




文章目录
一、什么是weaviate
Weaviate 是一个开源的向量数据库(vector database),它能够同时存储数据对象和它们的向量表示。
与传统的关系型数据库不同,Weaviate 支持基于语义相似度的检索(即向量搜索/语义搜索(向量和文本相似的搜索)),可以高效地处理文本、图片等多种类型的数据,并支持结合结构化过滤进行复杂查询。
Weaviate 的主要特点包括:
搜索:
- 高效的向量检索:能够在百万级甚至更大规模的数据集中,毫秒级完成最近邻(Nearest Neighbor)搜索。
- 混合搜索: 结合向量搜索和关键词搜索(文本和向量搜索ing)
- 向量搜索: 基于 HNSW 算法的高效向量索引
- 多媒体支持:支持文本、图片等多种数据类型的向量化和检索。
典型应用场景包括语义搜索、图片搜索、相似性检索、推荐系统、异常检测、数据分类等Weaviate 简介 官方文档。
二、High-Level Architecture
参考:
https://deepwiki.com/search/highlevel-architecture_254cebb0-bc55-4fd7-a374-cfbcaaaaa6ea
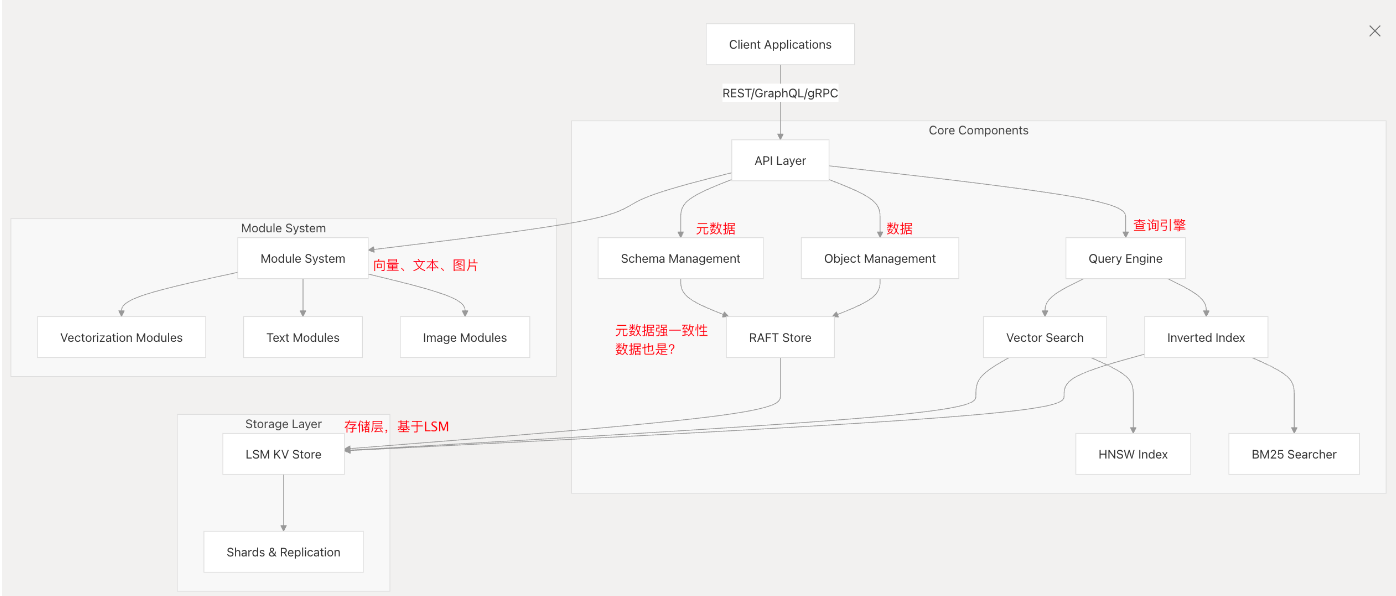
如上架构图体现了 Weaviate 的分层设计:
API 层处理外部接口,Core Components 管理业务逻辑,Extension System 提供可插拔功能,Storage Layer 负责数据持久化。
1. Core Components
| 核心组件 | 描述 |
|---|---|
| API Layer | Weaviate主要入口点,支持REST API(负责设置各种REST处理器,含认证、授权、Schema、对象操作、批量处理、GraphQL接口 )、gRPC API(提供高性能服务,含traverser、认证、schema管理、批量管理功能 )、GraphQL API(提供查询接口,通过traverser解析请求 ) |
| Objects Manager | 管理单个对象的CRUD操作,依赖Schema Manager、DB、Modules和授权器 通过 ShardLike接口实现对象的CRUD操作,如PutObject、ObjectByID、DeleteObject等 |
| Schema Manager | 1. 负责类定义和元数据管理,集群级别通过Indexer接口处理类的增删改查;2. 用例层通过 SchemaManager接口提供强一致性schema操作;负责数据模型管理,与集群服务的Raft协议集成以保证一致性 |
| Cluster Service | 管理分布式协调,使用Raft共识算法 |
2. Storage Layer
| 核心组件 | 描述 |
|---|---|
| LSM KV Store | 每个Shard包含一个,用于持久化对象数据 |
| Vector Indices (HNSW) | Shard支持多个,含主向量索引和命名向量索引 |
| Inverted Indices | 通过属性索引实现,支持文本搜索和过滤功能 |
| Object Storage | 通过LSM - KV存储实现,支持创建不同策略的存储桶 |
3. 组件交互流程
- 请求流程: API Layer → Objects/Batch Manager → DB → Index → Shard → Storage Layer
- 集群协调: Cluster Service 通过 Raft 同步 Schema 变更(元数据通过raft算法)
- 模块集成: Modules Provider 为各组件提供向量化和 AI 功能
- 查询执行: Traverser 协调 DB 和 Explorer 执行复杂查询
三、核心组件
1. API Layer
Weaviate provides multiple API interfaces:
- REST API: Traditional HTTP-based interface for CRUD operations
- GraphQL API: Rich query language with advanced filtering and traversal
- gRPC API: High-performance binary protocol for efficient data transfer
These interfaces expose Weaviate’s functionality for data management, search, and schema operations.
2. Schema Management
The schema system defines the structure of data stored in Weaviate:
- Classes: Define object types (similar to tables in relational databases)
- Properties: Define fields within classes
- Data Types: Support for primitive types and references
- Vector Configurations: Settings for vectorization and indexing
Schema changes are managed through a RAFT consensus algorithm to ensure consistency across distributed deployments.
3. Vector Indexing
Weaviate 使用分层可导航小世界(HNSW)图来实现快速近似最近邻搜索。该算法创建了一个多层图结构,即使对于数百万个向量,也能实现对数时间的相似性搜索。
Weaviate uses Hierarchical Navigable Small World (HNSW) graphs for fast approximate nearest-neighbor search. This algorithm creates a multi-layered graph structure that enables logarithmic-time similarity searches even with millions of vectors.
HNSW 算法核心特性
- 多层图结构:通过在不同层级(从粗到细)建立节点连接,形成 “高速公路” 式的搜索路径。底层包含所有节点,高层为底层的稀疏采样,层级越高节点越少但连接跨度越大。
- 近似搜索:不保证找到绝对精确的最近邻,但能在合理时间内返回足够近似的结果,适合大规模向量数据场景(如数百万至数十亿向量)。
3.1. 查询原理
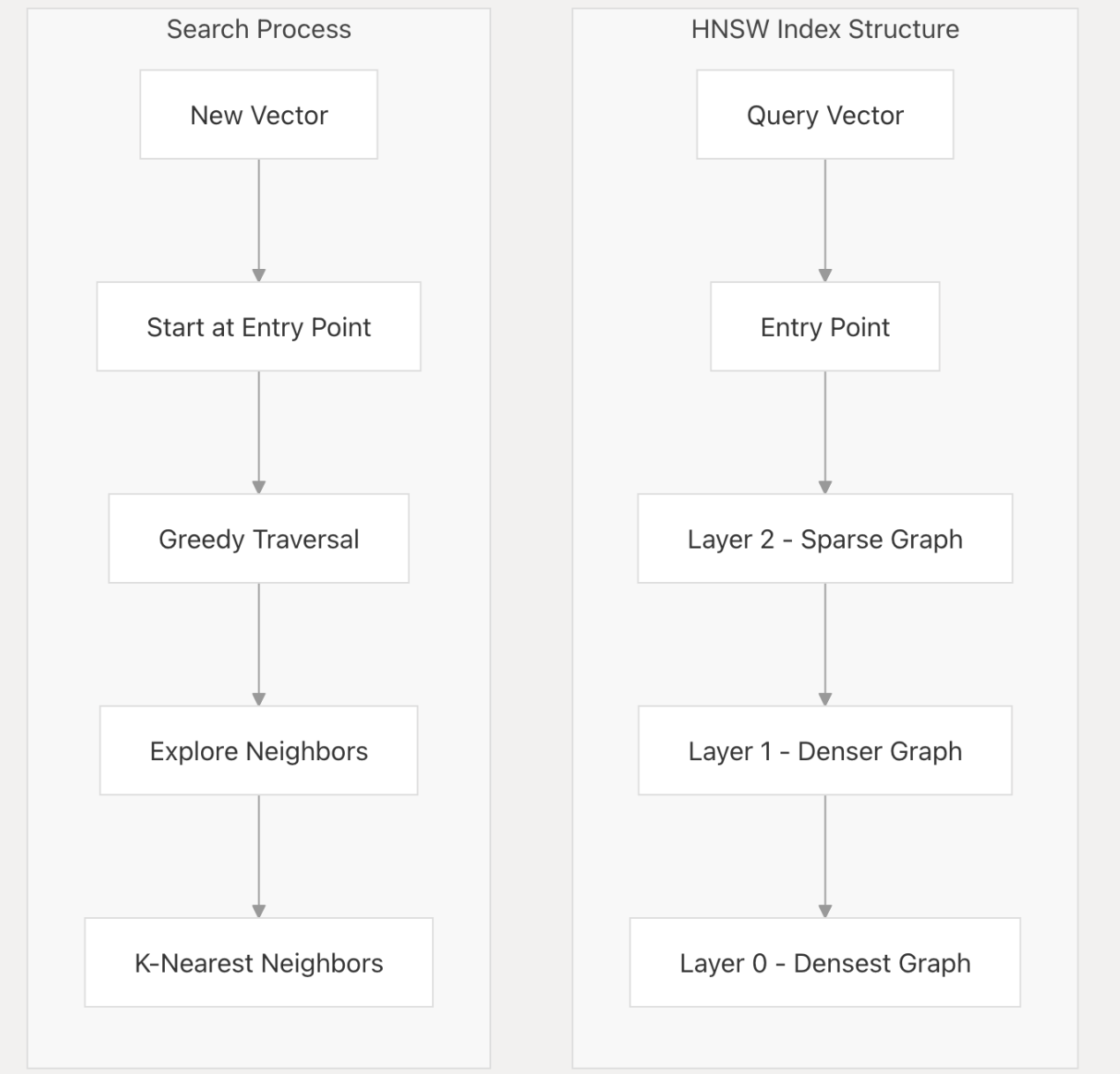
上图图清晰地展示了 HNSW(Hierarchical Navigable Small World,分层可导航小世界) 算法的核心流程和索引结构,分为左右两部分:Search Process(搜索流程)和 HNSW Index Structure(HNSW 索引结构)。
3.2. 左侧:Search Process(搜索流程)
描述新向量(查询向量)如何在 HNSW 中找到最近邻,步骤如下:
- New Vector(新向量)
- 输入:待查询的向量(如用户输入的文本转换的向量、图像特征向量等)。
- 作用:触发一次近似最近邻搜索(Approximate Nearest Neighbor Search)。
- Start at Entry Point(从入口点开始)
- HNSW 会预先确定一个全局入口点(Entry Point),作为搜索的起始节点。
- 作用:避免随机起始导致的低效,确保从“高层”开始快速缩小范围。
- Greedy Traversal(贪心遍历) 策略:从入口点开始,逐层向下,在每一层中“贪心”选择距离查询向量最近(局部最优加速搜索)的邻居节点,快速向目标区域逼近。
- Explore Neighbors(探索邻居)
- 在底层(Layer 0),算法会精细化探索邻居节点,对比更多候选(如何对比),提升结果精度。
- 作用:在高层快速缩小范围后,底层用更密集的连接确保结果质量。
- K-Nearest Neighbors(K 近邻结果)
- 输出:最终找到与查询向量最相似的
K个节点(向量),完成近似最近邻搜索。
3.3. 右侧:HNSW Index Structure(HNSW 索引结构)
描述HNSW 的多层图结构,从查询向量的视角看索引的层次:
- Query Vector(查询向量) :搜索的输入
- Entry Point(入口点) :全局统一的起始节点,所有搜索都从这里进入高层图,确保搜索路径的一致性。
- Layer 2 - Sparse Graph(第 2 层 - 稀疏图) :高层(如 Layer 2):节点少、连接稀疏,跨度大(类似“高速公路”)。 快速跳过大量无关节点,用最少步骤定位到“大致区域”。
- Layer 1 - Denser Graph(第 1 层 - 较密集图) : 中层(如 Layer 1):节点和连接比高层更密集,开始缩小搜索范围。 在高层定位的基础上,进一步逼近目标区域。
- Layer 0 - Densest Graph(第 0 层 - 最密集图) :底层(Layer 0):包含所有原始数据节点,连接最密集。 作用:精细化搜索,确保找到足够近似的最近邻。
3.4. 小结
分层设计的意义:
- 高层(稀疏)负责快速“跳跃”,用最少步骤缩小范围;
- 底层(密集)负责精细化搜索,保证结果精度。
- 这种“先粗后细”的方式,让 HNSW 在百万/亿级向量中仍能高效搜索。
与传统算法的区别:
- 传统 KNN 是“暴力遍历”(逐层对比所有节点),复杂度 (O(n));
- HNSW 用多层图将复杂度降为 O(log n),适合大规模数据。
参数影响:
- 层数、每层连接数(
M)、构建时的搜索范围(efConstruction)等参数,会影响索引大小、构建时间和搜索效率,需根据数据规模调优。
4. Storage System
Weaviate uses an LSM (Log-Structured Merge-tree) key-value store for persistent storage:
- Memtables: In-memory storage for recent writes
- Segment Files: Immutable disk storage
- Compaction: Background process to optimize storage
The storage system is designed for high write throughput and efficient reads, with support for sharding and replication in distributed deployments.
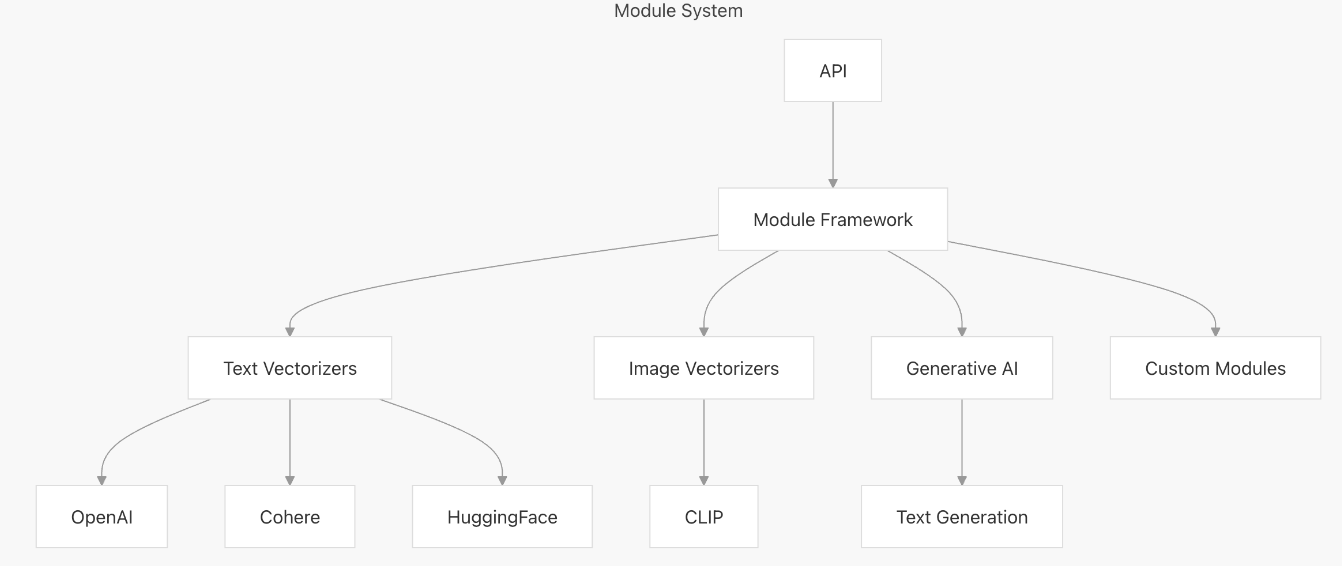
5. Module System
Weaviate’s module system provides a flexible way to extend functionality:
- Vectorizers: Transform raw data into vector embeddings
- Text Modules: Process and analyze text data
- Image Modules: Process and analyze image data
- Custom Modules: Support for user-defined extensions
Modules can be added or configured to tailor Weaviate to specific use cases.



















 2640
2640

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











