 Python批量提取PDF表格数据:使用yield优化性能
Python批量提取PDF表格数据:使用yield优化性能







 本文介绍如何使用pdfplumber和pandas库从PDF文件中批量提取和分析表格数据。通过应用yield语法,实现数据迭代输出,以提高性能并避免大列表导致的内存问题。虽然已通过next方法进行部分优化,但在处理大量数据时,仍存在内存占用过快的问题,可能需要采取分批提取的策略。
本文介绍如何使用pdfplumber和pandas库从PDF文件中批量提取和分析表格数据。通过应用yield语法,实现数据迭代输出,以提高性能并避免大列表导致的内存问题。虽然已通过next方法进行部分优化,但在处理大量数据时,仍存在内存占用过快的问题,可能需要采取分批提取的策略。
很多时候,在处理各种数据业务时候,会受到到PDF格式的文件,需要提取并分析里面的数据。本文利用pdfplumber,pandas 提取保存表格。同时学习利用yield语法,形成迭代器,输出每页数据。避免使用列表的办法输出,提升性能,简化代码。
代码如下
import gc
import pdfplumber
import pandas as pd
import time
from time import ctime
import openpyxl
pdf = pdfplumber.open(r"E:\python项目\python\小阳工程\提取pdf表格,筛选表格数据\条件筛选表格输出\1032+第三册+第二分册+路基路面.pdf")
N=len(pdf.pages)
print('总共有',N,'页')
def yieldlist( ):
for i in range(249,N):
print('********************************************************************************************************************************************************')
print('正在搜寻第',str(i+1),'页表格')
print('********************************************************************************************************************************************************')
p0 = pdf.pages[i]
yield p0
def dojob1(): #此函数没有多线程 直接循环提取表格
i=249
for item in yieldlist():
try:
table = item.extract_table()
#print(table)
df = pd.DataFrame(table[1:])
#print(df)
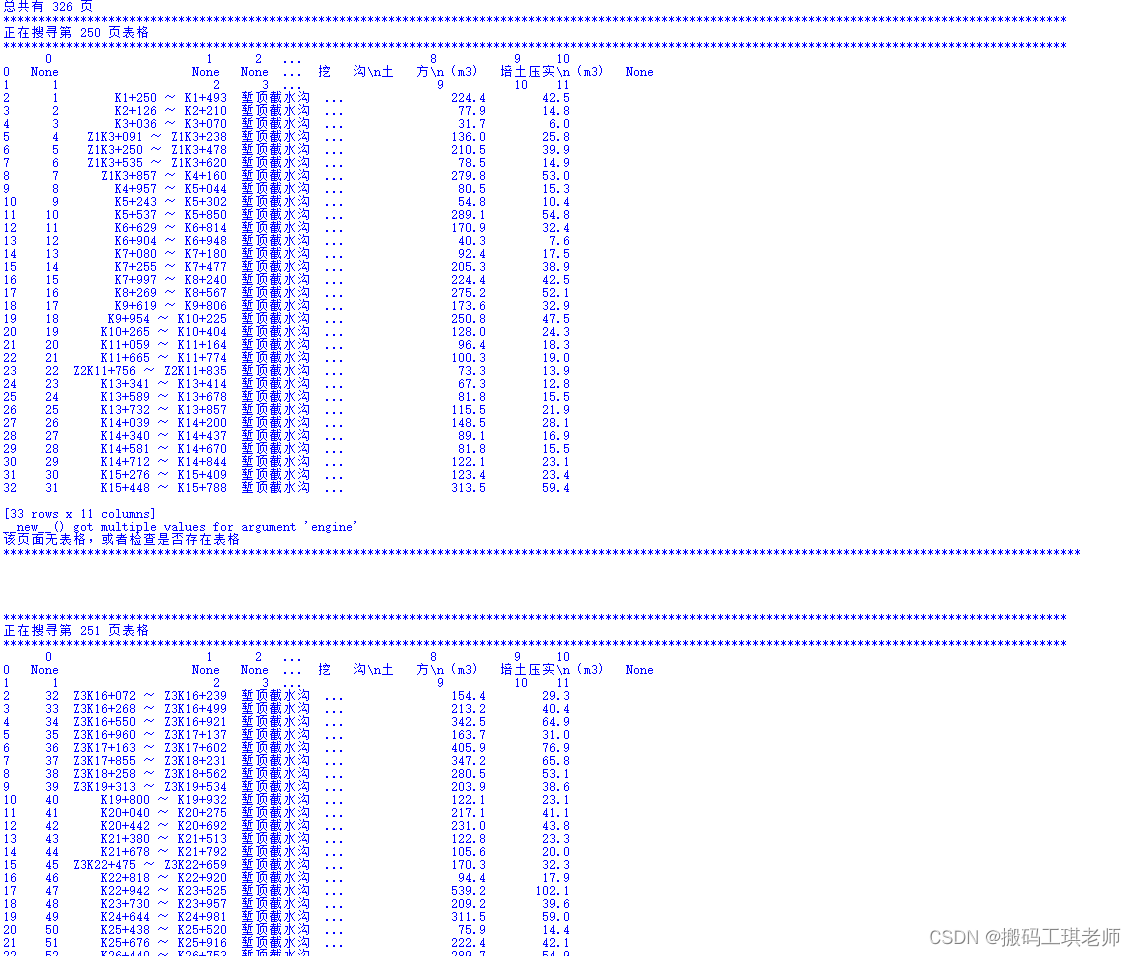
print(df)
#excel_writer = pd.ExcelWriter("1032+第三册+第二分册+路基路面"+str(i+1)+".xlsx","1032+第三册+第二分册+路基路面第"+str(i+1)+'页表格', engine='openpyxl', mode='a', if_sheet_exists='replace')
#df.to_excel("1032+第三册+第二分册+路基路面"+str(i+1)+".xlsx","1032+第三册+第二分册+路基路面第"+str(i+1)+'页表格', header=True, index=False) #去掉注释符号 这句把数据保存到excel
del df
gc.collect()
except Exception as e:
print(e)
print('该页面无表格,或者检查是否存在表格')
pass
#print('目前内存占用率是百分之',str(ps.virtual_memory().percent),' 第',str(i+1),'页输出完毕')
print('**********************************************************************************************************************************************************')
print('\n\n\n')
i+=1
#print('我是单线程循环,可能会导致内存溢出')
if __name__ == '__main__':
dojob1()
下面是加了next方法,稍微优化了一下,如果try:输出表格,内存不会溢出。但是如果到了except那里,每次循环之后,内存就会很快满起来,不知道该怎么弄,next稍微优化了一点,但是后面那个还是解决不了,有大神懂得,给我留言指点一下。
import gc
import pdfplumber
import pandas as pd
import time
from time import ctime
import openpyxl
pdf = pdfplumber.open(r"E:\python项目\python\小阳工程\提取pdf表格,筛选表格数据\条件筛选表格输出\1032+第三册+第二分册+路基路面.pdf")
N=len(pdf.pages)
print('总共有',N,'页')
def yieldlist( ):
for i in range(249,N):
#print('********************************************************************************************************************************************************')
print('正在搜寻第',str(i+1),'页表格')
#print('********************************************************************************************************************************************************')
p0 = pdf.pages[i]
yield p0
def dojob1(): #此函数没有多线程 直接循环提取表格
k=249
iter=yieldlist( )
#next(iter)
for i in range(k,N):
try:
table = next(iter).extract_table() #利用next方法降低内存占用,逐个提取页面
#print(table)
df = pd.DataFrame(table[1:])
#print(df)
#df.to_excel("1032+第三册+第二分册+路基路面"+str(i+1)+".xlsx","1032+第三册+第二分册+路基路面第"+str(i+1)+'页表格', header=True, index=False) #去掉注释可以把表格保存到excel
print('表格已保存')
del table , df #删除数据,进一步优化内存,实际还是全靠next方法才最有效果
gc.collect()
except Exception as e:
#print(e)
print('该页面无表格,或者检查是否存在表格')
gc.collect()
continue
#print('目前内存占用率是百分之',str(ps.virtual_memory().percent),' 第',str(i+1),'页输出完毕')
#print('**********************************************************************************************************************************************************')
print('\n\n\n')
#print('我是单线程循环,可能会导致内存溢出')
if __name__ == '__main__':
dojob1()
运行效果如下,只显示提取效果,目前无法彻底解决内存满的问题,就得分每次取200页的办法,分开循环提取


















 540
540

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











