






文章目录
- 一、选择题
- 1. 以下哪一种搜索算法属于启发式搜索算法?( )
- 2. 以下人工神经元网络中,计算复杂度最高的是:( )
- 3. 以下关于Sigmoid函数正确的说法是:( )
- 4. 以下哪一项不是图灵在1950年论文《Computing Machinery and Intelligence》中提出的思想?( )
- 5. 以下哪一位学者是连接主义运动中PDP学派的代表性学者?( )
- 6. 广度优先搜索(BFS)和深度优先搜索(DFS)的主要区别是:( )
- 7. 一致代价搜索(UCS)的主要特点是:( )
- 8. 以下关于启发式函数 h ( n ) h(n) h(n)可采纳性的说法正确的是:( )
- 9. 模拟退火算法的核心思想是:( )
- 10. 蒙特卡洛树搜索(MCTS)的四个主要步骤是:( )
- 11. 约束满足问题(CSP)的核心特点是:( )
- 12. 以下关于监督学习、无监督学习和强化学习的说法正确的是:( )
- 13. 反向传播算法的核心优势是:( )
- 14. ReLU激活函数 f ( x ) = max ( 0 , x ) f(x) = \max(0, x) f(x)=max(0,x)的主要特点是:( )
- 15. 卷积神经网络(CNN)中卷积层的主要作用是:( )
- 16. 循环神经网络(RNN)的主要特点是:( )
- 17. Transformer模型相比RNN的主要优势是:( )
- 18. 在二分类问题中,如果关注减少误报(False Positive),应该优先考虑哪个指标?( )
- 19. 机器学习中,过拟合(Overfitting)的主要表现是:( )
- 20. Bayes网络的核心优势是:( )
- 21. 符号推理和不确定性推理的主要区别是:( )
- 22. 命题逻辑和一阶逻辑的主要区别是:( )
- 23. 遗传算法的三个核心操作是:( )
- 24. 爬山算法的主要局限是:( )
- 25. 单层感知器无法解决XOR问题的根本原因是:( )
- 26. 人工神经网络的三个基本要素是:( )
- 27. 梯度消失问题主要发生在:( )
- 28. 正则化的主要作用是:( )
- 29. 机器学习中,欠拟合(Underfitting)的主要表现是:( )
- 30. LSTM(长短期记忆网络)相比标准RNN的主要优势是:( )
- 31. 注意力机制的核心思想是:( )
- 32. 卷积神经网络中池化层的主要作用是:( )
- 33. 强化学习中,Q-learning算法的核心思想是:( )
- 34. 模糊逻辑相比传统逻辑的主要特点是:( )
- 35. 符号推理中,前向推理和反向推理的主要区别是:( )
- 二、简答题
一、选择题
📌 知识点索引:以下选择题按知识领域分类,便于针对性复习
搜索算法(9道):第1题(A*搜索)、第6题(BFS/DFS)、第7题(UCS)、第8题(启发式函数可采纳性)、第9题(模拟退火)、第10题(MCTS四个步骤)、第11题(约束满足)、第23题(遗传算法三个操作)、第24题(爬山算法局限)
神经网络(12道):第2题(DBN计算复杂度)、第3题(Sigmoid函数)、第13题(反向传播)、第14题(ReLU函数)、第15题(CNN卷积层)、第16题(RNN特点)、第17题(Transformer优势)、第26题(神经网络三要素)、第27题(梯度消失)、第30题(LSTM优势)、第31题(注意力机制)、第32题(池化层)
机器学习基础(6道):第12题(监督/无监督/强化学习)、第18题(精确率/召回率)、第19题(过拟合)、第25题(感知器和XOR问题)、第28题(正则化)、第29题(欠拟合)
推理方法(5道):第20题(Bayes网络)、第21题(符号推理vs不确定性推理)、第22题(命题逻辑vs一阶逻辑)、第34题(模糊逻辑)、第35题(前向推理vs反向推理)
强化学习(1道):第33题(Q-learning算法)
历史与基础(2道):第4题(图灵论文)、第5题(PDP学派)
1. 以下哪一种搜索算法属于启发式搜索算法?( )
A. 模拟退火算法
B. 迭代深入深度优先算法
C. 蒙特卡洛树搜索算法
D. A*搜索算法
答案:D
解析: A*搜索算法使用启发式函数 f ( n ) = g ( n ) + h ( n ) f(n) = g(n) + h(n) f(n)=g(n)+h(n)来评估节点,其中 g ( n ) g(n) g(n)是从起点到当前节点的实际代价, h ( n ) h(n) h(n)是从当前节点到目标的估计代价(启发式函数),属于启发式搜索算法。
- 模拟退火算法是元启发式算法,
- 迭代深入深度优先算法是盲目搜索算法,
- 蒙特卡洛树搜索算法是基于随机模拟的算法。
2. 以下人工神经元网络中,计算复杂度最高的是:( )
A. Hopfield
B. SOM (Self-Organizing Map)
C. DBM (Deep Boltzmann Machine)
D. DBN (Deep Belief Network)
答案:D
解析:
- DBN(深度信念网络)是深度模型,由多个受限玻尔兹曼机(RBM)堆叠而成,训练过程复杂,需要逐层预训练和微调,计算复杂度很高。
- Hopfield网络是单层反馈网络,SOM是自组织映射网络,计算相对简单。
- DBM(深度玻尔兹曼机)虽然也是深度能量模型,但DBN的训练和推理过程通常更复杂。
3. 以下关于Sigmoid函数正确的说法是:( )
A. 凸函数
B. 输出可以有负值
C. 无法配合交叉熵损失使用
D. 输入过大或过小时会产生梯度消失问题
答案:D
解析:
- A选项错误:Sigmoid函数不是凸函数
- B选项错误:Sigmoid函数 f ( x ) = 1 1 + e − x f(x) = \frac{1}{1+e^{-x}} f(x)=1+e−x1的输出范围是 ( 0 , 1 ) (0,1) (0,1),没有负值,只能输出0到1之间的值
- C选项错误:Sigmoid函数可以配合交叉熵损失使用,实际上是最常用的组合(如二分类问题)
- D选项正确:当输入过大或过小时,Sigmoid函数会饱和(接近0或1),梯度接近0,产生梯度消失问题,这是Sigmoid函数的主要缺点之一
4. 以下哪一项不是图灵在1950年论文《Computing Machinery and Intelligence》中提出的思想?( )
A. 机器学习
B. 自动差分机
C. 模仿游戏
D. 数字计算机
答案:D
解析: 数字计算机的概念在图灵1950年论文之前就已经存在和发展,图灵在论文中讨论的是如何使用数字计算机来实现智能,而不是提出数字计算机的概念本身。自动差分机(Analytical Engine)是19世纪巴贝奇提出的概念,也不是图灵提出的。图灵在1950年论文中提出了"模仿游戏"(图灵测试)和机器学习的早期思想。
注: 不同资料可能给出不同答案。自动差分机确实是巴贝奇提出的,不是图灵提出的;数字计算机的概念在图灵论文之前就已存在,图灵在论文中主要是讨论如何使用数字计算机实现智能。
5. 以下哪一位学者是连接主义运动中PDP学派的代表性学者?( )
A. Frank Rosenblatt
B. David E. Rumelhart
C. Marvin Minsky
D. LeCun Yann
答案:B
解析: David E. Rumelhart是PDP(Parallel Distributed Processing,并行分布式处理)学派的代表性学者,与James McClelland共同编写了《Parallel Distributed Processing》一书,奠定了连接主义的基础。
- Frank Rosenblatt是感知器的发明者,
- Marvin Minsky是符号主义的代表人物,
- LeCun Yann是深度学习的先驱。
6. 广度优先搜索(BFS)和深度优先搜索(DFS)的主要区别是:( )
A. BFS保证找到最短路径,DFS可能找不到解
B. BFS内存消耗小,DFS内存消耗大
C. BFS使用栈,DFS使用队列
D. BFS适合深度大的问题,DFS适合广度大的问题
答案:A
解析: BFS按层扩展,保证找到最短路径,但内存消耗大(需要存储所有层的节点)。DFS按深度扩展,内存消耗小(只需要存储当前路径),但可能找不到解或不是最短路径。BFS使用队列(先进先出),DFS使用栈(后进先出)。BFS适合广度大的问题,DFS适合深度大的问题。
7. 一致代价搜索(UCS)的主要特点是:( )
A. 保证找到代价最小的解
B. 保证找到深度最小的解
C. 保证找到启发式值最小的解
D. 保证找到访问节点最少的解
答案:A
解析:
- UCS(一致代价搜索)按路径代价选择节点,优先探索代价小的路径,保证找到代价最小的解。
- BFS保证找到深度最小的解(最短路径),
- A*搜索保证找到启发式值最小的解(在启发式函数可采纳的前提下),
- DFS可能找到访问节点最少的解但不保证最优。
8. 以下关于启发式函数 h ( n ) h(n) h(n)可采纳性的说法正确的是:( )
A. 可采纳性要求
h
(
n
)
h(n)
h(n)必须等于真实代价
h
∗
(
n
)
h^*(n)
h∗(n)
B. 可采纳性要求
h
(
n
)
≤
h
∗
(
n
)
h(n) \leq h^*(n)
h(n)≤h∗(n),即不能高估真实代价
C. 可采纳性要求
h
(
n
)
≥
h
∗
(
n
)
h(n) \geq h^*(n)
h(n)≥h∗(n),即不能低估真实代价
D. 可采纳性要求
h
(
n
)
h(n)
h(n)必须大于0
答案:B
解析: 启发式函数的可采纳性(admissible)要求 h ( n ) ≤ h ∗ ( n ) h(n) \leq h^*(n) h(n)≤h∗(n),即启发式函数不能高估从当前节点到目标的真实代价。如果 h ( n ) h(n) h(n)可采纳,A*算法保证找到最优解。 h ( n ) = h ∗ ( n ) h(n) = h^*(n) h(n)=h∗(n)是最理想的情况,但不是可采纳性的要求。 h ( n ) ≥ h ∗ ( n ) h(n) \geq h^*(n) h(n)≥h∗(n)会导致高估,破坏最优性保证。 h ( n ) > 0 h(n) > 0 h(n)>0是单调性的要求,不是可采纳性的要求。
9. 模拟退火算法的核心思想是:( )
A. 只接受更好的解,拒绝更差的解
B. 以一定概率接受更差的解,避免陷入局部最优
C. 随机选择解,不进行优化
D. 只搜索局部最优解
答案:B
解析: 模拟退火算法模拟金属退火过程,核心思想是以一定概率接受更差的解,从而避免陷入局部最优。随着"温度"降低,接受更差解的概率逐渐减小。只接受更好的解是爬山算法的特点,会陷入局部最优。随机选择解无法进行优化。只搜索局部最优解不是模拟退火的目标。
10. 蒙特卡洛树搜索(MCTS)的四个主要步骤是:( )
A. 选择、扩展、模拟、反向更新
B. 初始化、搜索、评估、更新
C. 前向传播、反向传播、参数更新、验证
D. 编码、选择、交叉、变异
答案:A
解析: MCTS的四个主要步骤是:选择(Selection,使用UCB算法选择最有希望的节点)、扩展(Expansion,创建新节点)、模拟(Simulation,随机下完这盘棋)、反向更新(Backpropagation,更新路径上所有节点的统计信息)。初始化、搜索、评估、更新是其他算法的步骤。前向传播、反向传播是神经网络的步骤。编码、选择、交叉、变异是遗传算法的步骤。
11. 约束满足问题(CSP)的核心特点是:( )
A. 只需要找到一个解
B. 需要同时满足多个约束条件
C. 不需要回溯搜索
D. 只能处理数值优化问题
答案:B
解析:
- 约束满足问题的核心特点是需要同时满足多个约束条件,如数独问题需要同时满足行、列、宫的约束。
- CSP可能有多解或无解,需要找到满足所有约束的解。约束满足通常需要回溯搜索和约束传播来减少搜索空间。
- CSP可以处理离散变量的约束问题,不限于数值优化。
12. 以下关于监督学习、无监督学习和强化学习的说法正确的是:( )
A. 监督学习需要标签数据,无监督学习不需要数据,强化学习需要环境交互
B. 监督学习需要标签数据,无监督学习不需要标签数据,强化学习通过奖励信号学习
C. 监督学习不需要数据,无监督学习需要标签数据,强化学习需要环境交互
D. 三种学习方式都需要标签数据
答案:B
解析: 监督学习使用有标签数据(输入-输出对),通过比较预测和真实标签来学习。无监督学习使用无标签数据,通过发现数据的内在结构来学习。强化学习通过与环境交互,根据奖励信号来学习最优策略。三种学习方式都需要数据,但数据形式不同。
13. 反向传播算法的核心优势是:( )
A. 只需要一次前向传播就能计算所有梯度
B. 通过一次前向传播和一次反向传播就能高效计算所有参数的梯度
C. 不需要计算梯度,直接更新参数
D. 只能用于单层神经网络
答案:B
解析: 反向传播算法的核心优势是通过一次前向传播(计算函数值并保存中间结果)和一次反向传播(使用链式法则计算梯度)就能高效计算所有参数的梯度。只进行一次前向传播无法计算梯度。反向传播需要计算梯度。反向传播可以用于多层神经网络,是训练深层网络的关键算法。
14. ReLU激活函数 f ( x ) = max ( 0 , x ) f(x) = \max(0, x) f(x)=max(0,x)的主要特点是:( )
A. 输出范围是
(
0
,
1
)
(0,1)
(0,1),容易饱和
B. 在正区域梯度恒为1,不会饱和,但在负区域梯度为0
C. 输出范围是
(
−
1
,
1
)
(-1,1)
(−1,1),以0为中心
D. 在所有区域梯度都恒为1
答案:B
解析: ReLU激活函数在正区域( x > 0 x > 0 x>0)梯度恒为1,不会饱和,这是它的主要优势。但在负区域( x ≤ 0 x \leq 0 x≤0)梯度为0,可能导致"死亡ReLU"问题。ReLU的输出范围是 [ 0 , + ∞ ) [0, +\infty) [0,+∞),不是 ( 0 , 1 ) (0,1) (0,1)。Tanh的输出范围是 ( − 1 , 1 ) (-1,1) (−1,1),以0为中心。ReLU在负区域梯度为0,不是恒为1。
15. 卷积神经网络(CNN)中卷积层的主要作用是:( )
A. 增加网络深度
B. 提取局部特征,通过卷积操作捕获空间模式
C. 减少参数数量,但会丢失空间信息
D. 只能处理一维数据
答案:B
解析: CNN中卷积层通过卷积操作提取局部特征,能够捕获空间模式(如边缘、纹理等),这是CNN的核心优势。卷积层可以增加网络深度,但这不是其主要作用。卷积层通过参数共享减少参数数量,同时保留空间信息。CNN可以处理二维(图像)和三维数据,不限于一维数据。
16. 循环神经网络(RNN)的主要特点是:( )
A. 只能处理固定长度的序列
B. 通过隐藏状态记忆历史信息,适合处理序列数据
C. 无法处理序列数据,只能处理单个样本
D. 计算效率高,但表达能力弱
答案:B
解析: RNN通过隐藏状态记忆历史信息,能够处理变长序列数据,适合处理序列数据(如文本、语音、时间序列)。RNN可以处理变长序列,不是固定长度。RNN专门设计用于处理序列数据。RNN的计算效率相对较低(需要顺序计算),但表达能力较强。
17. Transformer模型相比RNN的主要优势是:( )
A. 只能处理短序列
B. 通过自注意力机制实现并行计算,同时捕获全局依赖
C. 计算复杂度更高
D. 无法处理长距离依赖
答案:B
解析: Transformer通过自注意力机制实现并行计算(替代RNN的循环结构),同时每个位置都能访问所有位置的信息,捕获全局依赖,这是它的主要优势。Transformer可以处理长序列。Transformer的计算复杂度虽然较高,但通过并行计算提高了效率。Transformer能够很好地处理长距离依赖。
18. 在二分类问题中,如果关注减少误报(False Positive),应该优先考虑哪个指标?( )
A. 准确率(Accuracy)
B. 精确率(Precision)
C. 召回率(Recall)
D. F1分数
答案:B
解析: 精确率(Precision)衡量被预测为正例的样本中真正为正例的比例,关注假正例(False Positive)情况,即误报率。当误报的代价很高时(如垃圾邮件检测),应该优先考虑精确率。准确率关注整体预测准确性。召回率关注假负例(False Negative),即漏报率。F1分数是精确率和召回率的调和平均,用于平衡两者。
19. 机器学习中,过拟合(Overfitting)的主要表现是:( )
A. 模型在训练集上表现差,在测试集上表现好
B. 模型在训练集上表现好,在测试集上表现差
C. 模型在训练集和测试集上都表现差
D. 模型无法学习到任何规律
答案:B
解析: 过拟合是指模型在训练集上表现很好,但在测试集(新数据)上表现较差,说明模型过度拟合了训练数据的噪声和细节,泛化能力差。模型在训练集上表现差是欠拟合的表现。模型在训练集和测试集上都表现差可能是模型能力不足或数据问题。模型无法学习到任何规律是严重欠拟合的表现。
20. Bayes网络的核心优势是:( )
A. 需要存储所有变量的联合概率分布
B. 利用条件独立性,将指数级的联合概率分布分解为线性级的条件概率分布
C. 只能处理离散变量
D. 推理计算复杂度总是线性的
答案:B
解析: Bayes网络利用条件独立性,将指数级的联合概率分布 P ( X 1 , X 2 , . . . , X n ) P(X_1, X_2, ..., X_n) P(X1,X2,...,Xn)分解为线性级的条件概率分布 ∏ i = 1 n P ( X i ∣ P a r e n t s ( X i ) ) \prod_{i=1}^{n} P(X_i | Parents(X_i)) ∏i=1nP(Xi∣Parents(Xi)),每个节点只需要存储给定父节点的条件概率分布,大幅减少需要存储的参数数量。这是Bayes网络的核心优势。Bayes网络可以处理连续变量(如高斯贝叶斯网络)。Bayes网络的精确推理是NP难问题,计算复杂度可能是指数级的,因此需要近似推理方法。
21. 符号推理和不确定性推理的主要区别是:( )
A. 符号推理处理不确定信息,不确定性推理处理确定信息
B. 符号推理基于逻辑规则进行确定性推理,不确定性推理基于概率处理不确定信息
C. 符号推理只能处理离散问题,不确定性推理只能处理连续问题
D. 符号推理计算复杂度低,不确定性推理计算复杂度高
答案:B
解析: 符号推理基于逻辑规则(如命题逻辑、一阶逻辑)进行确定性推理,从已知前提推导出确定无疑的结论。不确定性推理基于概率方法(如Bayes网络、马尔可夫模型)处理不确定信息,用概率表示不确定性。符号推理可以处理离散和连续问题(通过量化)。两种推理方法的计算复杂度都可能有高有低,取决于具体问题。
22. 命题逻辑和一阶逻辑的主要区别是:( )
A. 命题逻辑处理对象和关系,一阶逻辑只处理命题
B. 命题逻辑只能表示命题之间的逻辑关系,一阶逻辑可以表示"对于所有x"、"存在x"等量词
C. 命题逻辑表达能力更强
D. 一阶逻辑的真值只能是真或假,命题逻辑可以是连续值
答案:B
解析: 命题逻辑只能表示命题之间的逻辑关系(如"如果A,那么B"),不能表示对象和属性。一阶逻辑引入个体和谓词,可以表示"对于所有x"、"存在x"等量词,表达能力更强。一阶逻辑的表达能力比命题逻辑更强。两种逻辑都是二值逻辑(真/假),模糊逻辑才是连续值(0到1)。
23. 遗传算法的三个核心操作是:( )
A. 初始化、搜索、评估
B. 编码、适应度评估、选择交叉变异
C. 前向传播、反向传播、参数更新
D. 选择、扩展、模拟、反向更新
答案:B
解析: 遗传算法的三个核心操作是编码(将问题的解转换成可操作形式)、适应度评估(评估每个解的优劣)、选择交叉变异(通过选择保留好的解,交叉组合优点,变异增加多样性)。初始化、搜索、评估是其他算法的步骤。前向传播、反向传播是神经网络的步骤。选择、扩展、模拟、反向更新是MCTS的步骤。
24. 爬山算法的主要局限是:( )
A. 计算复杂度太高
B. 容易陷入局部最优,无法找到全局最优
C. 需要大量内存
D. 只能处理离散问题
答案:B
解析: 爬山算法只向值增加的方向移动,容易陷入局部最优,无法找到全局最优。就像爬山时只向上爬,可能爬到一个小山峰就停下来了,而真正的最高峰在别的地方。爬山算法的计算复杂度相对较低,内存消耗也较小。爬山算法可以处理连续和离散问题。
25. 单层感知器无法解决XOR问题的根本原因是:( )
A. 计算能力不足
B. XOR问题是线性不可分的,单层感知器只能解决线性可分问题
C. 训练数据不足
D. 激活函数选择不当
答案:B
解析: 单层感知器只能解决线性可分问题,即可以用一条直线(或超平面)将两类数据分开。XOR问题是线性不可分的,无法用一条直线分开,因此单层感知器无法解决。需要多层感知器(包含隐藏层)才能解决XOR问题,因为隐藏层通过非线性激活函数引入非线性,使网络能够学习非线性决策边界。
26. 人工神经网络的三个基本要素是:( )
A. 输入层、隐藏层、输出层
B. 神经元、连接权重、激活函数
C. 前向传播、反向传播、参数更新
D. 数据、模型、算法
答案:B
解析: 人工神经网络的三个基本要素是神经元(基本处理单元)、连接权重(调节信号传递的影响程度,是网络学习的核心参数)、激活函数(引入非线性,使网络能够学习和表示复杂的非线性关系)。输入层、隐藏层、输出层是网络结构,不是基本要素。前向传播、反向传播是训练过程。数据、模型、算法是机器学习的要素。
27. 梯度消失问题主要发生在:( )
A. 使用ReLU激活函数的深层网络
B. 使用Sigmoid或Tanh激活函数的深层网络
C. 单层神经网络
D. 使用线性激活函数的网络
答案:B
解析: 梯度消失问题主要发生在使用Sigmoid或Tanh激活函数的深层网络中。当输入过大或过小时,这些激活函数会饱和(接近0或1),梯度接近0,在反向传播过程中梯度会快速衰减到接近0,导致前面的层无法更新。ReLU在正区域梯度恒为1,不会消失。单层网络不会出现梯度消失。线性激活函数不会饱和,但会使多层网络等价于单层网络。
28. 正则化的主要作用是:( )
A. 加快训练速度
B. 防止过拟合,提高模型的泛化能力
C. 增加模型复杂度
D. 减少训练数据量
答案:B
解析: 正则化的主要作用是防止过拟合,提高模型的泛化能力。通过约束模型复杂度(如L2正则化约束权重)或增加数据多样性(如数据增强),防止模型记住训练数据的细节而不是学习通用模式。正则化可能会稍微减慢训练速度。正则化是减少模型复杂度,不是增加。正则化不减少训练数据量。
29. 机器学习中,欠拟合(Underfitting)的主要表现是:( )
A. 模型在训练集上表现好,在测试集上表现差
B. 模型在训练集和测试集上都表现差
C. 模型在训练集上表现差,在测试集上表现好
D. 模型无法学习到任何规律
答案:B
解析: 欠拟合是指模型在训练集和测试集上都表现差,说明模型能力不足,无法学习到数据中的规律。模型在训练集上表现好、测试集上表现差是过拟合的表现。模型在训练集上表现差、测试集上表现好的情况很少见。模型无法学习到任何规律是严重欠拟合的表现,但欠拟合不一定完全无法学习。
30. LSTM(长短期记忆网络)相比标准RNN的主要优势是:( )
A. 计算速度更快
B. 通过门控机制解决梯度消失问题,能够学习长期依赖
C. 只能处理短序列
D. 参数数量更少
答案:B
解析: LSTM通过门控机制(遗忘门、输入门、输出门)控制信息的流动,能够选择性地记住或遗忘信息,从而解决标准RNN的梯度消失问题,能够学习长期依赖。LSTM的计算速度相对较慢(因为门控机制增加了计算量)。LSTM专门设计用于处理长序列。LSTM的参数数量比标准RNN更多(因为增加了门控机制)。
31. 注意力机制的核心思想是:( )
A. 对所有输入给予相同的权重
B. 动态地关注输入的不同部分,根据相关性分配不同的权重
C. 只关注第一个输入
D. 随机选择输入
答案:B
解析: 注意力机制的核心思想是动态地关注输入的不同部分,根据相关性分配不同的权重。通过计算Query和Key之间的相似度,生成注意力权重,对Value进行加权求和,使模型能够根据当前需要,动态地关注输入的不同部分。对所有输入给予相同权重是平均池化。只关注第一个输入或随机选择输入都不是注意力机制的特点。
32. 卷积神经网络中池化层的主要作用是:( )
A. 提取特征
B. 减少参数数量,降低计算复杂度,同时提供平移不变性
C. 增加网络深度
D. 引入非线性
答案:B
解析: 池化层(如最大池化、平均池化)的主要作用是减少参数数量,降低计算复杂度,同时提供平移不变性(对输入的小幅平移不敏感)。提取特征是卷积层的作用。池化层不直接增加网络深度(虽然可以减少特征图尺寸)。引入非线性是激活函数的作用。
33. 强化学习中,Q-learning算法的核心思想是:( )
A. 直接优化策略函数
B. 学习动作价值函数Q(s,a),表示在状态s下采取动作a的期望累积奖励
C. 只考虑即时奖励
D. 不需要探索,只利用已知信息
答案:B
解析: Q-learning算法学习动作价值函数Q(s,a),表示在状态s下采取动作a的期望累积奖励。通过不断更新Q值,最终学习到最优策略(在每个状态选择Q值最大的动作)。直接优化策略函数是策略梯度方法的特点。Q-learning考虑长期累积奖励,不是只考虑即时奖励。Q-learning需要平衡探索和利用,不能只利用已知信息。
34. 模糊逻辑相比传统逻辑的主要特点是:( )
A. 只能处理真或假两种值
B. 允许真值在0到1之间连续取值,能够处理模糊性和不确定性
C. 只能处理离散问题
D. 计算复杂度更高
答案:B
解析: 模糊逻辑允许真值在0到1之间连续取值,能够处理模糊性和不确定性,这是它相比传统逻辑(命题逻辑、一阶逻辑都是二值逻辑)的主要特点。传统逻辑只能处理真或假两种值。模糊逻辑可以处理连续和离散问题。模糊逻辑的计算复杂度取决于具体应用,不一定更高。
35. 符号推理中,前向推理和反向推理的主要区别是:( )
A. 前向推理从目标往回找,反向推理从已知往前推
B. 前向推理从已知前提往前推,反向推理从目标往回找
C. 前向推理只能处理确定信息,反向推理只能处理不确定信息
D. 前向推理计算复杂度更高
答案:B
解析: 前向推理从已知前提往前推,应用推理规则逐步推导出新知识,直到得到目标结论。反向推理从目标往回找,寻找支持目标的前提条件,直到找到已知事实。两者都可以处理确定信息。两者的计算复杂度取决于具体问题,没有固定关系。
二、简答题
第一部分:搜索算法
1. 简述蒙特卡洛树搜索(MCTS)算法的基本原理和主要步骤。
MCTS是一种用于在搜索空间巨大、无法精确评估的复杂问题中找到最优决策的算法。核心思想是通过随机模拟估计决策的胜率,不需要精确的评估函数。算法系统化地组织探索过程,构建搜索树记录每个走法的统计信息,使用UCB算法平衡探索和利用。
MCTS包括四个步骤:
- 选择(Selection),从根节点出发,使用UCB算法选择最有希望的节点,UCB算法通过平衡两个因素来选择节点:一是节点的胜率(访问该节点后获胜的次数比例),二是节点的不确定性(访问次数越少,不确定性越大),这样既能利用已知的好走法,又能探索未充分探索的走法;
- 扩展(Expansion),创建新节点,尝试未探索的走法;
- 模拟(Simulation),从新节点开始随机模拟直到终止状态;
- 反向更新(Backpropagation),将模拟结果沿路径回传,更新所有节点的统计信息(包括访问次数和获胜次数)。
四个步骤不断重复,逐步构建搜索树。计算资源越多,搜索树越大,决策越准确。MCTS适合搜索空间巨大、无法精确评估的问题。
UCB公式为 U C B = w i n i + c ln N n i UCB = \frac{w_i}{n_i} + c \sqrt{\frac{\ln N}{n_i}} UCB=niwi+cnilnN,其中第一项是胜率(利用已知好的),第二项是不确定性度量(探索新的),这样可以在探索和利用之间取得平衡。
2. 写出遗传算法的原理、要点和计算过程(用流程图表示)。
遗传算法是一种基于自然选择和遗传学理论的优化算法。通过编码表示候选解,适应度评估,选择,交叉和变异等操作,逐代演化,寻找问题的最优解。
它的要点包括编码表示、适应度评估、初始化种群、选择、交叉、变异和替换操作。遗传算法通过多代演化,重复选择、交叉和变异操作,逐步接近最优解。计算过程是迭代的,直到满足终止条件,输出最优解。调整编码方式、选择算子、交叉和变异概率等参数可以优化算法效果。
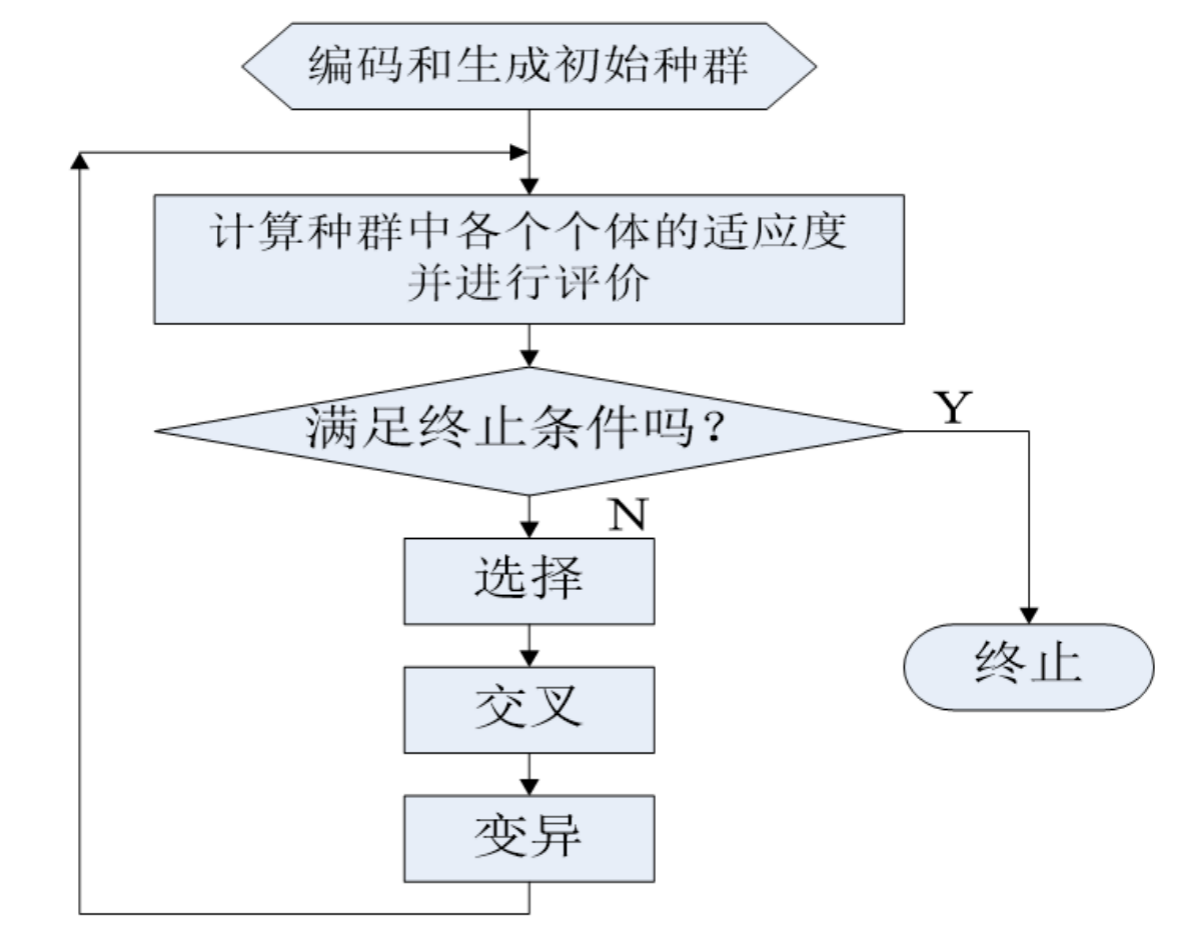
遗传算法的优势在于从多个解出发,在种群中并行搜索,通过进化过程可以避免陷入局部最优,特别适合离散优化问题。可以通过调整编码方式、选择算子、交叉和变异概率等参数来优化算法效果。
第二部分:神经网络
3. 简述反向传播算法的基本原理和计算过程。
反向传播算法是神经网络中高效计算梯度的方法,通过一次前向传播和一次反向传播就能计算所有参数的梯度。
核心思想是利用链式法则:如果y依赖于u,u依赖于x,那么y对x的梯度等于y对u的梯度乘以u对x的梯度。反向传播从输出到输入逐层计算梯度,使用前向传播保存的中间结果。
计算过程分为三个阶段:
- 前向传播,从输入到输出计算函数值,同时保存每一层的输出值、激活值等中间结果(例如计算Sigmoid的梯度时需要用到前向传播时的输出值);
- 反向传播,从输出层开始逐层向前,使用保存的中间结果和链式法则计算梯度;
- 参数更新,使用梯度下降更新参数(新参数等于旧参数减去学习率乘以梯度)。
常见操作的梯度:
- 加法门的梯度直接传递给所有输入;
- 乘法门的梯度需要乘以另一个输入的值;
- ReLU在正区域梯度为1,负区域梯度为0;
- Sigmoid的梯度在输出接近0或1时接近0,导致梯度消失。
反向传播算法的优势在于计算效率高,使训练深层神经网络成为可能。
4. 简述人工神经网络的三个要素及其作用。
人工神经网络的三个基本要素是神经元、连接权重和激活函数,它们共同构成了神经网络的基础架构。
-
神经元是神经网络的基本处理单元,它接收多个输入信号,进行加权求和,然后通过激活函数进行非线性变换,产生输出信号。神经元模拟了生物神经元的功能,是网络进行信息处理的基础。
-
连接权重用于调节神经元之间信号传递的影响程度,它决定了输入信号对神经元输出的影响大小。权重是网络学习的核心参数,通过训练过程(如反向传播算法)不断调整权重,使网络能够学习数据中的模式和规律。
-
激活函数对输入进行非线性变换,生成神经元的输出。激活函数的作用是引入非线性,如果没有激活函数,多层神经网络就等价于单层网络,无法学习和表示复杂的非线性关系。常见的激活函数有Sigmoid、ReLU、Tanh等,不同的激活函数有不同的特性和应用场景。
这三个要素缺一不可:神经元提供处理能力,连接权重决定信息传递的强度,激活函数引入非线性使网络能够处理复杂问题。它们共同使神经网络具备了学习和表示复杂数据模式的能力。
5. 列举3种常用的人工神经元激活函数,画出曲线图。
-
第一种是Sigmoid激活函数,公式为 f ( x ) = 1 1 + e − x f(x) = \frac{1}{1+e^{-x}} f(x)=1+e−x1。Sigmoid常用于二分类问题的输出层,与交叉熵损失函数配合使用。
-
第二种是ReLU激活函数,公式为 f ( x ) = max ( 0 , x ) f(x) = \max(0, x) f(x)=max(0,x)。它的输出范围是 [ 0 , + ∞ ) [0, +\infty) [0,+∞),是一个分段线性函数。
ReLU的变体Leaky ReLU公式为 f ( x ) = max ( 0.1 x , x ) f(x) = \max(0.1x, x) f(x)=max(0.1x,x),在负区域有小的正梯度,可以避免"死亡ReLU"问题。ReLU是目前最常用的激活函数,简单高效,适合深层网络。 -
第三种是Tanh激活函数,公式为 f ( x ) = e x − e − x e x + e − x f(x) = \frac{e^x - e^{-x}}{e^x + e^{-x}} f(x)=ex+e−xex−e−x。它的输出范围是 ( − 1 , 1 ) (-1, 1) (−1,1),也是S形曲线,类似Sigmoid但以0为中心,在 x = 0 x=0 x=0处输出为0。当 x x x很大或很小时,函数也会饱和,梯度接近0,但比Sigmoid的梯度更大,训练更快。
Tanh常用于RNN等循环神经网络,因为输出以0为中心。
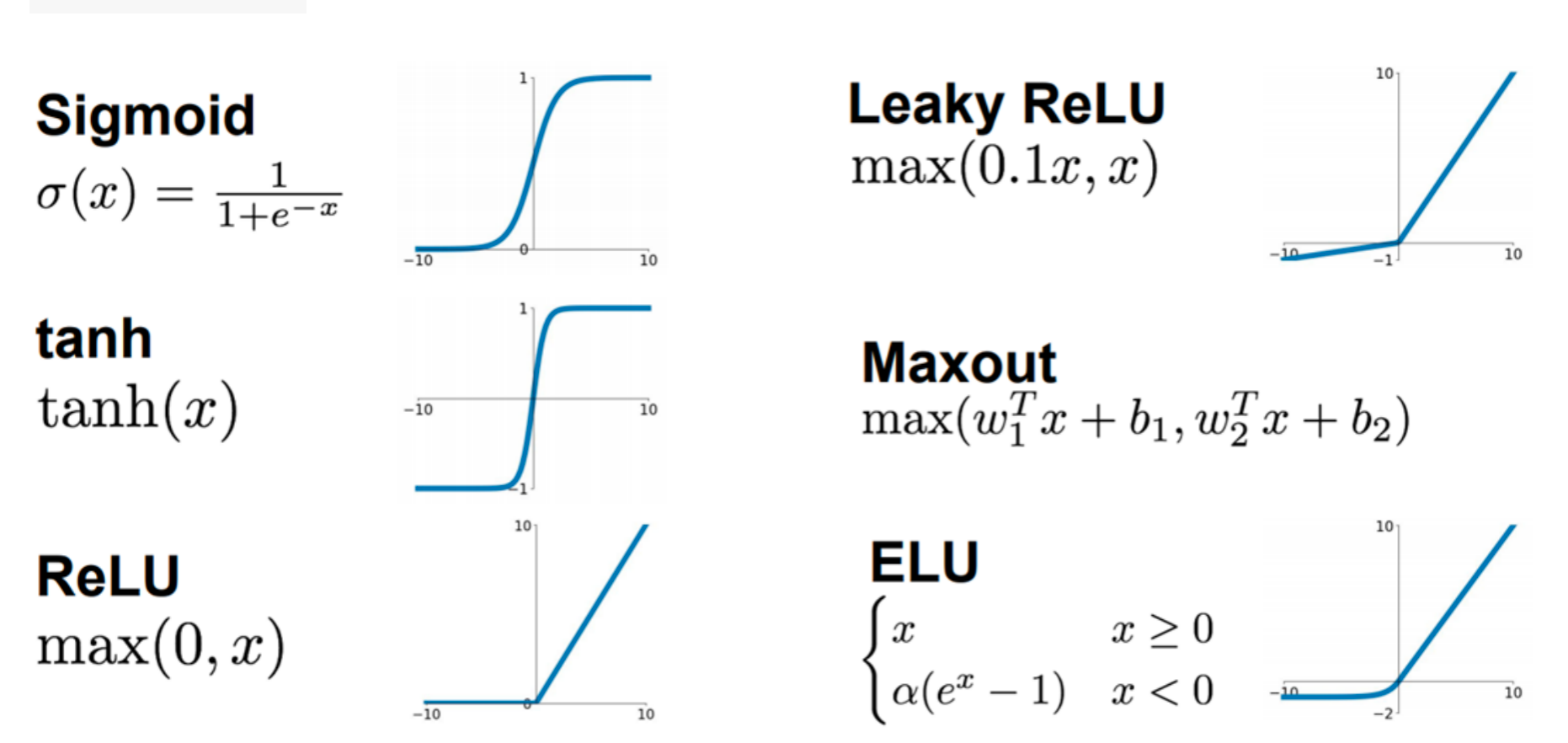
总结来说,Sigmoid适合二分类输出层,ReLU适合大多数隐藏层,Tanh适合需要以0为中心的场合。选择激活函数时要根据网络结构和任务特点来决定。
6. 说明单层感知器模型为何无法模拟逻辑异或(XOR)操作?请设计一个前馈神经网络用于拟合异或函数。
单层感知器只能解决线性可分问题,即可以用一条直线(或超平面)将两类数据分开。XOR问题是线性不可分的,无法用一条直线分开,因此单层感知器无法解决。从数学角度看,单层感知器的决策函数是线性函数(输入的加权和加上偏置,然后通过符号函数),而XOR函数不是线性函数,无法用线性函数表示。
设计:
要解决XOR问题,需要包含隐藏层的前馈神经网络:输入层2个神经元,隐藏层至少2个神经元(使用非线性激活函数),输出层1个神经元。
通过反向传播训练网络参数。核心逻辑:隐藏层通过非线性激活函数将输入空间映射到新特征空间,使XOR问题在新空间中变成线性可分。必须使用非线性激活函数,否则多层网络等价于单层网络,仍无法解决XOR问题。
如果使用线性激活函数,多层网络等价于单层网络,仍然无法解决XOR问题。
7. Transformer注意力原理:简述注意力机制、自注意力机制和多头注意力的基本原理。
Transformer的注意力机制使模型能够动态关注输入的不同部分,实现并行计算并捕获全局依赖关系。
-
注意力机制基于Query-Key-Value框架:计算Query和Key之间的相似度生成注意力权重,对Value进行加权求和得到输出,使模型动态关注输入的不同部分。
-
自注意力机制中 ,序列的每个元素既是Query、Key也是Value,计算序列内部元素之间的注意力。不受距离限制,可并行计算所有位置,每个位置都能访问所有位置的信息,从而捕获全局依赖关系。
-
多头注意力使用多个注意力头,每个头关注不同方面,拼接结果形成更丰富的表示。
Transformer通过编码器和解码器实现:编码器使用多头自注意力提取特征,解码器使用掩码多头自注意力和编码器-解码器注意力生成输出。位置编码保持序列顺序。相比RNN,Transformer通过并行计算解决了并行性和全局依赖的问题。
注意力机制:计算过程:先计算Query和每个Key的相似度,得到注意力权重(表示每个位置的重要程度),然后将每个位置的Value乘以对应的权重,最后把所有加权后的Value加起来得到最终输出。这样重要的位置的信息会在输出中占更大比重,使模型动态关注输入的不同部分。
第三部分:机器学习基础
8. 监督学习和强化学习在做出预测后,都需要某种"反馈信息"来提升学习性能。请分析比较两种学习方法中利用"反馈信息"的不同。
监督学习和强化学习在反馈的形式、时机、内容和作用上都有显著不同。
监督学习的反馈信息是真实标签,每个样本都有明确的正确答案。反馈是即时的,每个样本预测后立即获得反馈,反馈内容是预测值与真实值的差异(损失)。这种反馈直接指导参数更新,使预测值接近真实标签,特点是确定性、即时性和精确性。
强化学习的反馈信息是奖励信号,只表示动作的好坏,而不是标准答案。反馈通常是延迟的,需要执行一系列动作后才能获得奖励。反馈内容是累积奖励,表示整个序列的好坏。这种反馈间接指导策略学习,通过最大化累积奖励学习最优策略,特点是延迟性、稀疏性和不确定性。
主要区别:
反馈性质上,监督学习是确定性反馈,强化学习是奖励性反馈;
反馈时机上,监督学习是即时反馈,强化学习是延迟反馈;
反馈粒度上,监督学习是样本级反馈,强化学习是序列级反馈;
学习目标上,监督学习是拟合标签,强化学习是最大化累积奖励。
9. 简述有监督学习、无监督学习和强化学习三种学习范式的特点和应用场景。
三种学习范式根据数据特点选择合适的学习方式。
有监督学习用标签指导学习,通过比较预测和真实标签计算损失,调整模型参数。主要任务类型是分类和回归。优势是学习目标清晰,效果通常较好。局限是需要大量标注数据,标注成本高。
无监督学习使用无标签数据,让模型自己发现数据中的模式,通过数据本身的特征发现隐藏结构。主要任务类型是聚类、降维、异常检测。优势是不需要标注数据,标注成本低,可以发现数据中的隐藏模式。局限是学习目标不明确,效果难以评估。
强化学习通过与环境交互学习,没有标签,只有奖励信号。通过试错学习,学习最优策略使累积奖励最大。主要任务类型是决策问题,需要在不同状态下选择动作。优势是不需要标注数据,适合决策问题。局限是需要设计奖励函数,训练过程不稳定,需要大量交互数据。
选择原则:有标签数据用有监督学习,无标签数据用无监督学习,需要交互决策用强化学习。
10. 简述机器学习评价指标中准确率、精确率、召回率的定义。
准确率、精确率和召回率是机器学习中常用的评价指标。
- 准确率是分类模型正确预测的样本数占总样本数的比例,衡量模型整体预测准确性。
- 精确率是被模型预测为正例的样本中,真正为正例的比例,衡量模型对正例的准确分类能力。
- 召回率是真正为正例的样本中,被模型预测为正例的比例,衡量模型对正例的覆盖能力。
准确率关注整体预测准确性,精确率关注假正例情况,召回率关注漏报情况。根据具体问题需求,可以选择合适的评价指标或综合考虑这些指标来评估模型性能。
第四部分:推理方法
11. 简述Bayes网络的基本原理,分析Bayes网络不能进行精确推理的原因,举例2种近似推理的方法。
Bayes网络是一种概率图模型,用于表示变量之间的依赖关系。它利用条件概率和贝叶斯定理来描述变量关系,并使用有向无环图表示。
Bayes网络不能进行精确推理的主要原因:
- 首先,复杂的网络结构和强烈的变量依赖关系导致计算复杂性增加,精确推理的计算量呈指数级增长。
- 其次,未完整或缺失的观测数据限制了推理的准确性。为了克服这些问题,常用的近似推理方法包括采样方法和变分推断。
近似推理方法:
- 采样方法通过生成大量样本来近似后验概率分布,适用于大规模网络和连续变量,但需要大量采样才能达到足够精度。常用的方法有马尔可夫链蒙特卡洛。
- 变分推断通过寻找近似的后验概率分布来简化推理问题,常用的方法有变分贝叶斯和期望最大化算法。
这些方法在计算上更高效,广泛应用于复杂的Bayes网络模型,但也引入了一定的误差,需要在计算效率和推理准确性之间进行权衡。
12. 简述命题逻辑、一阶逻辑、模糊逻辑之间的区别和联系。
三种逻辑系统是不同层次的逻辑系统,表达能力依次增强。
命题逻辑只能处理"真"或"假"两种值,表示命题之间的逻辑关系,不能描述具体的事物和属性,适合处理简单的逻辑推理问题。
一阶逻辑引入了个体和谓词,可以描述对象之间的关系和属性,能够表示"对于所有x"、"存在x"等量词,表达能力比命题逻辑更强。命题逻辑是一阶逻辑的特殊情况(当没有量词和谓词时),适合处理需要描述对象和关系的复杂推理问题。
模糊逻辑允许真值在0到1之间连续取值,可以处理模糊性和不确定性问题,进一步扩展了一阶逻辑,适合处理现实世界中模糊、不确定的问题。
区别:表达能力上,命题逻辑 < 一阶逻辑 < 模糊逻辑。真值范围上,命题逻辑和一阶逻辑都是二值逻辑(真/假),模糊逻辑是连续值(0到1)。
联系:它们形成层次关系,命题逻辑是一阶逻辑的特殊情况,一阶逻辑是模糊逻辑的基础。一阶逻辑扩展了命题逻辑的表达能力,模糊逻辑扩展了一阶逻辑处理不确定性的能力。可以根据问题特点选择合适的逻辑系统。



















 1917
1917

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











