




 博客介绍了二分类的损失函数,还提及sklearn中的随机梯度下降。随机梯度下降是一种以随机方式最小化损失函数的优化技术,逐样本进行梯度下降步骤,是拟合线性模型的高效方法。
博客介绍了二分类的损失函数,还提及sklearn中的随机梯度下降。随机梯度下降是一种以随机方式最小化损失函数的优化技术,逐样本进行梯度下降步骤,是拟合线性模型的高效方法。
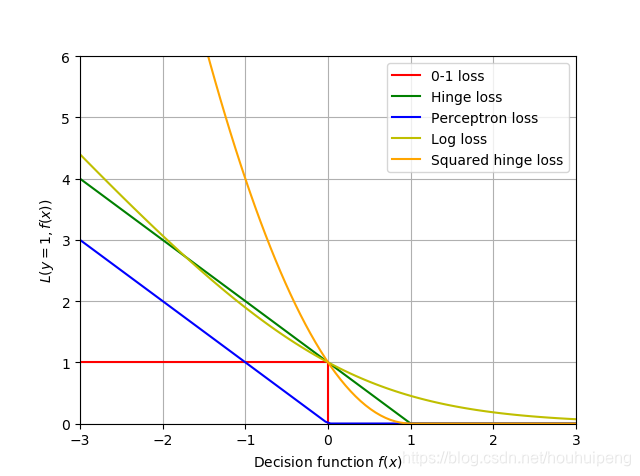
二分类的损失函数
sklearn:
Stochastic Gradient Descent is an optimization technique which minimizes a loss function in a stochastic fashion, performing a gradient descent step sample by sample. In particular, it is a very efficient method to fit linear models.

















 1019
1019

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









