




 本文介绍了神经网络的基本概念,包括ReLU激活函数的作用及其在房价预测中的应用,并探讨了神经网络如何进行监督学习。此外,还分析了深度学习兴起的原因,包括数据量的增长、硬件性能的提升及算法创新。
本文介绍了神经网络的基本概念,包括ReLU激活函数的作用及其在房价预测中的应用,并探讨了神经网络如何进行监督学习。此外,还分析了深度学习兴起的原因,包括数据量的增长、硬件性能的提升及算法创新。
目录
【此为本人学习吴恩达的深度学习课程的笔记记录,有错误请指出!】
什么是神经网络
让我们从一个房价预测的例子开始讲起,如根据房子面积来预测房屋价格。
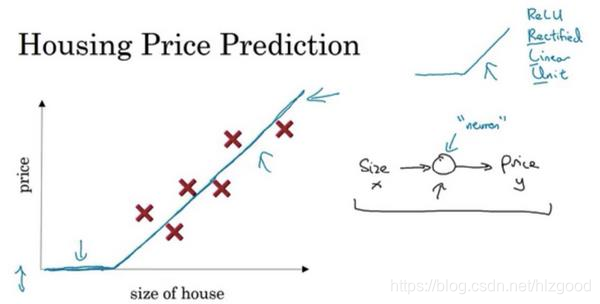
如果你对线性回归很熟悉, 可以用一条直线来拟合这些数据。但是房屋的价格永远不会是负数的,因此,可以把价格为负数的部分变成零,让它最终在零结束。这条粗的蓝线最终的预测函数,用于根据房屋面积预测价格。
在有关神经网络的文献中,你经常看得到这个函数。从趋近于零开始,然后变成一条直线。这个函数被称作 ReLU 激活函数,它的全称是 Rectified Linear Unit。 rectify(修正)可以理解成 𝑚𝑎𝑥(0, 𝑥),这也成为蓝线的函数的原因。
如果这是一个单神经元网络,不管规模大小,它正是通过把这些单个神经元叠加在一起来形成。如果把这些神经元想象成单独的乐高积木,就可以通过搭积木来完成一个更大的神经网络。
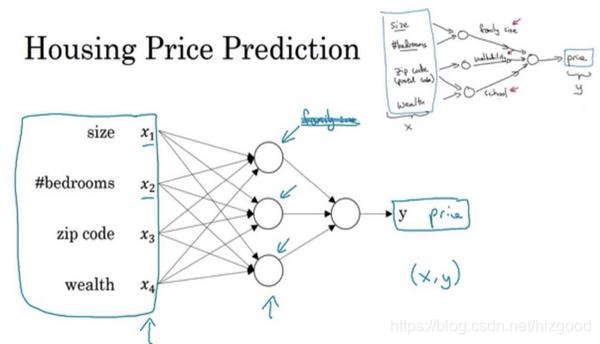
神经网络的监督学习
神经网络是一种监督学习算法。
我们举一些其它的例子,来说明神经网络已经被高效应用到其它地方。
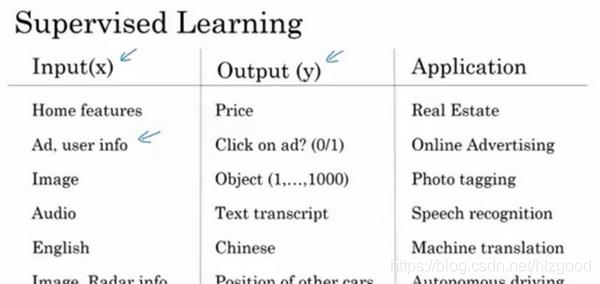
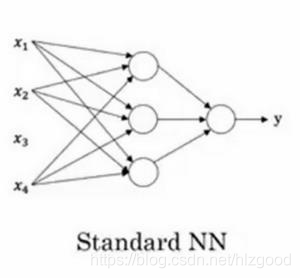
在不同的应用领域,神经网络的结构各不相同,左图是标准的神经网络,右图是卷积神经网络:

递归神经网络(RNN)非常适合一维序列,数据可能是一个时间组成部分,一般为非结构化数据(如:音频、图像、文本等)。
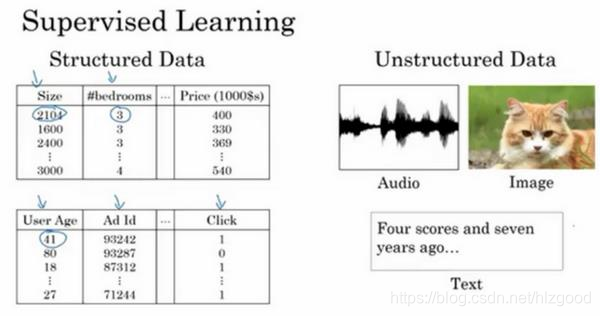
神经网络对结构化数据和非结构化数据都适用。
为什么深度学习会兴起
深度学习和神经网络之前的基础技术理念已经存在大概几十年了,为什么它们现在才突然流行起来呢?
如下图,横轴是数据量,纵轴是传统机器学习算法性能(准确率等):
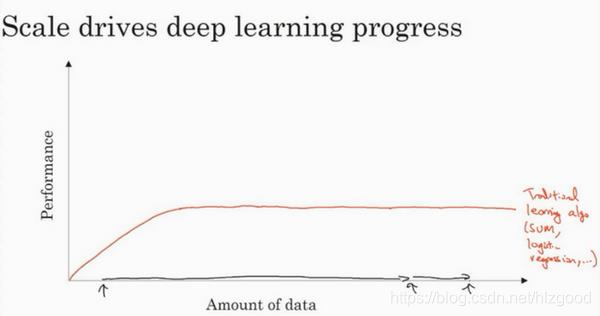
随着数据量规模的增大,算法性能先是上升,之后就趋向平缓。传统机器学习算法无法适应大规模数据,最终导致算法性能无法上升到更高的阶段。
不同规模的神经网络对于不同规模的数据,对应的算法性能如下:
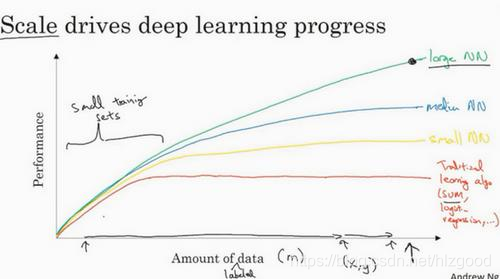
小型神经网络-小规模数据(黄线)
中型神经网络-中规模数据(蓝线)
大型神经网络-大规模数据(绿线)
可以看出,想要神经网络获得更好的性能,要么训练一个更大的神经网络,要么投入更多的数据。
在较小的训练集中,各种算法的性能差别不是很明显,所以,如果没有大量的训练集,那么性能效果取决于你的特征工程能力。
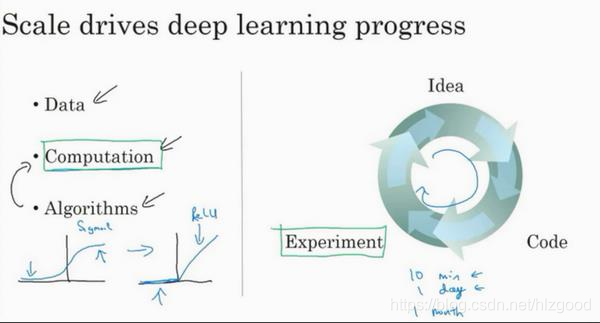
因此,近年来神经网络的兴起原因如下:
1、数据量的爆发式增长,如:互联网、物联网等应用的出现
2、硬件的性能大大提高,如:CPU、GPU、存储等
3、算法的极大创新,如: 神经网络方面的一个巨大突破是从 sigmoid 函数转换到一个 ReLU函数:

sigmoid 函数的梯度会接近零, 参数会更新的很慢,所以学习的速度会变得非常缓慢。
ReLU(修正线性单元)函数的梯度对于所有输入的负值都是零, 也就是这条线的斜率在左边是零。
仅仅通过将 Sigmod 函数转换成 ReLU 函数,便能够使得做梯度下降算法运行的更快,这就是一个或许相对比较简单的算法创新的例子。
这些原因使得神经网络的实验人员和有关项目的研究人员在深度学习的工作中迭代的更快,以便快速验证自己的想法和得到实验结果:

















 1801
1801

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









