




 本文深入探讨了Redis的主从复制机制,包括配置方法、复制流程、数据同步策略(全量与部分同步)、安全性设置、读写分离应用及常见问题处理。通过了解复制偏移量、复制积压缓冲区、主节点ID等概念,掌握高效管理和优化Redis集群的方法。
本文深入探讨了Redis的主从复制机制,包括配置方法、复制流程、数据同步策略(全量与部分同步)、安全性设置、读写分离应用及常见问题处理。通过了解复制偏移量、复制积压缓冲区、主节点ID等概念,掌握高效管理和优化Redis集群的方法。
《redis开发与运维》笔记
主从节点之间的复制,主导从,一对多,单向,
方式:1在配置文件中加入slaveof{masterHost}{masterPort}随启动生效,2命令 --slaveof{ip}{端口}生效。
slaveof是异步命令,执行slaveof后,节点只保存主节点信息后就返回,后续复制流程在节点内部异步执行。复制建立后,可以使用info replication命令查看复制状态。
断开复制:
执行slaveod no one 来断开主从节点的复制关系,但并不会抛弃原来的数据,只是不再更新新的数据。
切换主节点:执行slaveof{newMasterIp}{newMasterPort}命令执行,流程:断开与主节点关系,建立新节点关系,删除从节点当前所有数据,复制新主节点的数据,(重点是切换后会删除从节点之前的所有数据)
安全性:
主节点的数据如果很重要的话,可以设置requriepass参数进行密码验证,防止从节点随便复制数据,从节点的masterauth参数设置与主节点密码保持一致。
只读:
默认情况下,从节点使用slave-read-only=yes配置为只读模式,因为从节点只复制主节点数据,所以不要轻易修改从节点数据,防止数据不一致。
传输延迟:
由于主从节点不是部署在一起的,所以要考虑延迟问题,repl-disable-tcp-nodelay参数用于控制是否关闭TOP_NODELAY,默认关闭,关闭时主节点会实时复制数据到从节点,这样会增加带宽的消耗等问题。开启时,主节点会合并数据包复制给从节点,从而节省带宽,默认发送取决于系统内核,一般40毫秒。
拓扑:一主一从,一主多从,树形。
3,原理
3.1复制过程:
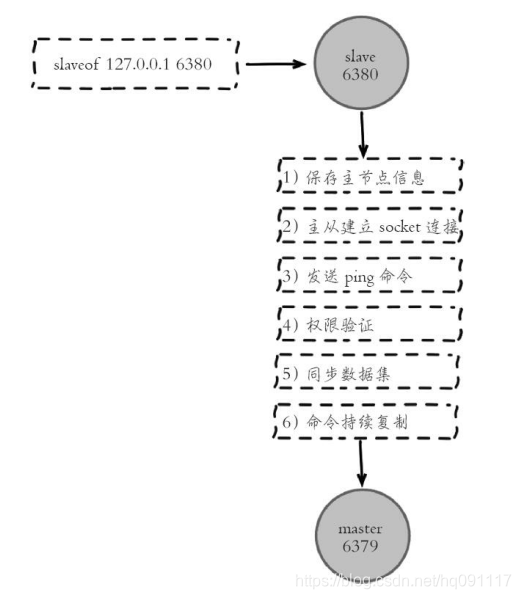
3.2数据同步:全量同步和部分同步(psync命令)
3.2.1部分复制:
用于处理主从复制中因网络闪断等原因造成的数据丢失场景,当从节点再次链接上主节点,条件允许,主节点会补发丢失数据给从节点,避免全量复制的网络开销。提高效率。部分复制是后面版本才有的。
部分复制需要几个条件:
1偏移量:主从节点都会保存自身的复制偏移量,主节点会记录字节长度做累计记录,统计在info relication中的master_repl_offset,从节点也会保存,用info relication查看。通过偏移量可以查看主从是都一致。
2复制积压缓冲区:缓冲区是在主节点上的一个固定队列,默认1M,用于保存最新数据,复制过程中,主节点不会马上把数据复制给从节点,而是先写在缓冲区中,再复制给从节点,队列是先进先出的,所以可以用于复制过程的数据丢失的补救。
3主节点ID
每个redis启动后会生成一个16位的运行ID,用于作为redis的唯一标识,因为当主节点重启后数据变更,但从节点还是根据ip+端口和偏移量来判断数据一致的话明显是不安全的,所以需要运行ID来判断,如果ID变了就进行全量复制。通过info server查看id
重启不改变id:使用debug reload命令来保证id不变,从而避免全量复制。debug reload命令会阻塞当前Redis节点主线程,阻塞期间会生成本地RDB快照并清空数据之后再加载RDB文件。因此对于大数据量的主节点和无法容忍阻塞的应用场景,谨慎使用。
4psync命令:
psync{runID}{offset}:runID运行ID,offset偏移量
3.2.2全量复制:
一般用于初步复制,一次性全部复制,所以网络开销较大,适合在从节点第一次连接主节点的时候必须要做的,触发命令是sync(版本2.8之前)和psync(版本2.8之后)。
流程:
1发送psync命令,由于是第一次,所以命令是psync-1。
2主节点根据-1来执行全量复制,回复+FULLRESYNC响应。
3从节点接到主节点的数据并保存运行ID和偏移量offset。
4主节点执行bgsave命令生成RDB文件,
5从节点接收从主节点发送过来的RDB文件并保存。注意RDB文件大小来适当改变超时时间。
心跳:
主从节点简历链接后,他们之间维护一个长连接并彼此发送心跳命令,主从节点都有判断心跳机制,各自模拟成对方的客户端进行通信,主节点状态flags=M,从节点状态flags=S,主节点默认每10秒发送一次ping命令,判断连接状态,可通过repl-ping-slave-period控制发送频率。从节点每秒发送replconf ack {offset]命令,上报自身的偏移量。
异步复制:
主节点发送写命令是异步完成的,并不等待从节点复制完成,由于异步,所以难免会有数据的延迟,复制速度取决于主从之间的网络环境。命令处理速度等,一般在1秒以内。
实际问题处理:
1读写分离:写主节点读从节点(缺点:数据延迟,过期数据(分实时删除过期数据和轮询),从节点故障)
2避免主从配置不一样
3规避全量复制


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









