




1. 实战概述
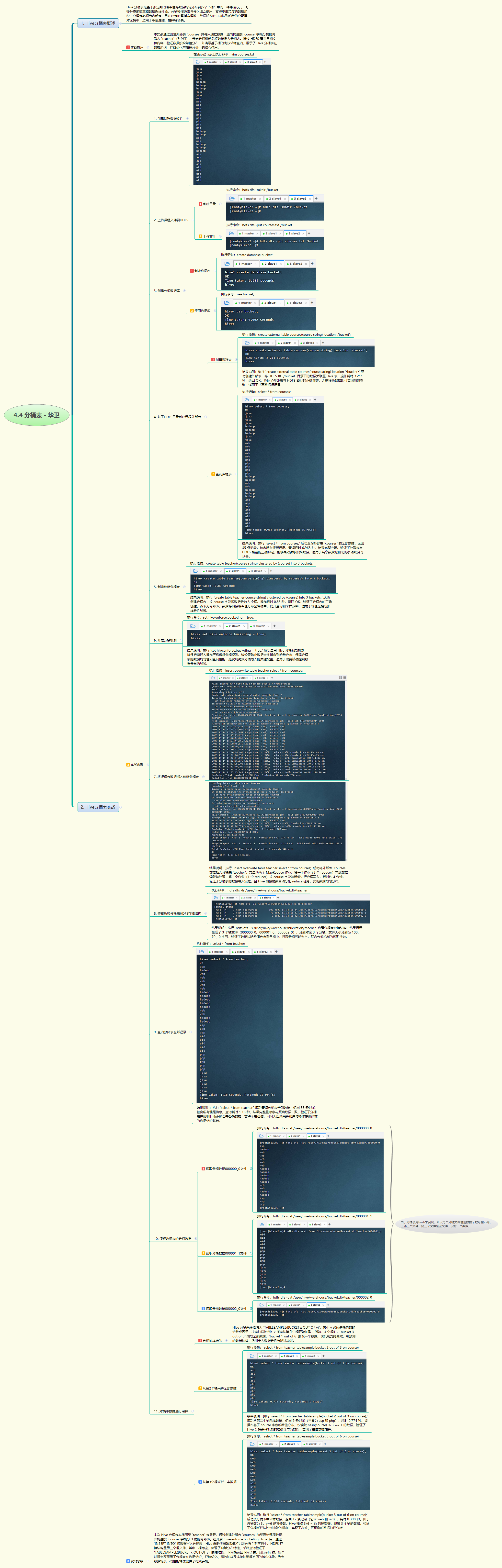
- 本实战通过创建外部表加载课程数据,构建按 course 字段分3桶的内部分桶表,开启分桶机制后插入数据,验证HDFS中数据按哈希值分布至各桶,并通过分桶采样查询展示其在高效抽样与数据组织中的优势,完整体现了Hive分桶表的核心功能与应用场景。
2. 实战步骤
3. 实战总结
- 本次Hive分桶表实战完整实现了从数据准备到分桶应用的全流程。通过创建外部表
courses加载原始课程数据,进而构建按course字段分3桶的内部表teacher,并在开启hive.enforce.bucketing=true后执行数据插入,确保数据依据哈希值均匀分布至各桶。HDFS存储结构验证了三个桶文件的生成,其中部分桶为空,符合哈希分布特性。通过TABLESAMPLE(BUCKET x OUT OF y)语法成功实现精准抽样,如抽取单个桶或按比例采样,显著提升查询效率。整个过程清晰展示了分桶表在数据组织优化、高效抽样分析及后续连接加速等方面的独特优势,为大数据场景下的性能调优提供了可靠实践路径。


















 1577
1577

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











