



 本文介绍了一种使用Transformer进行图像识别的方法,该方法绕过传统的卷积神经网络(CNN),直接在图像块上应用Transformer,实现了良好的分类效果。通过在大规模数据集上的预训练,即使在较小的数据集上也能达到甚至超过现有技术的水平。
本文介绍了一种使用Transformer进行图像识别的方法,该方法绕过传统的卷积神经网络(CNN),直接在图像块上应用Transformer,实现了良好的分类效果。通过在大规模数据集上的预训练,即使在较小的数据集上也能达到甚至超过现有技术的水平。
TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE 论文学习
ABSTRACT
在计算机视觉处理上,注意力机制总是和CNN结合使用,本文主要论证注意力对于CNN不是依赖性的,作者使用单一的transformer在图像的patch块上执行图片分类任务。作者在大数据集上进行预处理并在中小型数据集上进行测试得到了很好的结果(此处作者还在中小型数据集上直接训练结果一般,但却给作者提供很好的思路)
INTRODUCTION
受到自然语言处理的Transformer模型的启发,作者通过很少的修改直接使用Transformer对图像进行训练。首先作者将分为多个patch块(此处减少每次训练图像输入尺寸,减小开销),然后将图像patch块的线性训练输入到Transformer模型中。对图像patch块的处理同NLP中对单词的处理相同。
直接在ImageNet数据集上进行训练的效果比一般的网络的精度要低,但是这也给了作者启发:因为CNN能够提取图像的信息并进行整合,Transformer模型缺少此特点。作者认为是数据集小,数据训练不足造成。接下来作者在更大的数据集 (14M-300M images)上进行实验,发现大规模的训练胜过了CNN归纳的特点。所以作者在大规模的数据集(14M-300M images)上进行预训练,然后在中小规模的数据集上进行训练预测得到很好的结果。
RELATED WORK
众多文献集合
METHOD
因为可扩展的NLP的Transformer模型体系结构高效好用,作者在设计模型时尽可能去贴近原始的Transformer模型。
VISION TRANSFORMER (VIT)
模型图如下:
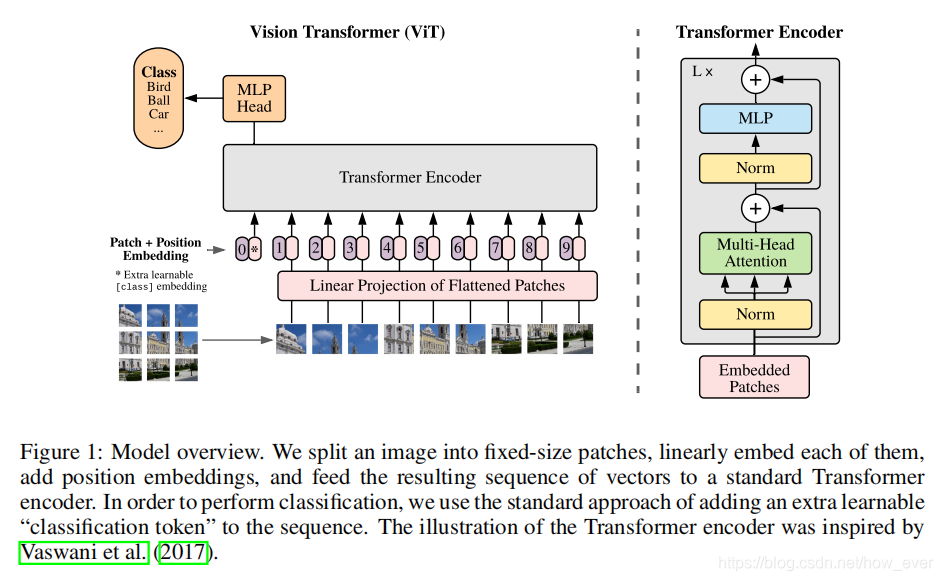
标准的Transformer模型的输入时1D的令牌(单词)序列。为了处理2D图片,首先将图片(
x
∈
R
H
×
W
×
C
x\in R^{H\times W\times C}
x∈RH×W×C)裁成多个2D patch块图像(
x
p
∈
R
N
×
(
P
2
⋅
C
)
x_{p}\in R^{N\times (P^{2}\cdot C )}
xp∈RN×(P2⋅C))其中,(H,W)是原图像分辨率,(P,P)是patch块图像的尺寸,
N
=
H
W
/
P
2
N=HW/P^{2}
N=HW/P2是一张原图像裁成patch的数量,也可以作为Transformer模型的有效输入序列长度。Transformer模型在它所有的层中使用恒定的潜在向量大小的D,所以需要用可训练的线性投影映射到D维(等式1),并将这个投影的输出称为patch embeding。
(此处我没有按照论文的顺序翻译,加入了一些自己的理解)
由于Transformer模型的输入输出向量为固定维度D,所以需要对展平的patch块向量进行映射到D为,并加上位置信息向量
E
p
o
s
E_{pos}
Epos,形成输入变量
z
0
z_0
z0,输入向量序列长度为N。
公式如下:
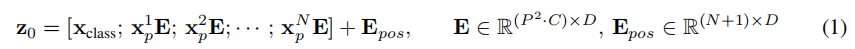
对输入向量在Transformer模型中经历L次MSA和MLP模块处理,标签需进行层归一化处理,公式如下: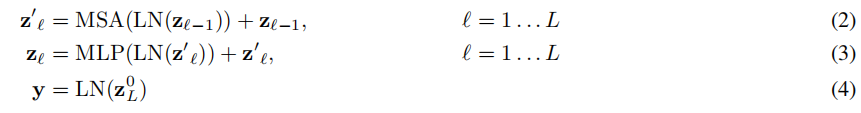
Hybrid Architecture 模型中patch块嵌入向量可以在来自于CNN产生的特征图。比较特殊的情况是只有一个patch块,这意味着对特征图进行展开并送进模型中。
FINE-TUNING AND HIGHER RESOLUTION
模型需要在大型数据集上进行预训练,预训练时需要对模型进行如下操作:首先移除预训练的预测头并初始化D x K前馈层。作者发现使用大分辨率图像进行预处理会产生更好的效果。ViT可以处理不同长度的时序序列,但是相应的位置信息向量也就无意义了,需要对其进行线性插值。
EXPERIMENTS
论文中对ResNet、ViT(Vision Transformer)、ViT变体(先使用CNN提取特征向量,然后再使用Transformer进行分类)
Model Variants. ViT模型变体如下( ViT-L/16 表示“Large” 模型,输入patch块为16*16)
COMPARISON TO STATE OF THE ART
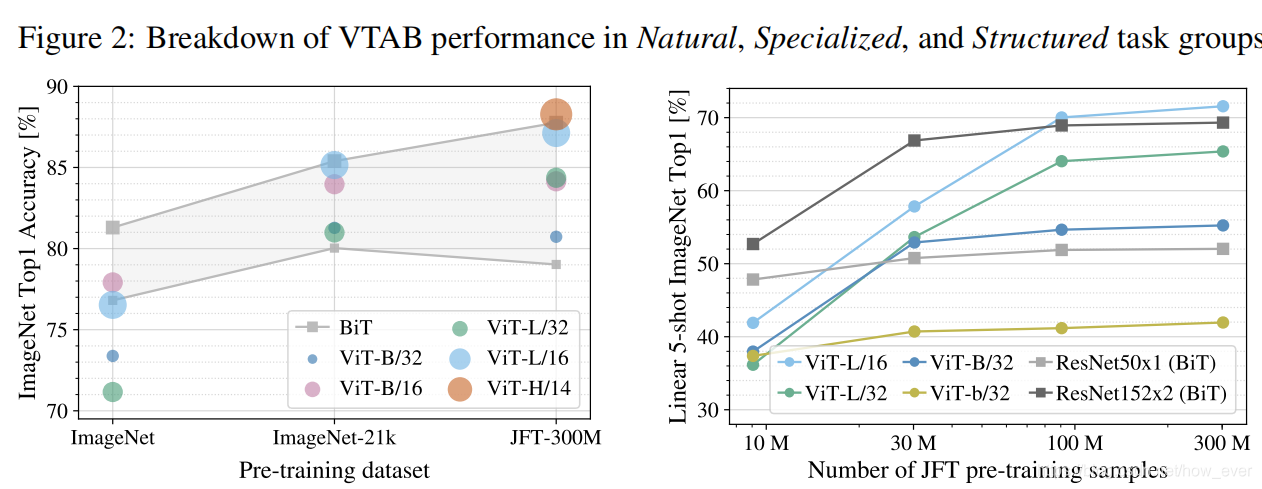
上图所示,在中小型数据集上进行预训练,ViT的结果低于基线,但当在大型数据集上进行预训练,ViT的结果高于基线,由此,注意力机制可以独立于CNN或RNN进行分类或者分割。

















 1823
1823

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









