变量名
(int *)*q <==> int **q
q -->存储的对象为:int *
q -->类型为:int **
int *p;
int **q = *p;
char *p1;
char **q1 = &p1;
3、二级指针的大小:
32位系统占4个字节
64位系统占8个字节
int **q;
4 == sizeof(q)
4、二级指针数据类型问题
int **q; q的数据类型为:-->int **
&q的类型为:-->int ***
int *p; p -->int *
&p -->int **
int a; a -->int
&a -->int *
5、二级指针的使用
int a =10;
int *p = &a;
int **q = &p;
a, &a, p, &p, q, &q, *(&a), *p, *q, **q
三、数组指针
1、概念:本质是一级指针,用来存储数组的地址
2、定义模型:
int a[3]={1, 2, 3};
数组a的类型是:int ()[3]
&a -->类型是:int (*)[3], 可以定义int (*p)[3] = &a;
a -->类型是:int * , 可以定义int *p = a;
&a[0] -->类型是:int *, 可以定义int *p = &a[0];
a[0] -->类型是:int , 可以定义int a = a[0];
以下两种数组指针类型是不同的
int (*)[2]
int (*)[3]
以下两种数组类型是不同的
int ()[2] <==> int ()[3]
int a[2]
int a[3]
-------------------
int a[2][3];
&a -->类型是: int (*)[2][3] 可以定义
a -->类型是: 可以定义
&a[0] -->类型是: 可以定义
a[0] -->类型是: 可以定义
&a[0][0] -->类型是: 可以定义
a[0][0] -->类型是: 可以定义
-------------------
模型:
数组的数据类型 *变量名
3、 内存大小
32位系统占4个字节
64位系统占8个字节
4.字符数组与字符指针
Char str[] = “hello”; // char str[6] = “hello”; 字符串存储的位置不一样! 上面的”hello”存放在进程栈空间 ==> str数组里面的内容是可以修改的
Char *str1 = “world”; // 下面的”world”存放在进程的常量区 ==> str1指向的这篇空间是不能修改的


6.数组指针与指针数组
数组指针:一个指向数组的指针
指针数组:一个基本元素是指针的数组
Int a[10];
Int (*p)[10] = &a; //数组指针p指向数组a的地址 sizeof(p) = 4字节
Int *p1[10]; //指针数组
==》示例代码

Char *s[] = {“nihao”, “hello”, “world”, “zzz”};
Char *s[4] = {“nihao”, “hello”, “world”, “zzz”};
==> 思考: sizeof(s) = 16 (32位系统下)
==> s[0] = “nihao” //当把一个字符串赋值给一个变量时,指的是把字符串首地址赋值给这个变量 --> 字符串首地址:首字母的地址
==> s[1] = “hello”
==> s[2] = “world”
==> s[3] = “zzz”
==> printf(“%s\n”, s[2]);
==> 思考: printf(“%c\n”, *(s[1]+1)); 输出的结果是什么? ‘e’
printf(“%s\n”, s[2]+1); 输出的结果是什么? “orld”
在Linux中,如果碰到不会用的函数,那就去查看函数的用法,在Linux下有一本手册帮我们对所有的函数进行说明 --> man
==> man man
1 Executable programs or shell commands //shell 命令 --> ls cd ...
2 System calls (functions provided by the kernel) //系统调用函数
3 Library calls (functions within program libraries) //库调用函数 --printf,scanf
4 Special files (usually found in /dev)
5 File formats and conventions eg /etc/passwd
6 Games
7 Miscellaneous (including macro packages and conventions), e.g. man(7), groff(7)
8 System administration commands (usually only for root)
9 Kernel routines [Non standard]
==> man手册查看函数命令格式 man [手册号] [函数名]
==> 查看ls命令的用法: man 1 ls
==> 查看printf函数的用法: man 3 printf
==> 查看函数属于第几本手册: man -f [函数名]
函数命名
比较流行的函数名的命名方式:
·匈牙利命名法
-->把变量类型放在变量名的前面
例如: long lnum; unsigned int uinum;
·驼峰命名法
A,小驼峰命名法
把组成变量名的单词第一个单词用小写字母开头,后面的单词都使用大写字母开头。
例如: long totalNum;
B, 大驼峰命名法
把组成变量名使用大写字母开头。
例如: long TotalNum
·下划线命名法
命名时把组成变量的单词使用下划线隔开
例如: long total_num; //Linux C 下习惯使用这种命名法
函数传参
- 形参与实参
·形参:函数在定义的时候给定的形式参数
==> int max_num(int a, int b) ==> 形式参数 int a, int b
==> 形参在函数定义时时不分配空间的,当对这个函数进行调用的时候才会给形参分配空间 ==> 当函数结束之后,形参的空间会被回收
·实参:函数在调用的时候给定的实际参数
==> max_num(5, 10); ==> 5, 10是实际参数
==> 实参可以是变量,常量,表达式
==> 当函数调用的时候,实际上发生的操作: 实参对形参的赋值
==> 例如: max_num(5, 10); 实际上会出现 int a = 5; int b = 10;
- 同名的实参与形参存储空间是不一样的!
==> int max_num(int a, int b); //这个a和b是形参!
==> a = 10, b = 20; max_num(a, b); //这个a和b是实参!
==> 实参和形参的存储空间是不一样的!



总结:
- 在不同的函数中,同名的局部变量使用的空间不是同一片。
- 函数的形参就是这个函数的局部变量
- 函数的形参只有在函数执行的时候才会分配空间,没有调用函数时是不分配空间的,同时会实现实参对形参的赋值。
补充:局部变量与全局变量
局部变量: 定义在函数内部的变量是局部变量
全局变量: 定义在函数外部的变量是全局变量
- 存储区域区别
局部变量: 局部变量存放在栈空间(系统自动分配,自动回收)
全局变量: 全局变量存放在数据段(一直存在,程序结束才释放)
- 生命周期
局部变量:从定义的位置开始,直到函数结束。
全局变量:从定义的位置开始,直到程序结束。
- 未初始化
局部变量:随机值
全局变量:默认是0
- 如果全局变量与局部变量同名
==> 他们使用的空间不是同一个空间


- 数组传参
==> 如果形参类型是数组类型,那么在实际传参过程中,传递的是一个指针。
==> 例如:
void fun(int a[100]);
{
Printf(“sizeof(a) = %d\n”, sizeof(a)); //输出结果是多少? 4
}

变参函数
==> 变参函数:参数数量是可变的函数 printf(), scanf()
SYNOPSIS
#include <stdio.h>
int printf(const char *format, ...);
==> const char *format : 固定参数 只读的字符指针 --> 字符串
==> printf(“helloworld!\n”) ; //此时只有一个参数
==> printf(“a = %d\n”, a); //此时有2个参数
==> printf(“a = %d, b = %d\n”, a, b); //此时有3个参数
回调函数
==> 函数在传参的时候,把参数和需要执行的函数都作为参数传递给一个函数,在这个函数中对这个函数进行调用
==> 例如: 你是一个饭店老板,自己去买菜,请厨师去做菜,得到菜品。
案例代码:

==> 在这个例子中,回调函数就是饭店老板,a,b,c就是菜的原材料,函数指针就是厨师岗位,传入的参数不同结果也会不同。
补充:函数指针与指针函数
·函数指针: 指向函数的指针
·指针函数: 返回值为指针的函数
例如: 指针函数
int *fun(int *a, int *b); //这是一个指针函数,参数为2个int *,返回值为int *的函数。
例如:函数指针
Int (*fun)(int *a, int *b);
==》 fun是一个函数指针,指向一个拥有两个int *参数,返回值为 int的函数。
例子: 使用函数指针去访问函数,调用这个函数的功能。

- 结构体
- 什么是结构体?
==> 结构体其实就是用户自定义的一种复合数据类型。结构体中可以有各种成员,char, int, long, float ... 数组, 指针, 其他的结构体...
- 结构体的作用
==> 在计算机中存在各种类型的常量,1, 3.14, “nihao” ... 这些不同类型的常量在进行计算时,可以使用不同类型的变量进行存储。 int , float, char []
==> 在描述一些比较复杂的事物的时候,基本数据类型完全不够用,这种情况下需要设计一个能表示多种信息的数据类型 --> 结构体
- 结构体声明格式 //结构体的声明都是要放在函数外面
格式
struct 结构体名{
Char ch;
Short s;
Int i;
Char str[20]; //结构体成员
...
};
例如: 声明一个书本信息的结构体
struct book_info{
Int num; //书号
Float price; //单价
char author[16]; //作者
Char name[32]; //书名
};
注意:结构体的声明必须要在函数体外部声明。
结构体的声明语句中不能对成员赋值。
- 结构体定义
==> 在程序中使用某一种结构体时需要先定义对应的结构体变量。
==> 格式: 结构体类型 变量名; ==> 例如: struct book_info book1;
示例代码:声明一个书本信息结构体,定义一个书本信息结构体变量,对他赋值并且输出。

- 结构体赋值
- 初始化赋值 --> 定义结构体变量时对结构体进行赋值
·顺序赋值
·乱序赋值

- 定义完成之后再赋值 --> 定义的时候不赋值,定义完再赋值
==> 结构体变量在定义完成之后再赋值那就需要对里面的成员一个一个的赋值。

- 结构体指针
==> 指向结构体的指针。 结构体指针访问结构体变量格式: 指针名->成员名;

- 结构体数组
==> 每一个成员都是结构体的数组。

- 结构体大小计算
==> 结构体是一种复合数据类型,结构体的大小是结构体的各个成员的大小之和,而且按照C语言语法规则,结构体大小默认是需要遵循字节对齐的。
例如:
结构体大小计算规则:
- 如果结构体成员只有一个,结构体大小就是成员大小
- 结构体大小会从上往下逐个计算成员变量的大小然后相加
- 结构体的最终大小必须是最大的成员变量的整数倍
- 结构体成员变量的所占的内存的地址必须要能被这个类型的大小整除(int类型的变量的首地址一定要能被4整除,double类型的变量大小一定要能被8 整除)

共用体(联合体)
==> 关键字: union
==> 联合体的所有成员共用同一片空间,空间的大小由最大类型成员决定。所有成员的基地址都相同(联合体的首地址)。
例如:
union data{
Char c; // 1
Short b; //2
Int i; //4
Double d; //8
};
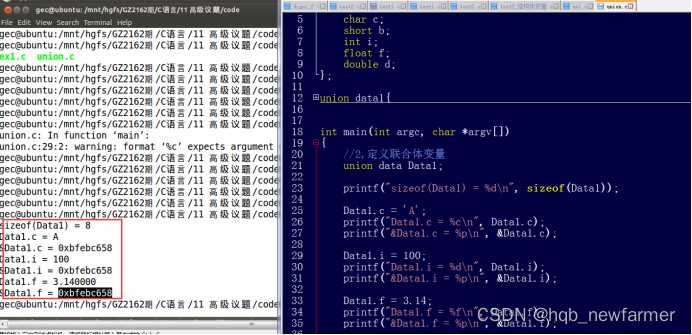

总结:
- 共用体的所有成员使用同一片空间
- 共用体的大小由成员变量中最大的那个成员变量决定。
- 共用体所有成员的首地址都是一样
- 共用体在使用时,某一时刻只能使用其中某一个成员变量
枚举
关键字 enum
枚举类型的定义:枚举变量在没有赋值的情况下,数值默认从0开始,后面的值依次加1.
Enum state{
Ok , //0
Failed, //1
Maybe //2
};
==> 枚举变量在定义时给某一个值进行赋值,那么后面没有赋值的成员会从这个成员变量开始依次+1
Enum state{
Ok , //0
Failed = 100, //100
Maybe //101
};

- 宏定义与别定义
- 宏定义 -- #define
格式:
#define 标签 替换列表
作用:在编译的时候把代码中的标签出现的位置使用替换列表内容进行替换过期
标签:命名规则跟变量名命名规则一样!
替换列表 :常量(1, 100, 3.14, “hello”); 数据类型 (unsigned char , int, long int ..),其他的宏定义...
例如: #define N 100
==> int a[N]; == int a[100];
==> 注意:宏定义不是变量!替换列表替换标签的过程发生的编译过程的预处理阶段,宏定义是不会影响程序的运行速度的。
#define MSTR “helloworld”
#define Uchar unsigned char
Uchar ch; ==> unsigned char ch;
==> 作用:提高代码的可维护性。
- 宏函数(带参宏)
格式: #define 宏名(参数列表) 替换标签
==> 参数列表: 参数与参数之间使用,隔开,参数不需要写类型
==> 例如: 定义一个宏用来判断一个整数是不是偶数
==> #define IS_EVEN(a) (a % 2 == 0)
==> if( IS_EVEN(x) ) == if(x % 2 == 0 )
==> 定义一个带参宏用于计算两个数之和
#define SUM(a,b) (a+b)
==> int x, y; int sum = SUM(x, y);
==> 定义一个标准宏用来返回两个数中的较大值
#define MAX(a, b) a>b?a:b
==> int x, y; MAX(a, b);
--> 练习1: 设计一个程序,从键盘输入圆的半径(整数),求圆的面积和周长。要求:圆周率取3.14, 圆周率和面积计算,周长计算都是用宏实现。

别定义 -- typedef
==> 别定义的作用就是给类型取别名
==> 格式: typedef 数据类型 别名;
==> 数据类型 : 任意一种类型 char , short, int , long , float ... , 自定义数据类型 数组,指针... 结构体
==> 别名 : 遵循变量命名规则
==> 例如 : typedef unsigned int uint32_t; ==> 此时uint32_t和unsigned int 表示就是同一种类型了。
==> uint32_t i; // unsigned int i;
==> strlen() ==> size_t : long unsigned int ==> typedef long unsigned int size_t;
==> 常常用来给结构体取别名
typedef struct student_info{
Char sex[4];
Int num;
Char name[16];
Char tel[12];
}Student;
==> 此时Student 类型就是 struct student_info
==> Student stu1; == struct student_info stu1;
例子:对书本信息结构体取别名,然后对这种类型进行使用。

总结:
- 宏定义其实就是在编译的预处理阶段把代码中出现的标签用替换列表里面的内容进行替换,这种替换不会影响程序的运行速度
- 宏定义的标签不需要指明数据类型
- 宏定义的标签名遵循变量命名规则(习惯用大写)
- 宏定义不需要写 = , 末尾也不需要写 ;
- 别定义就是给一种类型取别名
- 别定义时末尾要加 ;


















 1105
1105

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











