




看完这篇文章,你将会学习到:为什么要压缩图像数据、图像数据为什么能压缩
讲到这里,我们已经来到了这个系列文章的一个转折点。因为从这篇文章开始,我们开始介绍视频数据的编解码技术,这也是这个系列的其中一个目标。
在介绍MPEG之前,我们先来对接一下前面的内容,找到一个起承转合的衔接点,也方便找到学习路径,形成知识体系。
我们在讲YUV和YCbCr的时候,曾分析过电视系统中,颜色空间的转换。如下图:
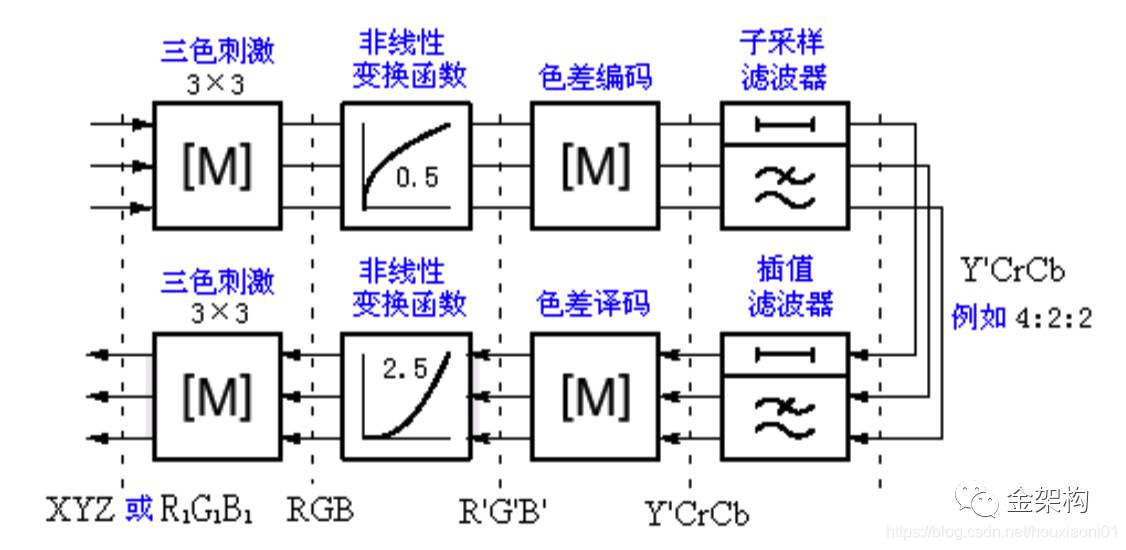
首先摄像机通过摄像头采集,获取图像的RGB数据,这个在音视频开发中也称为原始数据,或者RGB像素数据,因为它是未经压缩的,也没经过任何处理得来的数据。接下来通过颜色空间转换、伽玛校正、色差编码得到YCbCr像素数据,也称为YUV数据。
但是接下来还没完,因为我们现在都是数字电视,所以需要把图像数字化,也就是需要对YUV数据进行子采样,然后才能得到YCbCr的子采样格式数据,这里如果是SDTV,则是按照ITU-R BT.601的标准进行的子采样,子采样格式为4:2:2。
1、为什么要压缩图像数据
这也就是到目前为止,我们掌握的内容。但是到现在为止,我们依然不能把这种原始数据,发送到通信通道上传输出去,因为它的数据量实在是太大。那么经过子采样过后的数据到底有多大呢?让我们来计算一下它所需的数据传输率,也即每秒传输的比特数(位/秒,bps),也即通俗意义上所需的带宽。
因为ITU-R BT.601确定了PAL、NTSC、SECAM彩色电视制共同的数字化参数,所以我们现在就按照ITU-R BT.601标准,来计算一下它所需的数据传输率。如果大家还没忘的话,它的采样格式为:4:2:2,Y采样频率为13.5MHz,Cb和Cr的采样频率为6.75MHz,每个样本的精度为10位。这样它的数据传输率为:
Y:
858样本/行 X 525行/帧 X 30帧/秒 X 10位/样本 ≈ 135Mbps (NTSC)
864样本/行 X 625行/帧 X 25帧/秒 X 10位/样本 ≈ 135Mbps (PAL)
Cb:
429样本/行 X 525行/帧 X 30帧/秒 X 10位/样本 ≈ 68Mbps (NTSC)
432样本/行 X 625行/帧 X 25帧/秒 X 10位/样本 ≈ 68Mbps (PAL)
Cr:
429样本/行 X 525行/帧 X 30帧/秒 X 10位/样本 ≈ 68Mbps (NTSC)
432样本/行 X 625行/帧 X 25帧/秒 X 10位/样本 ≈ 68Mbps (PAL)
因为它的采样格式为4:2:2,所以平均一个像素需要两个样本来显示,那么它的总数据传输率为:
采样频率 * 2 * 10 = 13.5MHz * 2 * 10位/样本 = 270Mbps。
这样就可以直观的感受到,270Mbps简直大的不行,即使今天,我们家用的带宽也只是2Mbps~100Mbps。而且即使考虑到显示器的有效图像的数据传输率,和把每个样本10位,降到8位,数据传输率计算出来也得166Mbps。所以很显然,这个数据是非压缩不可的。
那既然这样,我们就来看看,视像(电视图像)为什么能压缩呢?之前我们只是说人眼对亮度的敏感度要强,这是站在我们自己的立场上来分析,下面我们就来全面的分析下,要压缩视像数据,都可以从哪些方面入手。
2、为什么图像数据能压缩
视像数据之所以能被压缩,是因为视像数据中,存在大量的冗余数据。它包括时间冗余、空间冗余、结构冗余、视觉冗余、知识冗余和数据冗余。下面我们一一介绍
(1)时间冗余
在某个时间间隔上,出现场景相同或基本相同的连续帧时,帧与帧之间存在大量的冗余数据。这些与时间相关的冗余称为时间冗余。这个应该很好理解,比如我们看电视,一个人站在那不动,镜头给了好几秒,那么这几秒包含的这么多帧数据,基本上90%是重复的,所以压缩空间很大。
(2)空间冗余
在单帧图像中,相邻像素的值常有相同或变化不大的情况,可用较少的数据表达这些像素的值。这种冗余与像素的空间位置有关,因此称为空间冗余。比如一人站在冰天雪地里,漫天雪白,那么基于像素来讲,它相邻的像素值都和它差不多,所以这时不记录相邻像素值也可以。
(3)结构冗余
如果从宏观上来看一帧图像,有些图像存在着相同或类似的结构,比如一帧图像,是由一堆矩形图案构成的,那么这种因为图像自身的构造所造成的冗余,就叫结构冗余。
(4)视觉冗余
这就是之前说的,人眼对亮度要比色度更敏感,不过人的视觉系统还有许多特性。比如人眼对图像中,剧烈变化的边缘区域敏感,但是对缓慢变化的非边缘区域不敏感,可以想想人物的肖像画,我们对轮廓的把握要比对背景的敏感度要强。还有就是人眼对亮度和色度的分辨率都存在极限,之前说过,普通人能识别的颜色也就三百种左右。因此这些与视觉系统有关的冗余,就叫做视觉冗余。
(5)知识冗余
在单帧图像中,往往含有为人熟知的知识,通常把这些知识称为先验知识。这里的知识,其实就是我们意识里的概念。比如还是以人像为例,人眼下面是鼻子,鼻子下面就是嘴,嘴和鼻子都位于脸的中线上。像这样的结构往往比较有规律,并且不会变化。所以在电视图像数据中,这些就属于重复的数据,所以这种人人熟知的,或者是事实、或者概念,这些被称为知识冗余,意思是我们知道它是这样的。
(6)数据冗余
这种冗余,是在去掉或减少以上1-5的冗余数据之后,留下的数据本身同样存在冗余。注意它的分析对象不是人眼、也不是图像的内容、或者连续帧的内容,而是图像的数据本身产生的冗余。去掉这些多余的数据,不会丢失任何信息。
下表为一个归纳概括:
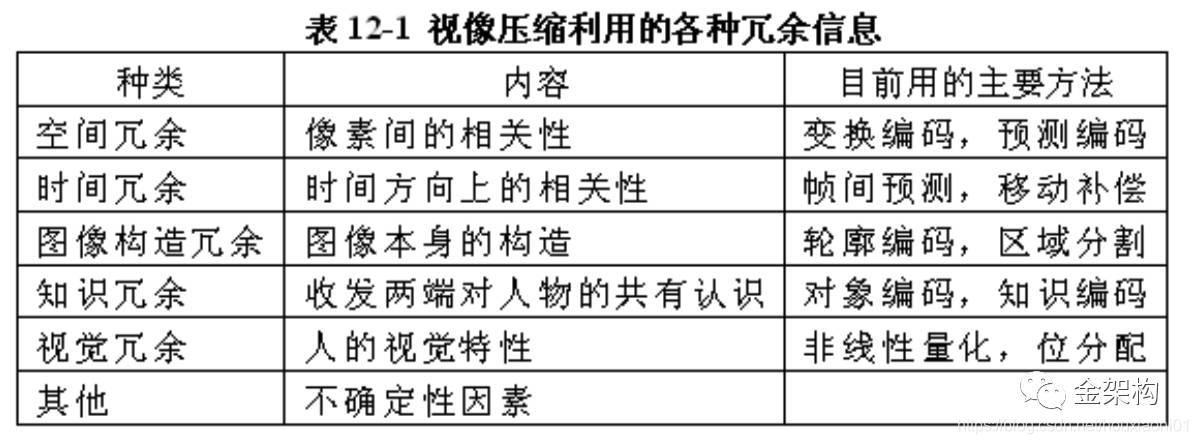
从上面就可以看出,有些冗余数据并不是那么好去掉的,比如知识冗余和结构冗余,这需要对图像的内容结构,有一个宏观的把握和接近智能的分析。
所以在上述冗余中,空间冗余、视觉冗余和数据冗余,在编码压缩技术中利用的比较充分。尤其是数据冗余,虽然我们这里并没展开介绍,不过它有接近60年的研究历史,而我们这个系列文章,到目前也只写了四个月而已。不过也因它有这么多年的研究历史,所以它的可挖掘空间也有限了。
而时间冗余还没有充分挖掘,因为视频本就是连续帧的组合,所以一个视像镜头内的图像数据,还有很大的压缩空间。而像视觉冗余,我们前面介绍的子采样格式,就是单纯利用这一点,来去除冗余数据的。
而MPEG,也就是接下来要介绍的对象,它也是主要利用时间冗余、空间冗余、视觉冗余和数据冗余,来进行编码压缩的。

















 2096
2096

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









