




 本文介绍了汇编语言的基本概念,强调了数据进栈与出栈在存储管理中的作用,以及可移动寻址的重要性。通过实例展示了如何利用栈进行数据处理,并探讨了限制操作,如栈操作的规则和寻址方式。文章还提到了汇编语言中段地址和偏移地址的概念,以及不同寻址模式的应用场景。
本文介绍了汇编语言的基本概念,强调了数据进栈与出栈在存储管理中的作用,以及可移动寻址的重要性。通过实例展示了如何利用栈进行数据处理,并探讨了限制操作,如栈操作的规则和寻址方式。文章还提到了汇编语言中段地址和偏移地址的概念,以及不同寻址模式的应用场景。
关于汇编语言的阅读笔记
什么是汇编语言
一般来说对于通过编译器的高级语言如:c,c++等等都是面向人类《即让人类能够看懂的语言。但汇编语言则完全不同,在汇编语言中,它最主要的是面向机器来说的,而机器则完全是通过一大段1 0的二进制(机器语言)来实现数据的沟通的,那么显然的是,汇编语言就是将其 1 0 (机器语言)进行得出结论同时进行操控的。
数据进栈与出栈的运用
有时对于数据存储我们总是搞不懂我们将应该是数据储存在何处,如何进行对于存储数据进行提取。
首先,我们应该明白对于数据存储位置的选择不是一个简单的问题,假如我们将数据存储于我们认为的一份空间,那么空间所存储的数据必将被覆盖,这一部分数据的丢失可能会造成严重的后果,例如某一进程停止,系统工作强制结束,数据丢失。这显然不是我们想要达成的效果,所以选择一个好的优秀的空闲的空间去储存我们所要储存的数据是一个明智的选择。
但如何选择这样一个空间呢,假如你不想一个一个空间去查询,那么通过系统运行时,所自动存储是一个极其明智的选择。栈,一个对于数据处理非常有效的处理方式。 在汇编语言中,栈的运用同样是一种简单高效的做法,在对于数据的输入时,它的功能将首先进入的数据首先存储于栈底,后入的数据位于栈顶,提取数据时后入数据先出,先入数据后出。
//段地址,可以理解为某地某一显著建筑,偏移地址,
可以理解为在这显著建筑向东或向西走多少米。
//之所以不用bx直接表示偏移地址,是为了为以后操作方便留下
操作空间。
assume cs:codesg,ds:datasg,ss:stacksg
datasg segment
//在定义字符串时,为了使得我们所存储的数据连续存储,
特地的将其扩展为16字节,这样可以将其看作是一个4行
16列的二位数组。
db 'bcwue '
db 'fched '
db 'cwecs '
db 'csrgg '
datasg ends
stacksg segment //定义一个段,用来做栈段,空间为16字节。
dw 0,0,0,0,0,0,0,0
stacksg ends
codesg segment
start: mov ax,stacksg //这里不直接进行数据的移动,同样是规定。
mov ss,ax
mov sp,16
mov ax,datasg
mov ds,ax
mov bx,0
mov cx,4
s0: push cx //入栈,将cx数值存储于栈的空间中。
mov si,0 //使si变量为0
mov cx,5 //5个字母
s: mov al,[bx+si]
//bx+si 首先将段地址在ds,偏移地址为bx+si,通过这样
的方式我们可以得到·1一个具体数据存储的位置。将这个
位置的数据传输于al。在这里ds与bx都是一个固定不动
的数值,但si是不断变化的,这就意味着在整个循环中,
对于al数据的传输,所要取得数据是不同的,是来自
不同空间地址的。
and al,11011111b
//之所以不将[bx+si]直接与11011111b直接和运算,是因为
这样的操作是不被允许的。只有将某一数据真正存储于存储器
中,才可以进行如下操作。
//and or ,在汇编语言中与其他列如C语言一样,都是0与1
的不断变换 1 and 0 =0,1 or 0 =1
mov [bx+si],al
inc si //inc 即 si+1
loop s
//loop循环结尾,在系统将测到cx为0时,循环结束,但若
不为0,循环继续,在每次循环完成后cx减一。
add bx,16
//add 即加法运算 ,bx+16,即在bx空间的基础上
再加上16字节,改变偏移地址,即指向下一行
pop cx //出栈,将cx数值出栈,以期完成二重循环的运用
loop s0
mov ax,4c00H //这两行是结尾的固定格式记住记住就可以了/
int 21H
codesg ends
end start //在end的使用方面,end不光是对于某段的
结尾,同样是对于程序运行时,以某段开始的标志。例如,在
debug运行中,如果将测到start,那么就知道,程序将会
从此刻开始。
可移动寻址的重要性
承接上文,在对于内存进行处理时,我们总要找到某一特定的地址进行编辑修改,这是寻求地址的存在就显得尤其重要。尽管我们总是想要处理这些操作,但每次进行数据操作时就要不断地记忆,并输出这些地址,显然这是不可能的。那么取得一个变量,让其变得可移动,可编程就显得尤为重要。就如上文所说的‘SI’它就是一个变量的存在。
为了便于记忆:
直接寻址 idata
寄存器间接寻址 bx,si,di,bp
寄存器相对寻址 bx,si,di,bp+idata
基址变址寻址 bx,bp+si,di
相对基址变址寻址 bx,bp+si,di+idata
举例偷个懒:
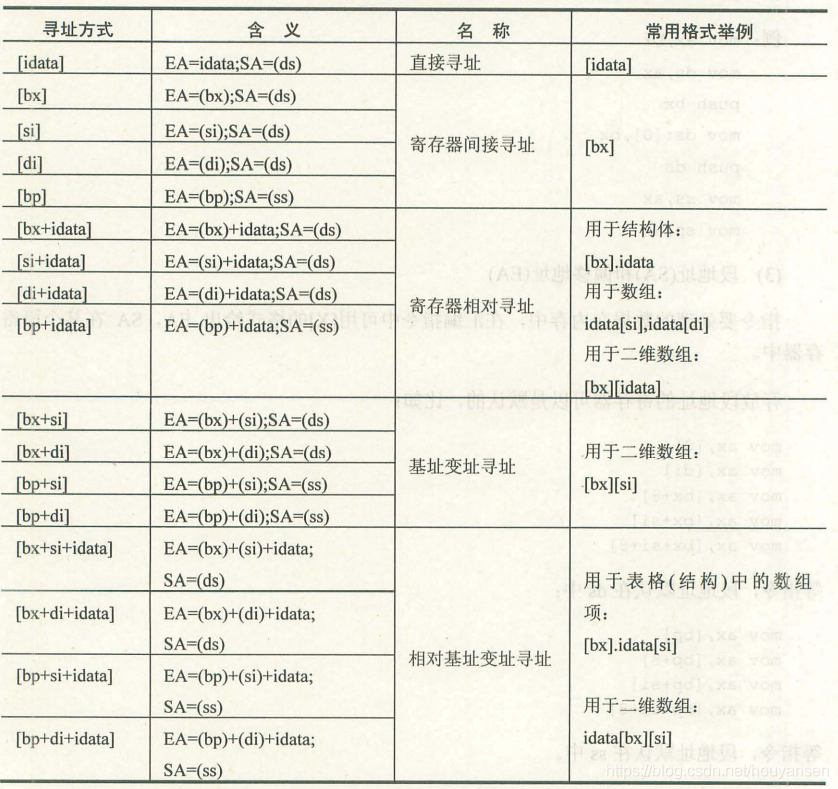
通过上述图片所示,我们很容易地可以看到,如果我们有一明确单一地址可以查询,显然直接寻址是省时省力的。但凡事都有个但是,例如在一个循环操作(LOOP)中,我们为了简化操作方式,不至于一步一步的不断地要求修改才进行操作。
之所以把这些所有的操作都一一列举出来是为了,区分两种操作。一是段操作,二是段间操作。所谓段操作,我们都知道有栈段,数据段等等,在对这些段进行例如空间的分配时,进行制空操作。而段间操作,则是在进行数据的处理加工后,将数据添加至某段,而在这些操作中,移动寻址便可以大大加强操作的可行性。
限制操作
1.我们要知道,虽然在设计相关系统时用的是二进制表达,但在debug运用中,其使用十六进制进行表达的。
2.在任意时刻 将段地址寄存器SS和偏移地址寄存器SP所组合出来的内存地址当作栈顶标记
入栈:sp= sp-2
出栈:sp= sp+2
3.在入栈,出栈操作中,为16位寄存器中进行传输,字型数据
push ax bx cx
4.在寄存器的相关的运用中,16位寄存器只能够与16位寄存器进行相关操作,而8位只能与8位进行操作
5.对于栈段的运用,可自行定义相关空间长度与位置SP寄存器变化范围 0-FFFFH,实际运用应适当。
6.对于栈段的内容,我们应该注意在栈段没有使用的空间位置中会对CS,IP,BP等数据进行存储。
7.寄存器是相互独立的。例如,在al进位后,1不能存储于ah。
8.指令执行的过程:
CPU从CS:IP所指向的内存单元读取指令,存储于指令缓存器中
IP=IP+所读指令的长度,从而指向下一条指令
执行指令缓存中的内容,返回步骤1
9.对于字形数据与字节型数据的处理要研习分清。字单元 mov word ptr ds:[0],1
字节单元 mov byte ptr ds:[0],1
X ptr 知名内存单元长度。
//期望对您有所帮助。

















 1316
1316

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









