




 本文介绍了HTTP协议的基础知识,包括HTTP报文的结构、请求报文与响应报文的组成、Cookie技术在管理状态中的作用,以及URL如何定位网络资源。理解这些概念对于网络通信至关重要。
本文介绍了HTTP协议的基础知识,包括HTTP报文的结构、请求报文与响应报文的组成、Cookie技术在管理状态中的作用,以及URL如何定位网络资源。理解这些概念对于网络通信至关重要。
Http协议简介
主要内容来自于 《图解HTTP》
HTTP 协议用于客户端和服务器端之间的通信 ,通过请求和响应的报文达成通信。
HTTP的主要知识点有:
1、HTTP 报文
用于 HTTP 协议交互的信息被称为 HTTP 报文。
- 请求端(客户端) 的HTTP 报文叫做请求报文
- 响应端(服务器端) 的叫做响应报文。
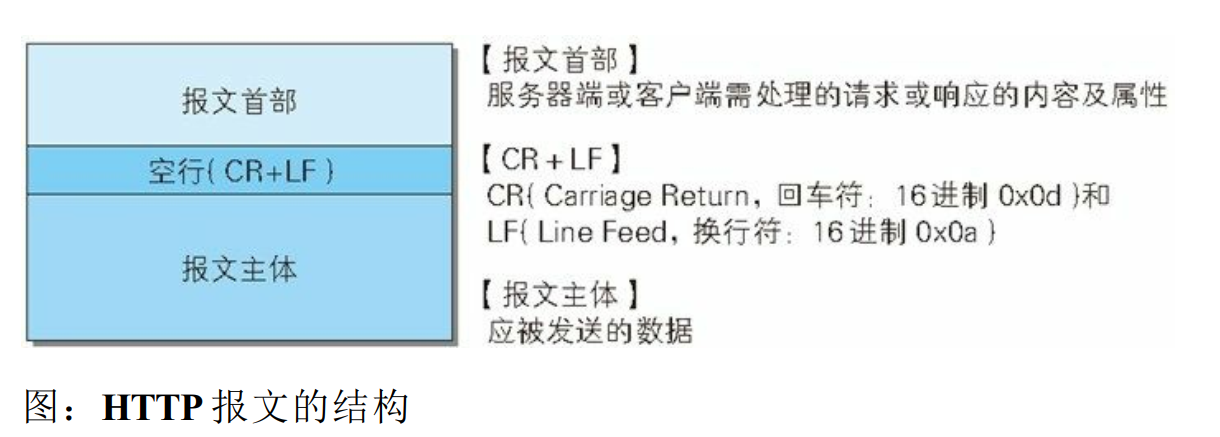
HTTP 报文本身是由多行(用 CR+LF 作换行符) 数据构成的字符串文本。
HTTP 报文大致可分为报文首部和报文主体两块。 两者由最初出现的空行(CR+LF) 来划分。 通常, 并不一定要有报文主体。
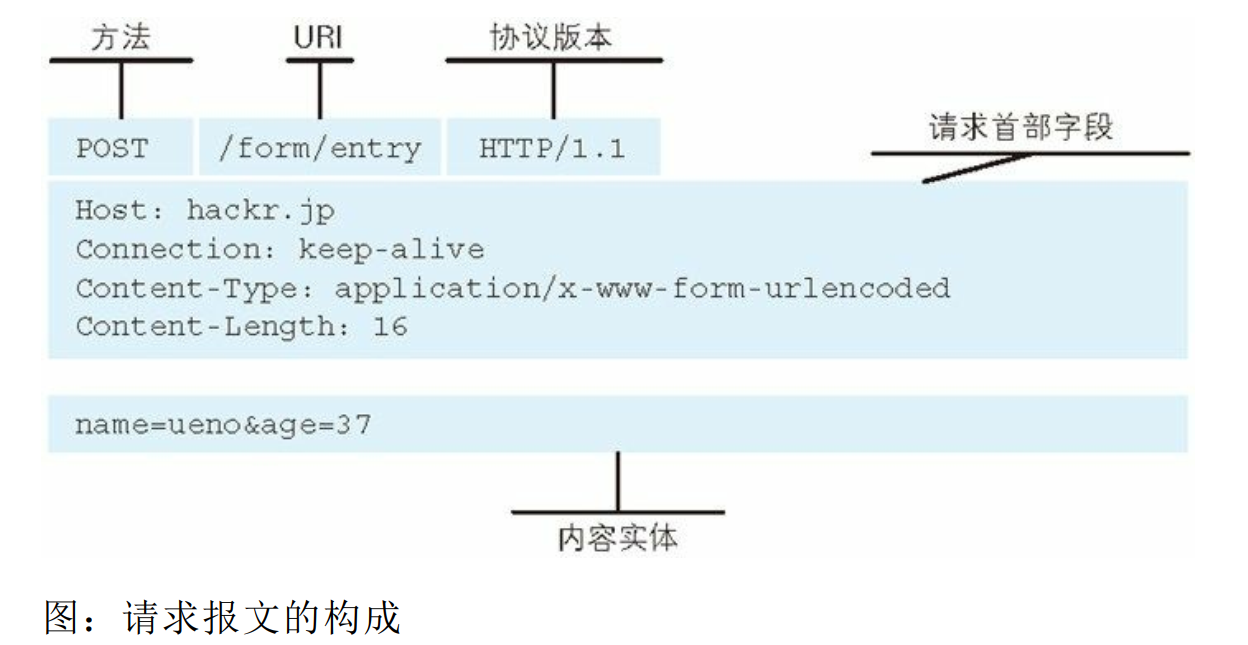
2、请求报文
请求报文是由请求方法、 请求 URI、 协议版本、 可选的请求首部字段和内容实体构成的。
3、响应报文
响应报文基本上由协议版本、 状态码(表示请求成功或失败的数字代码) 、 用以解释状态码的原因短语、 可选的响应首部字段以及实体主体构成。

4、Cookie 技术
HTTP 是一种不保存状态, 即无状态(stateless) 协议。 HTTP 协议自身不对请求和响应之间的通信状态进行保存。 也就是说在 HTTP 这个级别, 协议对于发送过的请求或响应都不做持久化处理。
为了实现期望的保持状态功能, 于是引入了 Cookie 技术。 有了 Cookie 再用 HTTP 协议通信, 就可以管理状态了。
5、URL 定位资源
超文本传输协议(HTTP)的统一资源定位符将从因特网获取信息的五个基本元素包括在一个简单的地址中:
- 传送协议,一般会说出协议方案-schema
- 层级URL标记符号(为[//],固定不变)
- 访问资源需要的凭证信息(可省略)
- 服务器。(通常为域名,有时为IP地址)
- 端口号。(以数字方式表示,若为HTTP的默认值“:80”可省略)
- 路径。(以“/”字符区别路径中的每一个目录名称)
- 查询。(GET模式的窗体参数,以“?”字符为起点,每个参数以“&”隔开,再以“=”分开参数名称与数据,通常以UTF8的URL编码,避开字符冲突的问题)
- 片段。以“#”字符为起点
以 http://www.luffycity.com:80/news/index.html?id=250&page=1 为例, 其中:
- http,是协议;
www.luffycity.com,是服务器;- 80,是服务器上的默认网络端口号,默认不显示;
- /news/index.html,是路径(URI:直接定位到对应的资源);
- ?id=250&page=1,是查询。
- 大多数网页浏览器不要求用户输入网页中“http://”的部分,因为绝大多数网页内容是超文本传输协议文件。同样,“80”是超文本传输协议文件的常用端口号,因此一般也不必写明。一般来说用户只要键入统一资源定位符的一部分(
www.luffycity.com:80/news/index.html?id=250&page=1)就可以了。
由于超文本传输协议允许服务器将浏览器重定向到另一个网页地址,因此许多服务器允许用户省略网页地址中的部分,比如 www。从技术上来说这样省略后的网页地址实际上是一个不同的网页地址,浏览器本身无法决定这个新地址是否通,服务器必须完成重定向的任务。

















 3804
3804

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









