




1. 共识算法的重要性:分布式系统的"大脑"
在分布式系统中,共识算法扮演着神经中枢的角色,它确保在存在故障和网络问题的环境中,多个节点能够就像单一系统一样协同工作。让我们从一个现实比喻开始:
// 分布式系统就像一支交响乐团
public class OrchestraAnalogy {
// 没有指挥(共识算法)的情况
public void withoutConductor() {
// 小提琴手:我觉得该我们演奏了
// 大提琴手:不,应该我们先开始
// 结果:混乱不堪,各奏各的调
}
// 有指挥(共识算法)的情况
public void withConductor() {
// 指挥(Leader):现在小提琴开始,第三节拍大提琴加入
// 所有乐手(节点)遵循指挥的指令
// 结果:和谐统一的音乐
}
}
2. Paxos算法:理论奠基但工程复杂
2.1 Paxos的历史背景与核心贡献
Paxos算法由Leslie Lamport在1989年提出,1998年正式发表。它解决了分布式系统中如何就某个值达成一致的问题,是第一个被证明正确的共识算法。
/**
* Paxos算法的核心价值:证明了分布式共识的可能性
* 在异步分布式系统中,即使存在节点故障、消息丢失、网络延迟,
* 仍然可以达成一致性决策。
*/
public class PaxosHistoricalSignificance {
// Paxos解决的问题场景
public void problemScenario() {
// 假设:5个节点的分布式系统
Node[] nodes = {node1, node2, node3, node4, node5};
// 挑战:节点可能故障,消息可能丢失或乱序
// 目标:所有正常节点就某个值达成一致
// Paxos证明:只要多数派节点正常,就能达成共识
int quorum = nodes.length / 2 + 1; // N/2 + 1原则
}
}
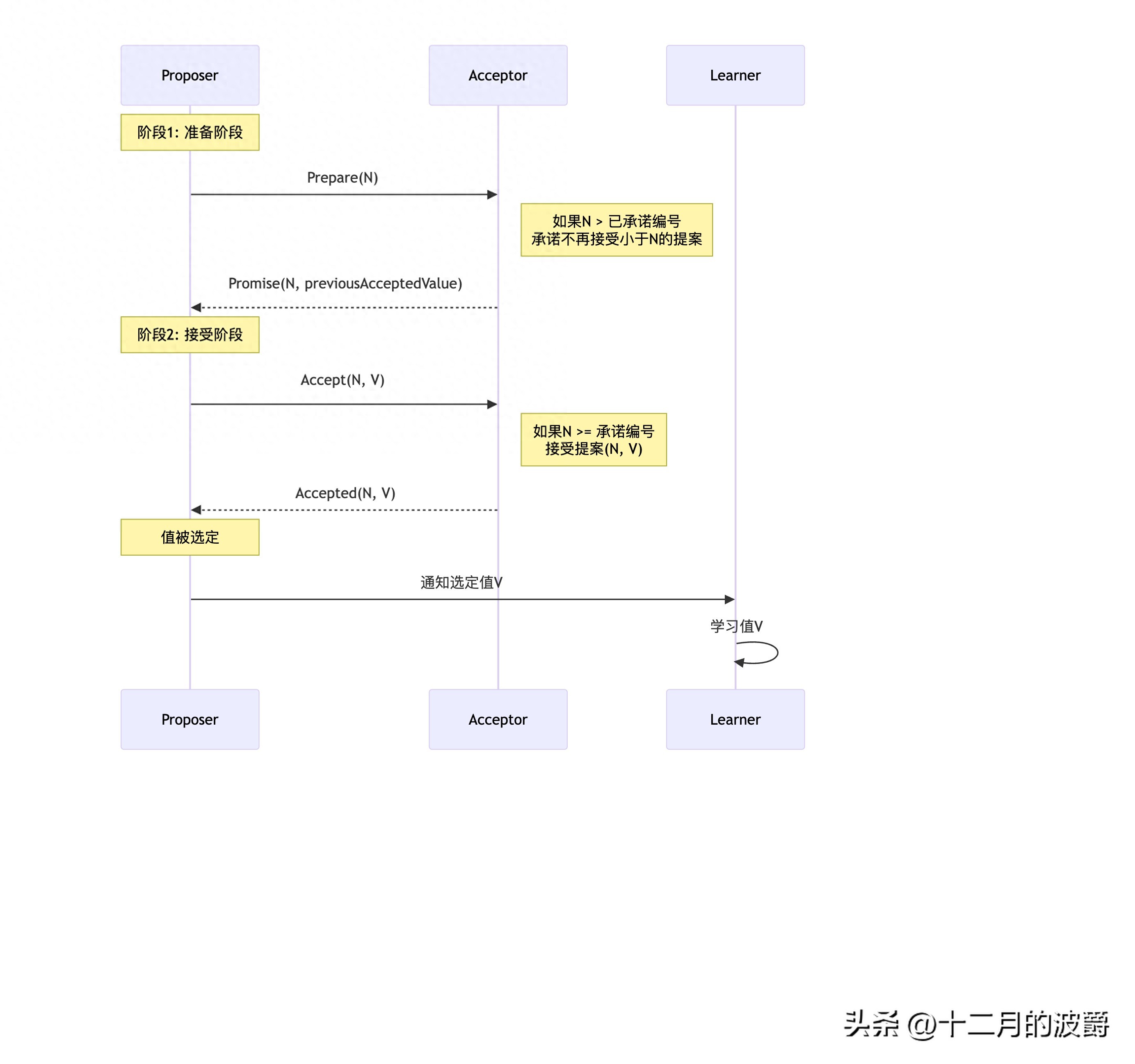
2.2 Paxos算法核心流程详解
三种角色定义
public class PaxosRoles {
// 1. Proposer(提议者):提出提案
public class Proposer {
private long proposalNumber; // 全局唯一且递增的提案编号
public void propose(Object value) {
proposalNumber = generateUniqueNumber();
// 阶段1:准备阶段,争取提案权
preparePhase(proposalNumber);
}
}
// 2. Acceptor(接受者):对提案进行投票
public class Acceptor {
private long promisedNumber = 0; // 已承诺的提案编号
private Object acceptedValue = null; // 已接受的值
public PromiseResponse onPrepare(long proposalNum) {
if (proposalNum > promisedNumber) {
promisedNumber = proposalNum;
return new PromiseResponse(true, acceptedValue);
}
return new PromiseResponse(false, null);
}
}
// 3. Learner(学习者):学习被选定的值
public class Learner {
public void learnChosenValue(Object value) {
// 一旦值被选定,所有Learner学习这个值
System.out.println("学习到选定值: " + value);
}
}
}
两阶段协议详细流程
2.3 Paxos的工程挑战与复杂性
public class PaxosEngineeringChallenges {
// 1. 活锁问题(Livelock)
public void livelockProblem() {
while (true) {
// Proposer A: 提出编号为1的提案
// Proposer B: 提出编号为2的提案(中断A)
// Proposer A: 提出编号为3的提案(中断B)
// Proposer B: 提出编号为4的提案(中断A)
// ... 无限循环,无法达成决议
}
}
// 2. 实现复杂性
public void implementationComplexity() {
// 基础Paxos只能确定一个值,实际系统需要多Paxos实例
// 需要处理:日志压缩、成员变更、快照等扩展功能
// 每种扩展都有复杂的边界情况需要处理
}
// 3. 调试困难
public void debuggingDifficulty() {
// 角色动态变化:节点可能同时是Proposer和Acceptor
// 消息流复杂:多轮通信,状态转换难以跟踪
// 缺乏直观的运行时状态展示
}
// 4. 实际系统中的Paxos变种
public enum PaxosVariants {
MULTI_PAXOS, // 多Paxos,优化连续提案
FAST_PAXOS, // 快速Paxos,减少通信轮数
BYZANTINE_PAXOS, // 拜占庭容错Paxos
CHEAP_PAXOS // 廉价Paxos,容忍更多故障
}
}
2.4 Paxos的成功应用案例
尽管复杂,Paxos在大型系统中取得了成功:
// Google Chubby锁服务中的Paxos实现
public class GoogleChubbyPaxos {
// Chubby使用Multi-Paxos优化连续写入
public class ChubbyCell {
private List<Replica> replicas; // 5个副本
private Replica master; // Master节点(Leader)
public void writeOperation(String key, String value) {
// Master使用Paxos序列化所有写操作
long sequenceNumber = master.getNextSequence();
// 通过Paxos协议复制到多数派
PaxosInstance paxos = new PaxosInstance(sequenceNumber);
paxos.propose(new WriteCommand(key, value));
// 多数派确认后返回客户端
}
}
}
Paxos的应用成就:
- Google Chubby:分布式锁服务,支撑BigTable等系统
- Amazon DynamoDB:使用Paxos进行元数据管理
- Microsoft Azure:存储服务的基础共识协议
3. Raft算法:为工程实践而生的共识算法
3.1 Raft的设计哲学与目标
Raft算法由Diego Ongaro和John Ousterhout在2014年提出,明确目标是可理解性。作者通过用户研究表明,Raft比Paxos更容易被理解和实现。
public class RaftDesignPhilosophy {
// 设计原则:分解问题
public void problemDecomposition() {
// 将共识问题分解为三个相对独立的子问题:
// 1. 领导者选举(Leader Election)
// - 故障检测与新的Leader选举
// 2. 日志复制(Log Replication)
// - Leader管理日志复制到Followers
// 3. 安全性(Safety)
// - 确保状态机安全性约束
}
// 设计原则:减少状态空间
public void reduceStateSpace() {
// Paxos:角色动态变化,状态复杂
// Raft:明确的状态机,易于理解
enum NodeState {
FOLLOWER, // 追随者
CANDIDATE, // 候选人
LEADER // 领导者
}
}
}
3.2 Raft核心概念详解
节点状态与转换
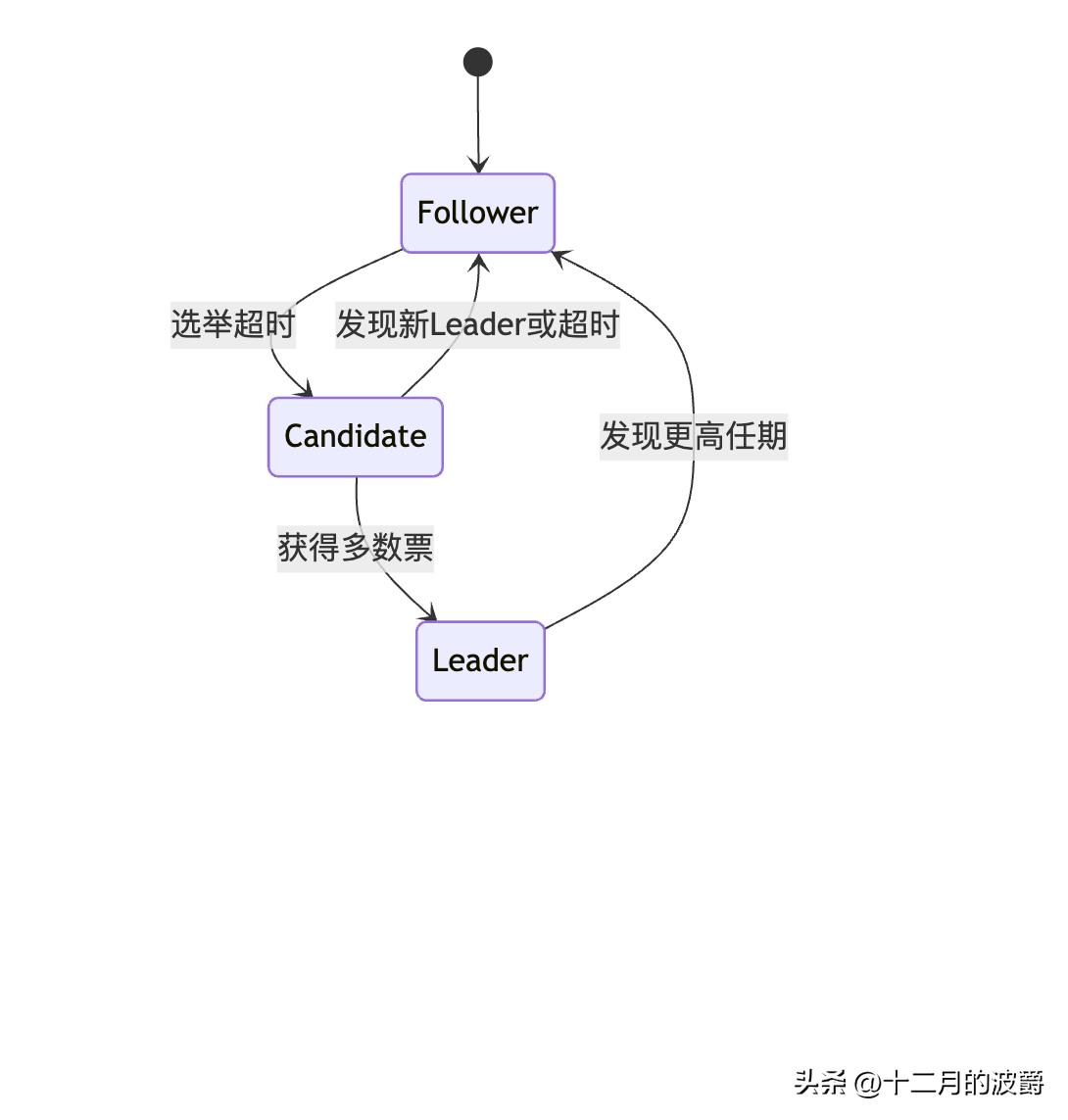
任期(Term)概念
public class RaftTermConcept {
// 任期是Raft的核心时间概念
public class Term {
private long termNumber; // 单调递增的任期编号
private Node leader; // 该任期的Leader(可能为空)
// 每个任期最多有一个Leader
// 有的任期可能没有Leader(选举失败)
}
// 任期的生命周期
public void termLifecycle() {
// 开始:选举阶段(多个Candidate竞争)
// 中期:正常操作阶段(Leader处理请求)
// 结束:新的选举触发(Leader故障或任期结束)
}
}
3.3 Raft算法完整流程
领导者选举详细过程
public class RaftLeaderElection {
// Follower的行为
public class Follower {
private long electionTimeout = 150 + random.nextInt(150); // 150-300ms
public void onElectionTimeout() {
// 1. 增加当前任期
currentTerm++;
// 2. 转换为Candidate状态
state = NodeState.CANDIDATE;
// 3. 给自己投票
voteForSelf();
// 4. 向其他节点发送RequestVote RPC
sendRequestVoteToAllNodes();
// 5. 等待投票结果
startElectionTimer();
}
}
// 投票规则
public class VotingRules {
public boolean shouldGrantVote(CandidateRequest request) {
// 规则1:每个节点在每个任期只能投一票
// 规则2:只投票给日志至少和自己一样新的候选者
// 规则3:先到先得(基于任期和日志索引)
return request.getTerm() > currentTerm &&
request.getLastLogIndex() >= getLastLogIndex();
}
}
}
日志复制机制
public class RaftLogReplication {
// Leader的日志复制流程
public class Leader {
public void replicateLog(LogEntry entry) {
// 1. 将条目追加到本地日志
log.append(entry);
// 2. 并行发送AppendEntries RPC给所有Followers
for (Follower follower : followers) {
sendAppendEntries(follower, entry);
}
// 3. 等待多数派确认
waitForMajorityAck();
// 4. 提交条目(应用到状态机)
commitEntry(entry);
// 5. 通知Followers提交
notifyFollowersToCommit(entry);
}
}
// 日志一致性保证
public class LogConsistency {
// Raft通过两个性质保证日志一致性:
// 性质1:如果不同日志中的两个条目有相同的索引和任期,则存储相同的命令
// 性质2:如果某个日志条目在给定索引位置被提交,那么所有更高索引位置的条目都相同
}
}
3.4 Raft的安全性保证
public class RaftSafetyGuarantees {
// 选举限制(Election Restriction)
public class ElectionRestriction {
// 只有包含所有已提交日志的节点才能成为Leader
public boolean isEligibleForLeader(Node node) {
return node.getLastLogTerm() > getLastLogTerm() ||
(node.getLastLogTerm() == getLastLogTerm() &&
node.getLastLogIndex() >= getLastLogIndex());
}
}
// 提交规则(Commit Rule)
public class CommitRule {
// Leader只能提交当前任期的日志条目
// 通过提交当前任期的条目来间接提交之前任期的条目
public void commitLogEntry(LogEntry entry) {
if (entry.getTerm() == currentTerm) {
// 可以直接提交
commitIndex = entry.getIndex();
} else {
// 需要间接提交:提交当前任期的条目时,之前的条目也被提交
}
}
}
}
4. 从Paxos到Raft:为什么Raft更适合工程实践?
4.1 可理解性对比
public class UnderstandabilityComparison {
// Paxos的学习曲线
public void paxosLearningCurve() {
// 第1周:理解基础Paxos(困难)
// 第2周:理解Multi-Paxos(更困难)
// 第3周:理解各种边界情况(极其困难)
// 结果:多数开发者只能掌握皮毛
}
// Raft的学习曲线
public void raftLearningCurve() {
// 第1天:理解领导者选举(容易)
// 第2天:理解日志复制(中等)
// 第3天:理解安全性保证(中等)
// 结果:多数开发者能深入理解并实现
}
// 实际证据:Raft论文中的用户研究
public void userStudyResults() {
// 研究对象:43名斯坦福大学学生
// 学习Paxos后测试:平均正确率30%
// 学习Raft后测试:平均正确率90%
// 结论:Raft显著更易理解
}
}
4.2 实现复杂度对比
// Paxos实现的核心复杂性
public class PaxosComplexity {
// 1. 角色管理的复杂性
public class PaxosRoleManagement {
// 节点同时扮演Proposer、Acceptor、Learner角色
// 需要维护复杂的内部状态
private Map<Long, Proposal> pendingProposals; // 进行中的提案
private Map<Long, Promise> promisesMade; // 做出的承诺
private Map<Long, Accept> acceptsReceived; // 收到的接受
}
// 2. 消息处理的复杂性
public void handlePaxosMessage(Message msg) {
switch (msg.getType()) {
case PREPARE:
// 处理准备请求
handlePrepare(msg);
break;
case PROMISE:
// 处理承诺响应
handlePromise(msg);
break;
case ACCEPT:
// 处理接受请求
handleAccept(msg);
break;
case ACCEPTED:
// 处理已接受响应
handleAccepted(msg);
break;
// ... 更多消息类型
}
}
}
// Raft实现的相对简单性
public class RaftSimplicity {
// 1. 明确的状态机
public enum RaftState {
FOLLOWER, // 只响应RPC请求
CANDIDATE, // 发起选举
LEADER // 管理日志复制
}
// 2. 简化的消息类型
public void handleRaftMessage(Message msg) {
switch (msg.getType()) {
case APPEND_ENTRIES:
handleAppendEntries(msg);
break;
case REQUEST_VOTE:
handleRequestVote(msg);
break;
// 只有两种主要RPC类型!
}
}
}
4.3 运维调试友好性对比
public class OperationalComparison {
// Paxos的运维挑战
public class PaxosOperationalChallenges {
// 问题诊断困难:
// - 哪个Proposer在活跃?不清楚
// - 当前进行到哪个阶段?难以确定
// - 为什么提案卡住?需要深入分析内部状态
}
// Raft的运维优势
public class RaftOperationalAdvantages {
// 清晰的运行时状态:
private RaftState currentState; // 当前状态明确
private long currentTerm; // 当前任期明确
private Node currentLeader; // 当前Leader明确
// 易于监控的指标:
public void exportMetrics() {
metrics.record("raft.state", currentState.ordinal());
metrics.record("raft.term", currentTerm);
metrics.record("raft.commit_index", commitIndex);
// 这些指标直观反映系统健康状态
}
}
}
5. Raft在现实系统中的成功应用
5.1 etcd:Kubernetes的分布式存储引擎
// etcd中Raft的实现应用
public class EtcdRaftImplementation {
// etcd的Raft节点配置
public class EtcdRaftNode {
private RaftNode raftNode;
private WAL writeAheadLog; // 预写日志
private Snapshotter snapshotter; // 快照管理
public void start() {
// 初始化Raft状态机
raftNode = new RaftNode(config);
// 启动选举定时器
startElectionTimer();
// 处理RPC消息循环
startMessageLoop();
}
}
// etcd的键值存储基于Raft共识
public class EtcdKVStore {
public void put(String key, String value) {
// 1. 客户端请求发送到Leader
if (!isLeader()) {
redirectToLeader();
return;
}
// 2. 通过Raft协议复制日志条目
LogEntry entry = new LogEntry(Operation.PUT, key, value);
raftNode.propose(entry);
// 3. 多数派确认后提交
waitForCommit(entry.getIndex());
// 4. 应用到状态机
applyToStateMachine(entry);
}
}
5.2 Consul:服务发现与配置管理
// Consul使用Raft进行领导者选举和一致性保证
public class ConsulRaftUsage {
// Consul服务器的Raft配置
@Configuration
public class ConsulRaftConfig {
@Bean
public RaftConfig raftConfig() {
return RaftConfig.builder()
.electionTimeout(Duration.ofMillis(1000))
.heartbeatTimeout(Duration.ofMillis(500))
.commitTimeout(Duration.ofMillis(100))
.snapshotInterval(120000) // 2分钟快照
.build();
}
}
// 服务注册的Raft共识流程
public class ServiceRegistration {
public void registerService(Service service) {
// 1. 创建注册命令
RegisterServiceCommand cmd = new RegisterServiceCommand(service);
// 2. 通过Raft复制命令
Future<Object> future = raft.apply(cmd);
// 3. 等待多数派确认
Object result = future.get(5, TimeUnit.SECONDS);
// 4. 注册成功
log.info("Service {} registered with consensus", service.getName());
}
}
}
5.3 TiDB:分布式数据库的共识层
// TiDB使用Raft进行数据分片的多副本一致性
public class TiDBRaftUsage {
// Region(数据分片)的Raft组
public class RegionRaftGroup {
private List<Store> stores; // 3或5个副本
private RaftGroup raftGroup;
public void writeData(byte[] key, byte[] value) {
// 1. 客户端请求发送到Region Leader
// 2. Leader通过Raft协议复制日志
// 3. 多数派确认后响应客户端
}
}
// Raft在TiDB中的优化
public class TiDBRaftOptimizations {
// 1. 批量提交:合并多个写操作为一个Raft日志
// 2. 流水线复制:并行处理多个RPC请求
// 3. 领导者转移:平滑切换Leader减少服务中断
}
}
6. 从Paxos到Raft:技术演进的启示
6.1 算法设计的范式转变
public class ParadigmShift {
// Paxos的设计哲学:数学正确性优先
public class PaxosPhilosophy {
// 关注点:理论正确性、最大灵活性
// 假设:聪明的实现者能处理复杂性
// 结果:理论上优美,工程上困难
}
// Raft的设计哲学:工程实用性优先
public class RaftPhilosophy {
// 关注点:可理解性、易实现性
// 假设:清晰的规范比灵活性更重要
// 结果:易于理解实现,迅速普及
}
// 启示:优秀的算法应该考虑人的因素
public void humanFactors() {
// 可理解性 > 理论优美性
// 易实现性 > 最大灵活性
// 可调试性 > 性能极致优化
}
}
6.2 对分布式系统设计的启示
public class DistributedSystemInsights {
// 启示1:分解复杂性
public void decomposeComplexity() {
// Raft成功的关键:将复杂问题分解为相对独立的子问题
// 应用:将大型系统拆分为微服务,每个服务职责单一
}
// 启示2:明确抽象边界
public void clearAbstractionBoundaries() {
// Raft的明确状态和角色比Paxos的动态角色更易理解
// 应用:系统设计时定义清晰的接口和边界
}
// 启示3:重视可观测性
public void importanceOfObservability() {
// Raft的明确状态便于监控,Paxos的内部状态难以观察
// 应用:系统设计时内置可观测性,便于运维调试
}
}
7. 总结:共识算法的未来演进
从Paxos到Raft的演进体现了分布式系统理论向工程实践的转变。当前共识算法仍在不断发展:
public class FutureEvolution {
// 当前研究方向
public enum ResearchDirections {
LEADERLESS_CONSENSUS, // 无领导者共识(如EPaxos)
BYZANTINE_RAFT, // 拜占庭容错的Raft变种
PERFORMANCE_OPTIMIZATION, // 性能优化(如并行Raft)
CROSS_REGION_CONSENSUS // 跨地域共识优化
}
// 实践中的持续改进
public class PracticalImprovements {
// 1. 自动化运维:自愈合、自调整的Raft集群
// 2. 混合共识:结合Paxos和Raft优势的新算法
// 3. 硬件加速:利用RDMA、NVMe等新硬件特性
}
}
核心结论:
- Paxos奠定了分布式共识的理论基础,证明了可能性
- Raft通过可理解的设计,让共识算法真正走向工程实践
- 从Paxos到Raft的演进,体现了"为人类设计"的工程思维重要性
- 选择Raft不是因为它在理论上更优,而是因为它在实践中更有效
对于大多数分布式系统,Raft是目前的最佳选择。它平衡了正确性、性能和可理解性,为构建可靠的分布式系统提供了坚实的基础。


















 168万+
168万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











